[轉帖]SQL常用函數整理(帶示例)
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
 :[轉帖]SQL常用函數整理(帶示例) :[轉帖]SQL常用函數整理(帶示例) SQL 常用函數 整理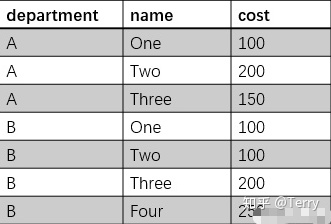 只要思想不滑坡,方法總比困難多. 本文主要記錄日常使用的函數,以筆記的形式不斷補充sql常用函數,部分內容會借鑒大佬的內容,因本文為日常小積累,就不作引用記錄。如有不妥之處請留言,作者會對相應內容進行調整,提前跟各位大佬說聲sorry。同時本文希望可以給有需者帶去幫助。文章中如有錯誤,希望大家多多指導,謝謝··· 什么是SQL數據庫?結構化查詢語言(Structured Query Language)簡稱SQL,是一種數據庫查詢語言。 ···Let's Go···Directory List:一、數據表創建/插入/修改/刪除 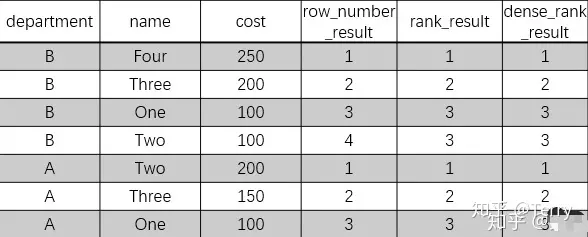 一、數據表創建/插入/修改/刪除1、創建 --創建數據表 create TABLE Persons( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), PRIMARY KEY (P_Id) ); create TABLE Persons( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), CONSTRAINT pk_PersonID PRIMARY KEY (P_Id,LastName) ); --添加主鍵 alter TABLE Persons ADD PRIMARY KEY (P_Id); --添加主鍵【pk_PersonID的值是由兩個列(P_Id和LastName)組成的】 alter TABLE Persons ADD CONSTRAINT pk_PersonID PRIMARY KEY (P_Id,LastName) --撤銷主鍵 alter TABLE Persons drop PRIMARY KEY; alter TABLE Persons drop CONSTRAINT pk_PersonID --添加外鍵 create TABLE Orders( O_Id int NOT NULL, OrderNo int NOT NULL, P_Id int, PRIMARY KEY (O_Id), FOREIGN KEY (P_Id) REFERENCES Persons(P_Id) ); 2、插入 insert INTO Websites (name, url, alexa, country)
VALUES ('百度','https://www.baidu.com/','4','CN');
insert INTO Websites (name, url, country)
VALUES ('stackoverflow', 'http://stackoverflow.com/', 'IND');3、修改/更新 update salaries set salary = case when salary >= 10000 then salary * 0.9 else salary * 1.2 end ; update Websites SET alexa='5000', country='USA' where name='菜鳥教程'; 4、刪除 delete from Websites where name='Facebook' AND country='USA'; --刪除所有數據 delete from table_name; --或 delete * from table_name; 二、窗口函數1、排序函數 row_number / rank / dense_rank row_number() 則在排序相同時不重復,會根據順序排序。  select * ,row_number() over ( partition by department order by cost desc ) as row_number_result ,rank() over ( partition by department order by cost desc) as rank_result ,dense_rank() over (partition by department order by cost desc) as dense_rank_result from table;  2、分組最大值 / 最小值 firs_tvalue / last_value 取的是分組內排序后,截止到當前行第一個/最后一個值 select *, first_value(name) over (PARTITION BY department ORDER BY cost) as min_cost_user, ## 分組取每個組的最小值對應的人 last_value(name) over (PARTITION BY department ORDER BY cost) as max_cost_user ## 分組取每個組的最大值對應的人from table; 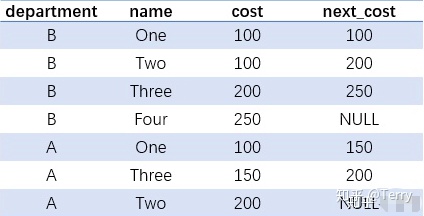 3、累積百分比 cum_dist() over / sum() over --cume_dist() over 返回的是小于等于當前值的行數/分組內總行數,但我倒序排的話,也就是大于等于了; select *, cume_dist() OVER (PARTITION BY department ORDER BY cost desc ) as cum_dist, sum(cost) OVER (PARTITION BY department ORDER BY cost desc )/sum(cost) OVER (PARTITION BY department) as s from table where department = 'A'; --注:當組內出現重復時,累積計算會有所問題,待核驗;  4、錯位函數 lead / lag lead和lag函數,這兩個函數一般用于計算差值,最適用的場景是計算花費時間。 舉個例子,有數據是每個用戶瀏覽網頁的時間記錄,將記錄的時間錯位之后,進 行兩列相減就可以得到每個用戶瀏覽每個網頁實際花費的時間。 select *, lead(cost) over(partition by department order by cost) next_cost from table;  三、日期函數1、日期轉換 : 日期與時間戳之間的轉換  --當你存儲的是日期,希望轉化為UNIX時間戳時,使用unix_timestamp函數,命令格式:unix_timestamp(string date, string pattern) ,表示轉換pattern格式的日期到時間戳;--當你存儲的是時間戳,希望轉化為日期,使用from_unixtime函數,命令格式:from_unixtime(bigint unixtime, [string format]);## 日期轉化為時間戳 ##select unix_timestamp('2020-03-21 17:13:39'):得到 1584782019select unix_timestamp('20200321 13:01:03','yyyyMMdd HH:mm:ss') 得到 1584766863select unix_timestamp('20200321','yyyyMMdd') 得到 1584720000## 時間戳轉化為日期 ##
select from_unixtime (1584782175) 得到 2020-03-21 17:16:15select from_unixtime (1584782175,'yyyyMMdd') 得到 20200321select from_unixtime (1584782175,'yyyy-MM-dd')得到 2020-03-21## 日期和日期之間,也可以通過時間戳來進行轉換 ##select from_unixtime(unix_timestamp('20200321','yyyymmdd'),'yyyy-mm-dd') 得到 2020-03-21select from_unixtime(unix_timestamp('2020-03-21','yyyy-mm-dd'),'yyyymmdd')得到 20200321--注:注意轉換的時間格式要求;2、日期加減 天--維度計算 --date_sub(string startdate, int days)
## 使用date_sub (string startdate, int days)得到開始日期startdate減少days天后的日期##
select date_sub('2012-12-08', 10) 得到 2012-11-28
--date_add(string start date, int days)
## 使用date_add(string startdate, int days)得到開始日期startdate增加days天后的日期 ##
select date_add('2012-12-08', 10) 得到 2012-12-18
--datediff(string enddate, string startdate)
## 使用datediff(string enddate, string startdate)得到 結束日期減去開始日期的天數 ##
select datediff('2012-12-08','2012-05-09') 得到 213月--維度計算 --add_months(d,n); --在某一個日期d上,加上指定的月數n,返回計算后的新日期。d表示日期,n表示要加的月數(n可以為負值) select add_months(sys date,1) from student; 時間差函數timestampdiff--綜合維度計算 --timestampdiff( interval, datetime_1, datetime_2) interval: --毫秒:frac_second --秒 :second --分鐘:minuter --小時:hour --天 :day --星期:week --月 :month --季度:quarter --年 :year --相差1天 select TIMESTAMPDIFF(DAY, '2018-03-20 23:59:00', '2015-03-22 00:00:00'); --相差49小時 select TIMESTAMPDIFF(HOUR, '2018-03-20 09:00:00', '2018-03-22 10:00:00'); --相差2940分鐘 select TIMESTAMPDIFF(MINUTE, '2018-03-20 09:00:00', '2018-03-22 10:00:00'); --相差176400秒 select TIMESTAMPDIFF(SECOND, '2018-03-20 09:00:00', '2018-03-22 10:00:00'); 3、日期提取 日期(2020-03-21 17:13:39)怎么轉換為想要的格式(2020-03-21) --方法:可以直接使用to_date函數,也可以使用字符串提取函數。
select to_date('2020-03-21 17:13:39') 得到 2020-03-21
select substr('2020-03-21 17:13:39',1,10) 得到 2020-03-21獲取日期年份/月份/幾號/當前日期 year() --獲取日期年份 month() --獲取日期月份 day() --獲取日期幾號 now() --獲取當前日期 last_day(datetime) --返回指定日期當前月的最后一天; select last_day(create_time) from student; extract(unit from date) select EXTRACT(YEAR from OrderDate) AS OrderYear, EXTRACT(MONTH from OrderDate) AS OrderMonth, EXTRACT(DAY from OrderDate) AS OrderDay from Orders; --date 參數是合法的日期表達式。unit 參數可以是下列的值: --Unit 值: MICROSECOND SECOND MINUTE HOUR DAY WEEK MONTH QUARTER YEAR SECOND_MICROSECOND MINUTE_MICROSECOND MINUTE_SECOND HOUR_MICROSECOND HOUR_SECOND HOUR_MINUTE DAY_MICROSECOND DAY_SECOND DAY_MINUTE DAY_HOUR YEAR_MONTH 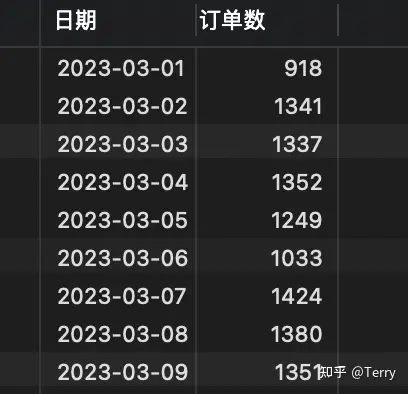 也可以通過日期命令格式date_format()提取 4、日期命令格式 date_format(string datetime, interval) ---interval: %y:表示年(兩位數),例如: 17 年。 %Y:表示4位數中的年,例如: 2017年 %m:表示月(1-12) %d: 表示月中的天 %H: 小時(0-23) %i: 分鐘 (0-59) %s: 秒 (0-59) --常用格式:'%Y-%m-%d %H:%i:%s' 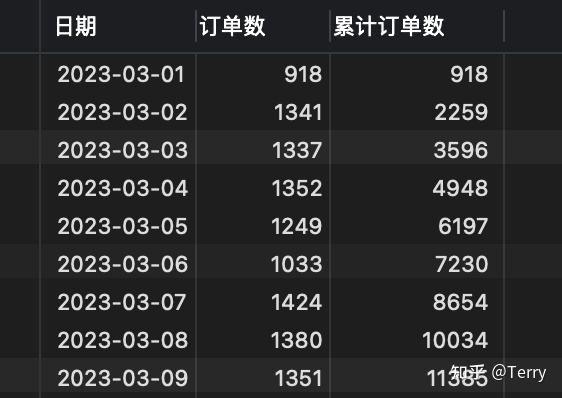 5、mysql 獲取日期 (1)獲取當前日期select curdate();(2)獲取本月最后一天select last_day(curdate());(3)獲取本月第一天select date_add(curdate(), interval - day(curdate()) + 1 day);(4)獲取下個月的第一天select date_add(curdate() - day(curdate()) + 1, interval 1 month);(5)獲取當前月的天數select datediff(date_add(curdate() - day(curdate()) + 1, interval 1 month), date_add(curdate(), interval - day(curdate()) + 1 day)); 四、字符串函數1、字符串提取 substr/substring函數 --使用substr/substring (string A, int start)返回字符串A從start位置到結尾的字符串##
select substring('abcde', 3) 得到 cde
--使用substring(string A, int start, int len)返回字符串A從start位置開始,長度為len的字符串
select substring('abcde', 3,2) 得到 cd2、字符串拼接 concat/concat_ws函數 --使用concat(string A, string B) 返回字符串AB的拼接結果,可以多個字符串進行拼接
select concat('abc', 'def','gh') 得到abcdefgh
--使用concat_ws(string X, stringA, string B) 返回字符串A和B由X拼接的結果
select concat_ws(',', 'abc', 'def', 'gh') 得到 abc,def,gh3、字符串常見處理函數:length/trim/lower/upper --使用length(string A)返回字符串A的長度
select length('abcedfg') 得到 7
--使用trim(string A) 去除字符串兩邊的空格
select trim(' abc ') 得到 'abc'
--使用lower(string A)/ lcase(string A)返回字符串的小寫形式,常用于不確定原始字段是否統一為大小寫
select lower('abSEd') 得到 absed
--使用upper(string A)/ ucase(string A)返回字符串的大寫形式,常用于不確定原始字段是否統一為大小寫
select upper('abSEd') 得到 ABSED4、不同格式數據的轉換:cast --bigint轉換為字符串 select cast(A as string) as A; 5、正則表達式 regexp_extract 提取 / regexp_replace 替換 --regexp_extract(string subject, string pattern, int index)
--將字符串subject按照pattern正則表達式的規則拆分,返回index指定的字符
select regexp_extract('foothebar', 'foo(.*?)(bar)', 1) 得到 the
--regexp_replace(string A, string B, string C)
--將字符串A中的符合java正則表達式B的部分替換為C
select regexp_replace('foobar', 'oo|ar', '') 得到 fb6、字符串解析 get_json_object --get_json_object(string json_string, string path)
--解析json的字符串json_string,返回path指定的內容
select get_json_object(
{"from_remain_count":420,"reason":"collect","to_remain_count":0},
'$.from_remain_count'
) 得到 420五、sql實現歸遞累加目標:由下表1的到表2 ⚠️ 使用時注意sql類型,選擇合適方案實現目標結果!-- 方案一:支持mysqlset @sum := 0;select p1.ship_day as '日期' ,p1.order_cnt as '訂單數' ,(@sum := @sum + p1.order_cnt) as '累計訂單數'from( select left(a.ship_day, 10) as ship_day ,count(a.order_no) as order_cnt from order_table as a GROUP BY left(a.ship_day, 10) ORDER BY left(a.ship_day, 10) asc ) as p1;-- 方案二:(子查詢)select a.date, (select sum(a.num) summary from test b where b.date <=a.date) as summaryfrom test a group by date;-- 方案三:(笛卡爾積)【推薦使用】select b.date ,sum(a.num) from test a,test b where a.date<=b.date group by b.date;-- 方案四:(窗口函數)【不支持mysql】select date ,sum(num) over(partition by [group] order by date) summary from test;   六、其他常用函數1、coalesce函數 用途: --當success_cnt 為null值的時候,將返回1,否則將返回success_cnt的真實值。 select coalesce(success_cnt, 1) from tableA; --當success_cnt不為null,那么無論period是否為null,都將返回success_cnt的真實值(因為success_cnt是第一個參數), --當success_cnt為null,而period不為null的時候,返回period的真實值。 --只有當success_cnt和period均為null的時候,將返回1。 select coalesce(success_cnt,period,1) from tableA; 2、規定返回條數 top/limit ---top select TOP 50 PERCENT * from Websites; --前5行 select top 5 * from table --后5行 select top 5 * from table order by id desc --desc 表示降序排列 asc 表示升序 ---limit select * from Websites LIMIT 2; select * from Websites LIMIT 2,5; 3、通配符 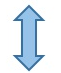 4、行列轉換 行轉列函數 pivot / case when 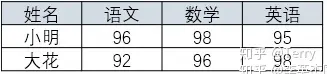 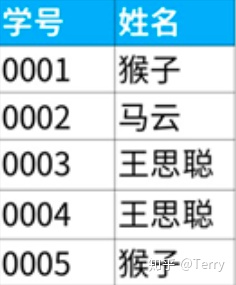  --pivot select * from student PIVOT (SUM(score) FOR subject IN (語文, 數學, 英語) ); --case when select name, MAX( CASE WHEN subject='語文' THEN score ELSE 0 END) AS "語文", MAX( CASE WHEN subject='數學' THEN score ELSE 0 END) AS "數學", MAX( CASE WHEN subject='英語' THEN score ELSE 0 END) AS "英語" from student GROUP BY name; 列轉行 unpivot / case when --unpivot
select *
from student1
UNPIVOT (score FOR subject IN ("語文","數學","英語")
);
--case when
select
NAME,
'語文' AS subject ,
MAX("語文") AS score
from student1 GROUP BY NAME
union
select
NAME,
'數學' AS subject ,
MAX("數學") AS score
from student1 GROUP BY NAME
union
select
NAME,
'英語' AS subject ,
MAX("英語") AS score
from student1 GROUP BY NAME注:考慮了下,本文主要記錄有“價值型”函數為主,其他函數可查看以下鏈接: 七、性能優化1、能寫在 where 子句里的條件不要寫在 HAVING 子句里 --下列 SQL 語句返回的結果是一樣的: -- 聚合后使用 HAVING 子句過濾 select sale_date, SUM(quantity) from SalesHistory GROUP BY sale_date HAVING sale_date = '2007-10-01'; -- 聚合前使用 where 子句過濾 select sale_date, SUM(quantity) from SalesHistory where sale_date = '2007-10-01' GROUP BY sale_date; --使用第二條語句效率更高,原因主要有兩點 --1、使用 GROUP BY 子句進行聚合時會進行排序,如果事先通過 where 子句能篩選出一部分行,能減輕排序的負擔; --2、在 where 子句中可以使用索引,而 HAVING 子句是針對聚合后生成的視頻進行篩選的,但很多時候聚合后生成的視圖并沒有保留原表的索引結構; 2、EXISTS 代替 IN -- 慢 select * from Class_A where id IN (select id from CLASS_B); -- 快 select * from Class_A A where EXISTS (select * from Class_B B where A.id = B.id); --為啥使用 EXISTS 的 SQL 運行更快呢,有兩個原因: --1、可以`用到索引,如果連接列 (id) 上建立了索引,那么查詢 Class_B 時不用查實際的表,只需查索引就可以了。 --2、如果使用 EXISTS,那么只要查到一行數據滿足條件就會終止查詢, 不用像使用 IN 時一樣掃描全表。在這一點上 NOT EXISTS 也一樣。 --另外如果 IN 后面如果跟著的是子查詢,由于 SQL 會先執行 IN 后面的子查詢,會將子查詢的結果保存在一張臨時的工作表里(內聯視圖), --然后掃描整個視圖,顯然掃描整個視圖這個工作很多時候是非常耗時的,而用 EXISTS 不會生成臨時表。 3、盡量避免使用否定形式 否定形式有哪些? <> != NOT IN 為什么要避免使用否定形式 --否定形式語句會導致對全表掃描 --錯誤寫法 select * from student where price <>100; --正確寫法 select * from student where price < 100 or price > 100; 4、通過having減少使用中間表 --復雜寫法:以下寫法會產生臨時表 a; select * from( select sale_date ,max(price) as max_price from sale_table group by sale_date) as a where a.max_price >= 10; --優化寫法 select sale_date ,max(price) as max_prcie from sale_table group by sale_date having max(price) >= 10; 5、多字段使用in謂詞,可匯總一處 --【此處有點高級,作者本人也沒有徹底吸收】 select id ,state ,city from Addresses1 as A1 where state IN (select state from Addresses2 as A2 where A1.id = A2.id) AND city IN (select city from Addresses2 as A2 where A1.id = A2.id); --優化寫法:以上寫法產生了兩張臨時表 select * from Addresses1 as A1 where id || state || city IN (select id || state|| city from Addresses2 A2); 七、案例題:題目1: 查找重復數據學生名字【or 查找重復出現n次的數據】 select a.name from student as a group by a.name having count(a.name) > 1; 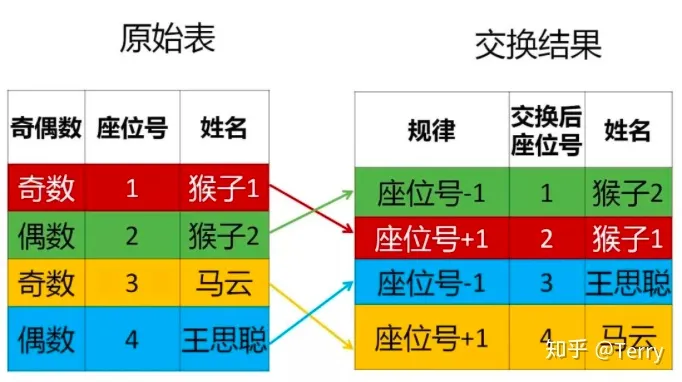 題目2: 找出語文課中成績第二高的學生成績。如果不存在第二高成績的學生,那么查詢應返回 null 知識點: 1、limit x,y: 分句表示查詢結果跳過 x 條數據,讀取前 y 條數據; select ifnull( (select distinct 成績 from 成績表 where 課程='語文' order by 課程,成績 desc limit 1,1),null ) as '第二高的學生成績'; 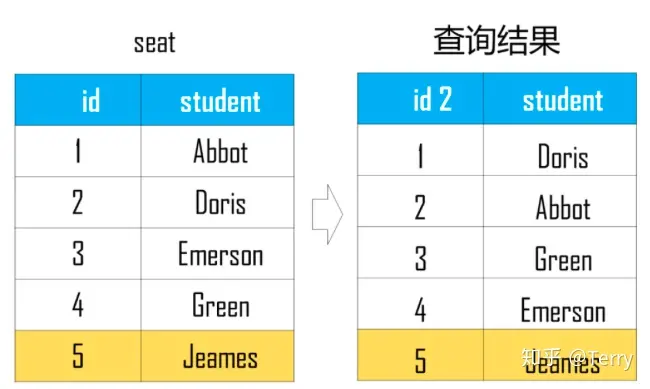 題目3: 改變相鄰兩個學生的座位號 1、當總人數為偶數時: 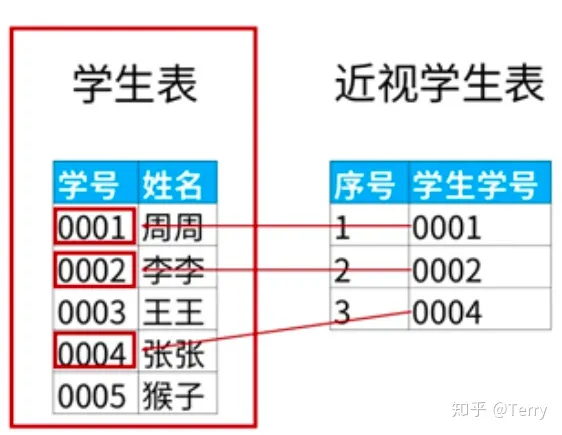 case when mod(座位號, 2) != 0 then 座位號 + 1 when mod(座位號, 2) = 0 then 座位號 - 1 end as '交換后座位號' 2、當座位號是奇數時: 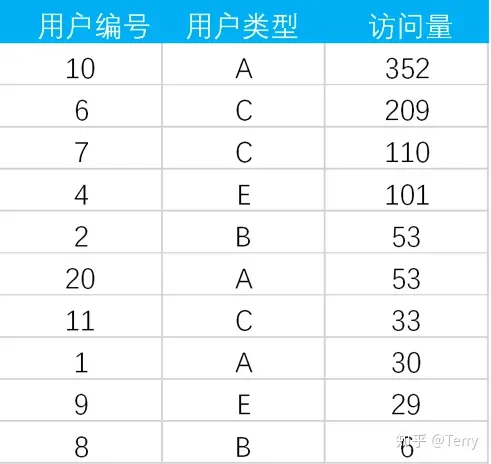 select (case # 當座位號是奇數并且不是不是最后一個座位號時 when mod(id, 2) != 0 and counts!= id then id + 1 # 當座位號是奇數并且是最后一個座位號時,座位號不變 when mod(id, 2) != 0 and counts = id then id # 當座位號是偶數時 else id - 1 end) as id2,studentfrom seat,(select count(*) as counts from seat); 題目4: 如何查詢不在表里的數據 select a.姓名 as 不近視的學生名單 from 學生表 as a left join 近視學生表 as b on a.學號=b.學生學號 where b.序號 is null; 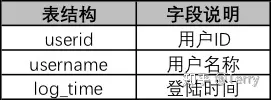 題目5:用戶訪問次數表,列名包括用戶編號、用戶類型、訪問量。要求在剔除訪問次數前20%的用戶后,每類用戶的平均訪問次數  【解題思路】使用邏輯樹分析方法可以把這個復雜的問題拆解為3個子問題: select 用戶類型,avg(訪問量) from (select * from (select *, row_number() over(order by 訪問量 desc) as 排名 from 用戶訪問次數表) as a where 排名 > (select max(排名) from a) * 0.2) as b group by 用戶類型; 題目6:連續N天登陸 解題思路: 案例: 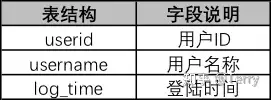  select # 第四步 # 1、計算根據用戶id和新的日期,進行計算,如果計數結果大于等于N,則N天連續登陸 d.user_id ,d.user_name ,d.cal_date from( # 第三步 # 1、日期 減去 排序結果【邏輯:日期減去天數得到新的日期,對新的日期計數,如果計數結果大于等于N,則N天連續登陸】 select c.user_id ,c.user_name ,date_sub(c.log_data, c.rank) as cal_date from( # 第二步 # 1、對每個用戶根據日期進行排序 select b.user_id ,b.user_name ,b.log_data ,row_number() over (PARTITION by b.user_id order by b.log_data) as rank from( # 第一步 # 1、提取時間段在8-22點之間的數據; # 2、日期從 2020-10-25 開始; # 3、數據去重,根據用戶對日期去重 select DISTINCT user_id, user_name, to_date(log_time) as log_data from B as a where extract(HOUR from a.log_time) between 8 and 22 and to_date(a.log_time) > '2020-10-24' ) as b ) as c ) as d group by d.user_id, d.cal_date having count(*) >= 7; 題目7:有一場籃球賽,參賽雙方是A隊和B隊,場邊記錄員記錄下了每次得分的詳細信息: team:隊名 1)輸出每一次的比分的反超時刻,以及對應的完成反超的球員姓名 #第一步:計算每個時間點A、B兩支隊伍的得分情況,如果沒有得分,就顯示為0;【考點:coalesce函數】 #第二步:計算每個時間點A、B兩隊分別累計得分;【考點:sum() over (partition ```order by ```)】 #第三步:計算每個時刻兩隊的分差;【考點:lead函數】 #第四步:當前時刻的 累計分差 與 下一個時刻的 累積分差 相乘,相等結果小于等于0時,則為比分反超時刻;同時通過兩隊的累積比分相同時刻;【考點:篩選思路】 select z.score_time ,z.name from( #第三步:計算每個時刻兩隊的分差; select * ,a_sum_score2-b_sum_score2 as score_gap ,lead(a_sum_score2-b_sum_score2)over(order by score_time) as last_score_gap from( #第二步:計算每個時間點A、B兩隊分別累計得分 select team ,number ,name ,score_time ,A_score ,B_score ,sum(A_score) over (order by score_time) a_sum_score2 --計算每個時點A隊的累計得分 ,sum(b_score) over (order by score_time) b_sum_score2 --計算每個時點B隊的累計得分 from( #第一步:計算每個時間點A、B兩支隊伍的得分情況,如果沒有得分,就顯示為0; select team ,number ,name ,score_time ,coalesce(case when team='A' then score end,0) as A_score --如果某個得分時點B隊得分了,A隊沒有得分,那么A對在這個時點的得分置為0 ,coalesce(case when team='B' then score end,0) as B_score --如果某個得分時點A隊得分了,B隊沒有得分,那么B對在這個時點的得分置為0 from test.basketball_game_score_detail ORDER BY score_time ) as x ) as y ) as z where z.score_gap*last_score_gap<=0 and a_sum_score2<>b_sum_score2; --排除得分相等的時點,這些時點肯定不考慮 2)輸出連續三次或以上得分的球員姓名,以及那一撥連續得分的數值 【以下方案個人覺得復雜了,期望有梗簡單解析思路輸出的朋友給予建議】 #第一步:根據時間進行所有人排序 #第二步: #(1)對每個球員根據時間進行排序 #(2)所有人排序結果 減去 每個球員根據時間排序結果 得到兩者排序差,如果排序差結果相同,則說明是連續的,通過having count() >= N,計算得到連續N次得分的球員 #第三步:通過內連接篩選相關信息 select b.name ,b.score from( #第三步:通過內連接篩選相關信息 select * ,(rank - row_number() over(partition by a.name order by a.score_time)) as rank_diff from( #第一步:根據時間進行所有人排序 select * ,row_number() over(order by score_time) as 'rank' from test.basketball_game_score_detail ) as a ) as b inner join( select b.name ,b.rank_diff from( #第二步: #(1)對每個球員根據時間進行排序 #(2)所有人排序結果 減去 每個球員根據時間排序結果 得到兩者排序差 select * ,(rank - row_number() over(partition by a.name order by a.score_time)) as rank_diff from( #第一步:根據時間進行所有人排序 select * ,row_number() over(order by score_time) as 'rank' from test.basketball_game_score_detail ) as a ) as b group by b.name, b.rank_diff having count(b.rank_diff) >= 3 ) as c on b.name = c.name and b.rank_diff = c.rank_diff; 注:本文未對mysql、sql sever、hive sql、odps sql等進行歸納!該文章在 2023/6/2 15:23:34 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886


