[點晴永久免費OA]代碼理解之代碼可讀性:代碼反混淆
當前位置:點晴教程→點晴OA辦公管理信息系統
→『 經驗分享&問題答疑 』
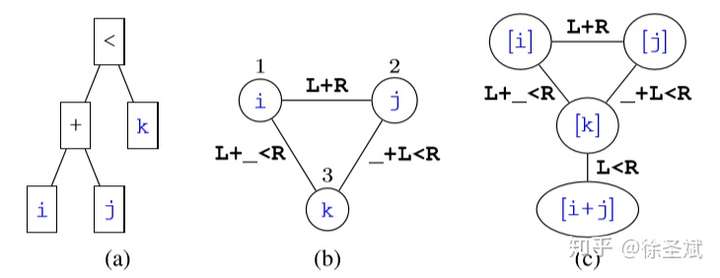
背景代碼反混淆(deobfuscation)和代碼混淆(obfuscation)對應,是其逆過程。維基百科將代碼混淆定義為故意生成人類難以理解的源代碼或機器碼的過程("In software development, obfuscation is the deliberate act of creating source or machine code that is difficult for humans to understand.")。代碼反混淆可以理解為將原本人類難以理解的代碼轉化為簡單的、可理解的、直觀的代碼的過程。 這篇文章主要介紹一下 "Big Code" 在代碼反混淆領域的應用。更具體一點就是介紹一下提出 "JSNice" 和 "Deguard" 的兩篇文章,這兩篇文章雖然已經發表快五年了,但至今沒有文章Follow這兩份工作,因為文章已經將使用 "Big Code" 做代碼命名反混淆做到了極致。后來的人無法在這個問題上推陳出新,脫穎而出。 "Big Code": 代碼托管網站如GitHub上的大量免費可用的高質量代碼被稱為 "Big Code" ,這些數據結合統計推理或深度學習為新興的開發工具的出現提供了契機。 概率圖模型:概率圖模型是用圖來表示變量概率依賴關系的理論,結合概率論與圖論的知識,利用圖來表示與模型有關的變量的聯合概率分布。 問題為了項目的安全,開發者在打包發布項目時會對代碼進行混淆加密,包括但不限于用無意義的短變量去重命名類、變量、方法,以免代碼被輕易破解泄露。另外由于JS腳本主要用于Web開發,對其進行混淆還能壓縮腳本的大小,使得瀏覽器下載、加載更加快速,提升用戶的瀏覽體驗。 這一類通過對類、變量、方法重命名的混淆方案確實能加大其他開發者對代碼的理解難度。其他開發者不干了,為了能方便理解他人混淆后的代碼,學習(抄襲)他人的經驗,針對這一類混淆方法的反混淆方法也應運而生。 下面先展示一下安卓APP的代碼混淆技術: 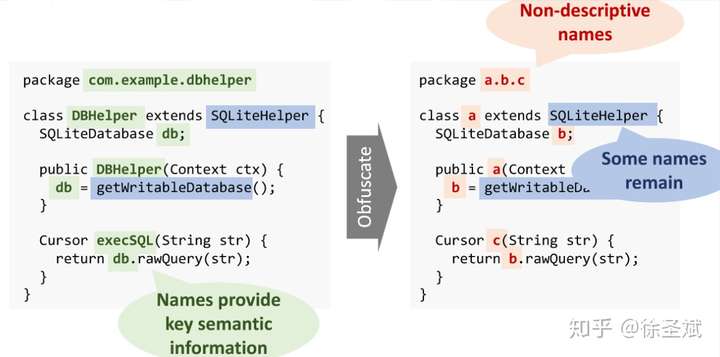 經過混淆的代碼在功能上是沒有變化的,但是去掉了部分名稱中的語義信息。因為種種限制,這類混淆也不可能對所有的名稱都進行替換。上圖中的SQLiteHelper、SQLiteDatabase和Cursor就是一個證明,這些名稱都是安卓API,如果將這些類名混淆會影響代碼的功能。 理論上一個有經驗的安卓開發者可以在這些有限的提示下為所有的名稱找到富含語義的表示,所以反混淆只需要一個有經驗的開發者(有經驗的開發者:???我做錯了什么)。退一步,找不到有經驗的開發者怎么辦,沒關系,GitHub有高質量的各種項目,現訓練一個有經驗的開發者也行。不過為了人道主義,消滅996剝削,程序員表示可以用程序代替人,正好可以用GitHub數據訓練一個程序做這個反混淆嘛!理論存在,實踐開始。 JSNice[1]用程序代替人其實并不簡單,針對上圖中的反混淆問題,程序需要具有“聯想”和“推理”能力,比如從a extends SQLiteHelper這一句中,a應該很可能也是Helper類,結合類中有SQLiteDatabase實例推理出比較符合a的語義的類名是DBHelper。 針對以上兩點,程序需要先有關系的概念,能從一個詞“聯想”到另一個詞,然后還要有推理的能力,能通過約束從幾個候選詞中找到最符合的那個詞。怎么做這個事呢?雖然有很多的未混淆的JS腳本供程序學習,但在反混淆JS腳本時,程序無法理解復雜的JS腳本,所以需要將JS腳本表示成一種可以利用已知屬性推理未知屬性的結構,JSNice采用了概率圖模型。 概率圖模型相比其他學習算法的優勢在于可以利用圖結構將已知信息帶入知識網絡,在使用概率圖模型之前,往往要求圖結構是已知的。現實中我們沒有這些先驗知識,但是有大量的樣本(未混淆代碼)。通過樣本學習出未混淆JS腳本的概率圖就是JSNice的核心。 具體到JSNice,這個工具想要做的是為JS腳本推測名稱(name)和類型(type)。先通過一張圖看看JSNice的推理過程。 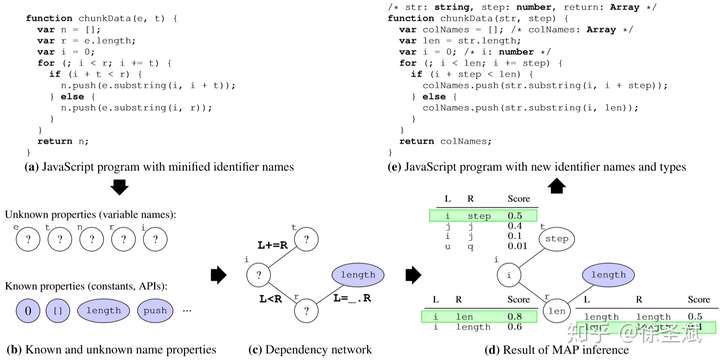 由于JSNice推理名稱和推理類型的過程類似,本文就只闡述推理名稱的過程。 1. 確定已知和未知屬性 JS腳本中包含了各類代碼元素(elements)比如變量,常量,類,方法名,域等。對推理名稱問題,元素的屬性即帶有語義的名稱,一個需要推理名稱的元素,稱其屬性未知。不需要推理名稱的元素其屬性已知。首先需要確定JS腳本中的元素屬性是否已知。很容易看出圖2(a)代碼中屬性已知的元素包括:常量0和[]、feild名稱length和方法名稱push,其他的局部變量如e,t,n,r和i的屬性都是未知的。 將問題泛化,如何判斷任意的JS腳本中的任意元素的屬性是否已知是需要解決的第一個問題。JSNice采用程序分析和人工指定的方式確定元素屬性是否已知,簡單來說,JSNice認為JS腳本中的常量(constants)、對象屬性名(objects properties)、方法名(methods)和全局變量名(global variables)都是屬性已知的元素,而所有的局部變量的屬性都是未知的。值得注意的是JSNice將對象屬性名稱和API名稱直接看做是常量。這個劃分是否合理暫不去討論,但是其確實適用與大部分的JS腳本。有興趣的讀者可以自行研究。 2. 建立依賴網絡 第一步獲取了JS腳本中的所有元素(屬性已知或未知),接下來需要建立元素之間的關系,好方便后續的推理;圖2(c)中簡單的給出了一些關系,比如"var r = e.length"中可以得到(r, length, L=_.R)的關系。 JSNice實際考慮的元素關系十分復雜,主要有三類,這里簡單的進行描述:
 這類關系的形式化定義如下 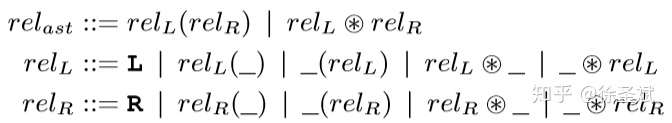
類型推理采用的關系有所不同,但這里也不再詳述,有興趣的讀者直接移步原文。 3. 訓練和推理 現在整理一下對某個JS腳本x進行上述兩步分析能得到什么?得到了一個依賴網絡 現在不去考慮訓練的過程,直接看一下推理過程,JSNice采用貪婪算法,對未知屬性元素遍歷其所有的屬性可能,尋找到使score最大的屬性作為結果。 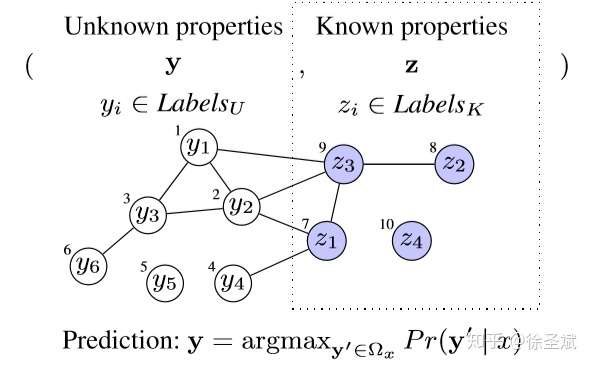 具體的算法如下:  JSNice在具體實現時對算法有所優化,但是其基本思想和主要框架都沒變。其實對比前文提到人進行反混淆時需要的“聯想”和“推理”兩種能力,candidates函數擔負了“聯想”的重任,利用scoreEdges函數對不同的候選屬性計算score并選擇最大score對應屬性的過程就是”推理“。 將圖2的推理部分摘出來看: 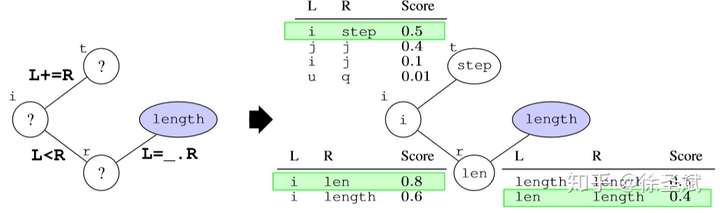 r的candidates有len和length,t的candidates有step、j和q,i的candidates只有i。推理得到的(r、i、t)的屬性是(len、i、step)而不是(length、i、step);是因為前者的綜合score是0.4+0.8+0.5=1.7,而后者的綜合score只有0.5+0.6+0.5=1.6。 那么怎么得到scoreEdges和candidates函數呢? JSNice定義了一個條件隨機場: 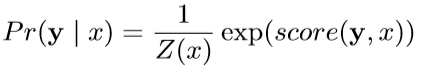 x為給定某個JS腳本,y為未知屬性元素(復數)的任意分配屬性,score為指示屬性y和腳本x的匹配程度的函數,其返回值為實數,值越大越匹配。 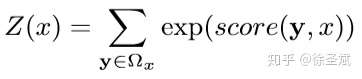 Z是對應JS腳本x的一個懲罰系數,用來保證其Pr和為1 將score定義為k個特征函數的加權平均,得到 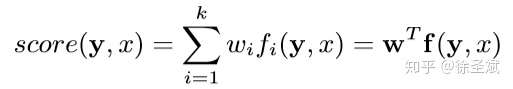 最終條件隨機場的表示形式為: 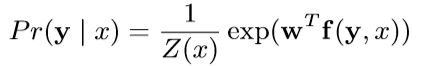 寫到這里,出現了第一個問題,score為k個特征函數的加權平均,如何確定k呢? JSNice是在訓練階段的預處理步驟得到k的,實際上不僅僅這一步不僅獲得了k,還直接定義了k個 pairwise feature functions 往前回一步,本文前面一直說GitHub有未混淆的代碼可供概率圖模型學習,這里定義訓練集 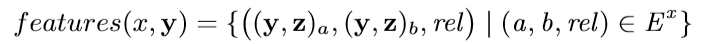 整個訓練集的所有特征集為 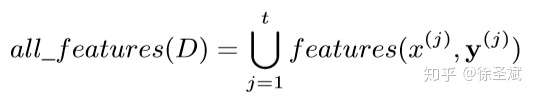 JSNice直接定義pairwise feature functions為每個特征三元組 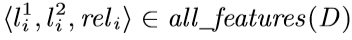 的指示函數: 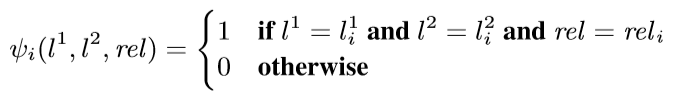 所以訓練集有多少特征三元組,k的值就有多大。 但說了這么多,還是沒有提到scoreEdges和candidates。別急,直接定義 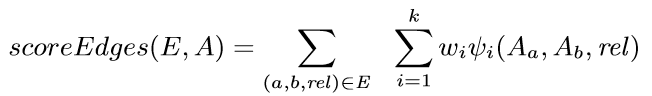 如此把前面的公式都串起來了,整個公式組其實只有 至于candidates,假設現在概率圖模型中的 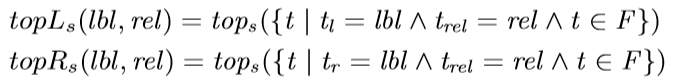 最后: 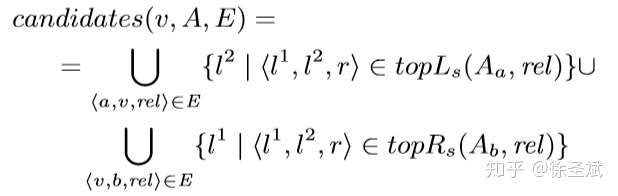 candidates函數其實就是先在 由于筆者本身沒有不研究概率圖模型,所以訓練模型得到 JSNice采用判別式訓練,由于最大似然需要計算 Deguard[2]相對JSNice做的對JS腳本進行反混淆,Deguard對安卓APK做反混淆的難度要大了很多,放在眼前的一個問題就是項目規模,JSNice的應用scope其實是Web上的JS腳本,考慮網站的加載等限制,單個JS腳本必不會太大,而安卓APK不同,由于安卓本身事件驅動的編程方式,一個簡單的安卓APK的復雜度可能就能比得上十分復雜的JS腳本。并且安卓APK的大小一般也沒有限制。 還有一些安卓或者說Java需要的約束是建模時需要考慮的,比如一個Java類中的feilds名稱必須不一樣,一個package中的classes名稱必須不一樣。不滿足這些約束,對APK進行反混淆的結果就失去了其實用性。 考慮到安卓application的復雜性,選取合適的粒度建模是首要的問題,關系過于復雜不利于概率圖模型的學習,關系過于簡略可能導致無法預測準確的屬性,必須有一個權衡。 1. 確定程序元素(圖的節點 要為安卓APK定義一個依賴圖,首先確定圖上的節點,Deguard考慮了APK中的如下元素:
這里沒有考慮Java語言中的泛型機制是因為在編譯過程中會消除泛型,APK本身就是編譯過后的文件。另外和JSNice不一樣的是,Deguard沒有考慮局部變量名和參數名,但考慮了局部變量的類型和參數的類型,一方面減少規模,另一方面就是變量名和參數名本身不在APK中。 2. 確定元素屬性是否已知 這里將元素屬性定義為節點是否被混淆,屬性已知說明節點名稱未被混淆,不需要預測名稱,屬性未知說明節點名稱已被混淆,需要預測名稱。 已知屬性元素包括
剩下的元素都是未知的,需要預測名稱 3. 構建依賴網絡 Deguard用一張圖詳細描述了其用于構建依賴網絡的關系 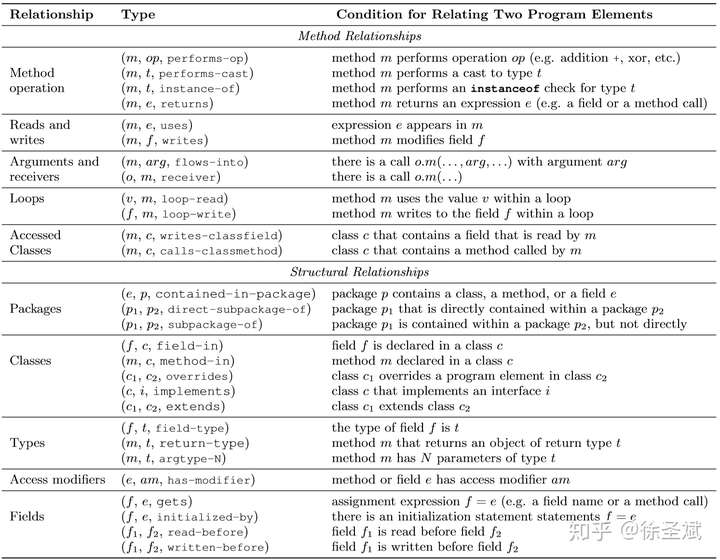 相對JSNice中大部分的關系來自AST,Deguard選擇的關系明顯融合進了人的經驗,更加的抽象。實際上本文的精華也是這一張圖,某種程度上這圖中展現出來了人類對具體問題具體分析的思考,而不是僅僅簡單的復用已有工作提出的各種關系。 剩下的內容比如模型的訓練和推理其實和JSNice差不多,這里不會重復一遍,后續會講不一樣的地方,也就是Deguard如何處理Java程序帶來的關于各種名稱的約束。 Java中的名稱約束還是比較復雜的,這里拿一個例子講一下: 
相等約束(繼承重寫機制)可通過共用節點表示,不等約束也需要明確表示,所以Deguard提出了一個檢測方法名稱不等約束的算法  其他元素,比如類名,Feilds名稱的不等約束比較簡單,直接處理就行。 所有不等約束以集合 注意這個約束只用與預測階段,因為訓練數據(未混淆)本身滿足這些約束。很容易可以把這些約束結合到JSNice的算法1中。 Deguard的概率圖優化算法和JSNice也不一樣,采用的是pseudo likelihood estimation。具體闡述推薦閱讀文章[3]。 值得注意的是,為什么JSNice就沒有Deguard中提到的相等約束和不等約束,筆者個人認為還是由問題和語言特性共同決定,JSNice的名稱預測其實只預測了局部變量,而JS的語言特性導致其本身不需要檢測局部變量的名稱沖突,只有執行結果報錯才會說明程序出錯。也就是說其實JS本身語言特性就沒有這類約束,自然不需要建模。 總結提出JSNice和Deguard的兩篇文章算是基于 "Big Code" 的較早的研究了,這兩個工具現在還在維護并可用(JSNice[4]、Deguard[5])也證明了基于 "Big Code" 的研究和工具確實是可行可信有前途的。 從文章的研究思路來看,基于 "Big Code" 的研究首先需要判斷:"Big Code"能夠做到什么和做出來的東西能不能make sense兩個問題。分享的兩篇文章能夠發表就在于大家相信基于已有開源項目做反混淆這件事是合理的。 另外一個就是找到問題本身和建模并解決問題同等重要甚至更加重要。這兩篇文章其實都是做的一件事,就是做代碼命名推薦。而作者能夠在命名推薦這個大的領域內(領域太大),找到完整程序的代碼命名推薦(難以入手,沒有已知)問題,再進一步縮小Scope到基于部分已知命名的完整程序的代碼命名推薦(可以做,"Big Code"可以支持)這件事,這個范圍內還正好有兩個應用(JS腳本和安卓APK的反混淆)可以支撐研究,真正是十分厲害也比較走運。 結合現在深度學習的風口,其實從應用的角度來看,模型的復雜度和創新度并不重要,還是模型和問題本身的契合度更加重要。 參考
該文章在 2022/6/8 16:48:09 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886


