[點(diǎn)晴永久免費(fèi)OA]我們?yōu)槭裁匆謳旆直恚?/h3>
前言
1. 什么是分庫分表分庫:就是一個數(shù)據(jù)庫分成多個數(shù)據(jù)庫,部署到不同機(jī)器。 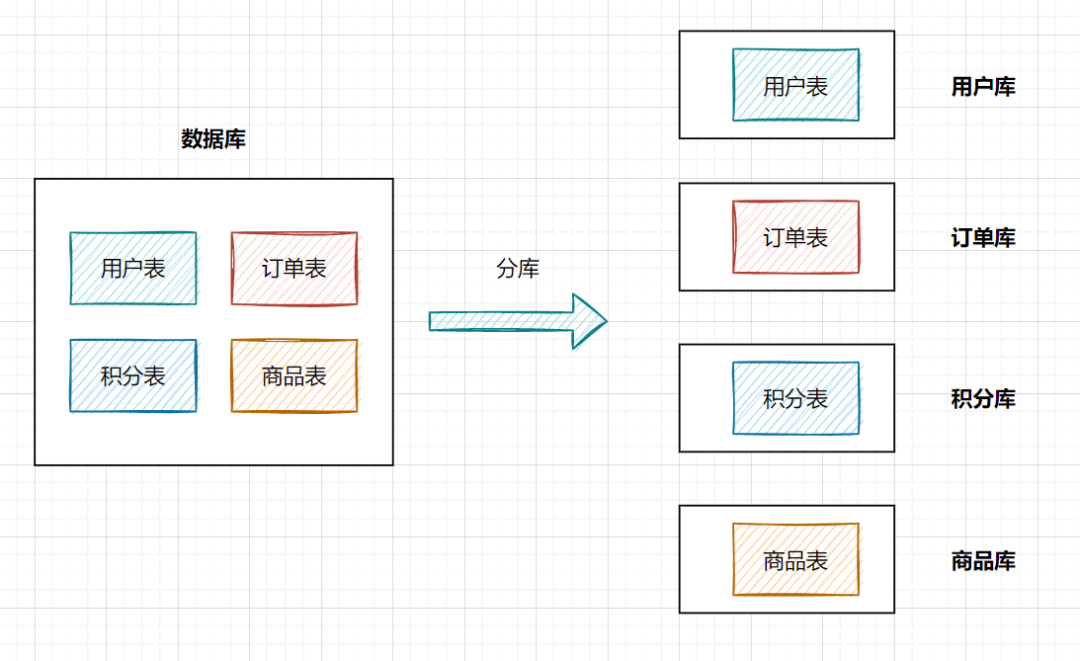 分表:就是一個數(shù)據(jù)庫表分成多個表。 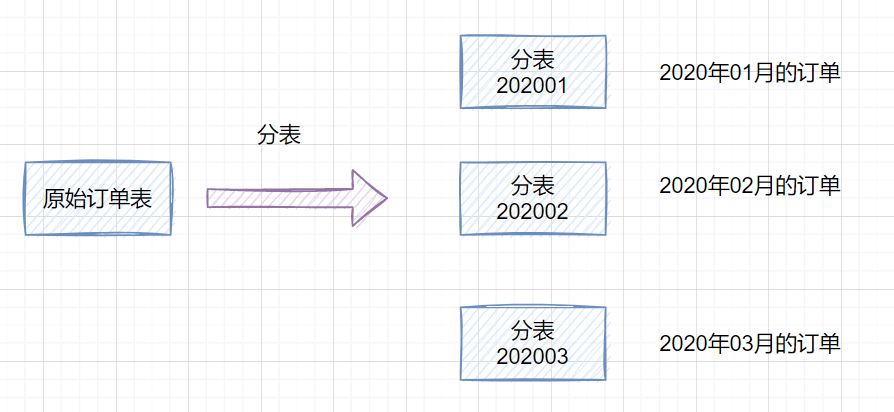 2. 為什么需要分庫分表2.1 為什么需要分庫呢?如果業(yè)務(wù)量劇增,數(shù)據(jù)庫可能會出現(xiàn)性能瓶頸,這時候我們就需要考慮拆分?jǐn)?shù)據(jù)庫。從這幾方面來看:
業(yè)務(wù)量劇增,MySQL單機(jī)磁盤容量會撐爆,拆成多個數(shù)據(jù)庫,磁盤使用率大大降低。
我們知道數(shù)據(jù)庫連接是有限的。在高并發(fā)的場景下,大量請求訪問數(shù)據(jù)庫,MySQL單機(jī)是扛不住的!當(dāng)前非常火的微服務(wù)架構(gòu)出現(xiàn),就是為了應(yīng)對高并發(fā)。它把訂單、用戶、商品等不同模塊,拆分成多個應(yīng)用,并且把單個數(shù)據(jù)庫也拆分成多個不同功能模塊的數(shù)據(jù)庫(訂單庫、用戶庫、商品庫),以分擔(dān)讀寫壓力。 2.2 為什么需要分表?數(shù)據(jù)量太大的話,SQL的查詢就會變慢。如果一個查詢SQL沒命中索引,千百萬數(shù)據(jù)量級別的表可能會拖垮整個數(shù)據(jù)庫。 即使SQL命中了索引,如果表的數(shù)據(jù)量超過一千萬的話,查詢也是會明顯變慢的。這是因?yàn)樗饕话闶荁+樹結(jié)構(gòu),數(shù)據(jù)千萬級別的話,B+樹的高度會增高,查詢就變慢啦。 小伙伴們是否還記得,MySQL的B+樹的高度怎么計(jì)算的呢? 順便復(fù)習(xí)一下吧 InnoDB存儲引擎最小儲存單元是頁,一頁大小就是16k。B+樹葉子存的是數(shù)據(jù),內(nèi)部節(jié)點(diǎn)存的是鍵值+指針。索引組織表通過非葉子節(jié)點(diǎn)的二分查找法以及指針確定數(shù)據(jù)在哪個頁中,進(jìn)而再去數(shù)據(jù)頁中找到需要的數(shù)據(jù),B+樹結(jié)構(gòu)圖如下: 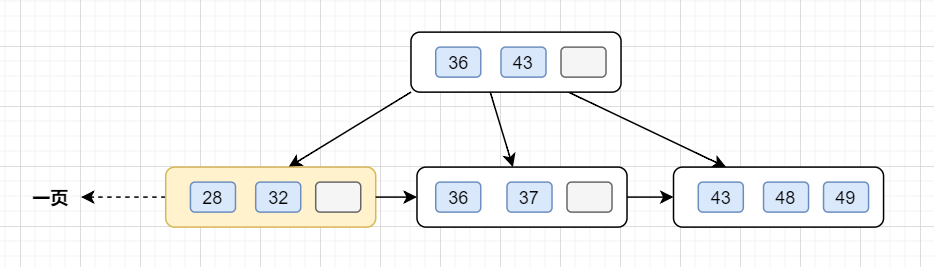 假設(shè)B+樹的高度為2的話,即有一個根結(jié)點(diǎn)和若干個葉子結(jié)點(diǎn)。這棵B+樹的存放總記錄數(shù)為=根結(jié)點(diǎn)指針數(shù)*單個葉子節(jié)點(diǎn)記錄行數(shù)。
因此,一棵高度為2的B+樹,能存放 因此單表數(shù)據(jù)量太大,SQL查詢會變慢,所以就需要考慮分表啦。 3. 如何分庫分表3.1 垂直拆分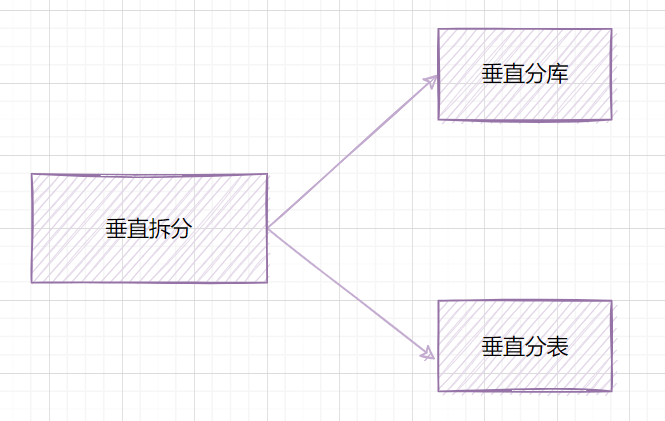 3.1.1 垂直分庫在業(yè)務(wù)發(fā)展初期,業(yè)務(wù)功能模塊比較少,為了快速上線和迭代,往往采用單個數(shù)據(jù)庫來保存數(shù)據(jù)。數(shù)據(jù)庫架構(gòu)如下: 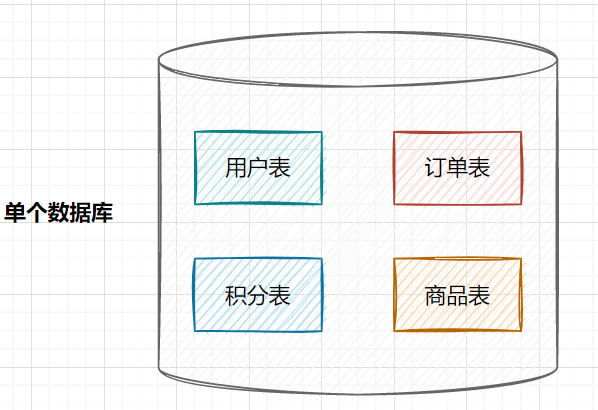 但是隨著業(yè)務(wù)蒸蒸日上,系統(tǒng)功能逐漸完善。這時候,可以按照系統(tǒng)中的不同業(yè)務(wù)進(jìn)行拆分,比如拆分成用戶庫、訂單庫、積分庫、商品庫,把它們部署在不同的數(shù)據(jù)庫服務(wù)器,這就是垂直分庫。 垂直分庫,將原來一個單數(shù)據(jù)庫的壓力分擔(dān)到不同的數(shù)據(jù)庫,可以很好應(yīng)對高并發(fā)場景。數(shù)據(jù)庫垂直拆分后的架構(gòu)如下: 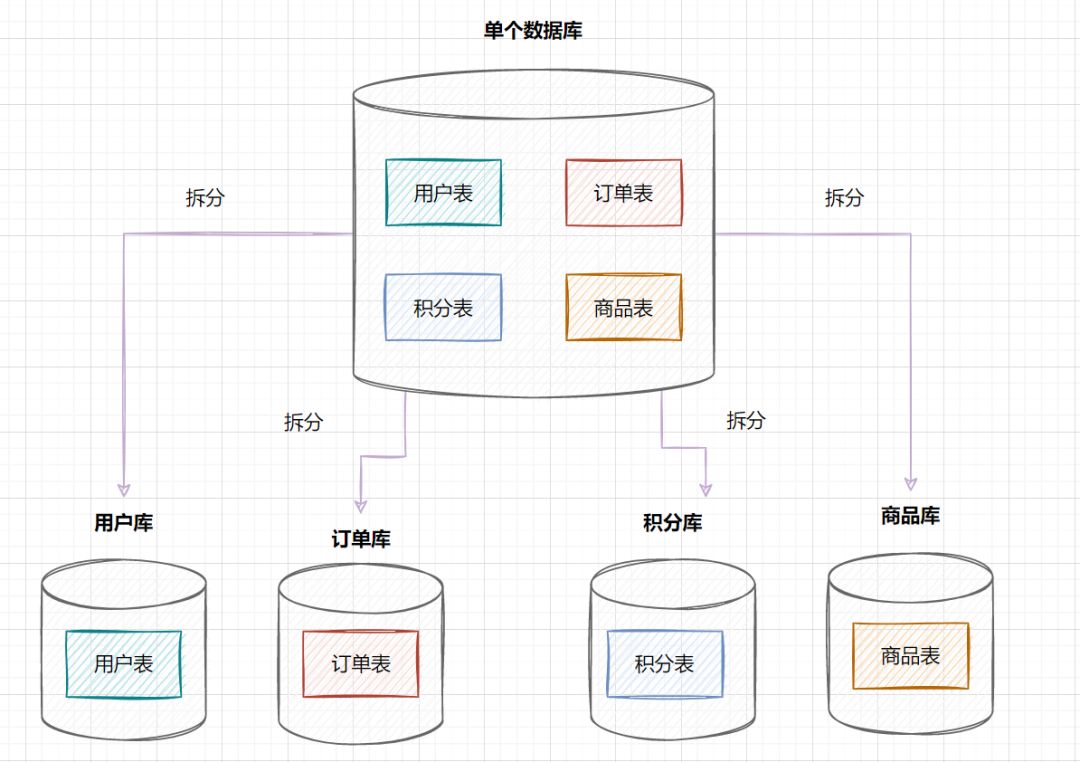 3.1.2 垂直分表如果一個單表包含了幾十列甚至上百列,管理起來很混亂,每次都 比如一張用戶表,它包含 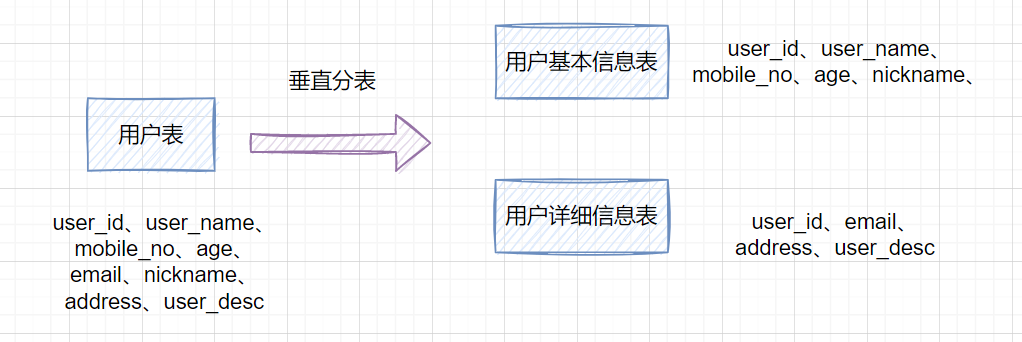 3.2 水平拆分3.2.1 水平分庫水平分庫是指,將表的數(shù)據(jù)量切分到不同的數(shù)據(jù)庫服務(wù)器上,每個服務(wù)器具有相同的庫和表,只是表中的數(shù)據(jù)集合不一樣。它可以有效的緩解單機(jī)單庫的性能瓶頸和壓力。 用戶庫的水平拆分架構(gòu)如下: 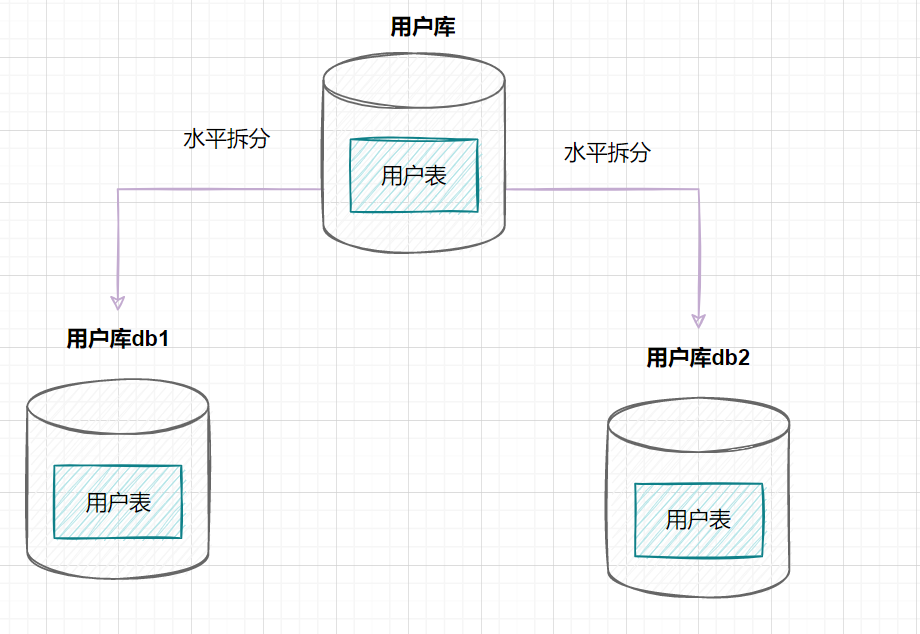 3.2.2 水平分表如果一個表的數(shù)據(jù)量太大,可以按照某種規(guī)則(如 一張訂單表,按 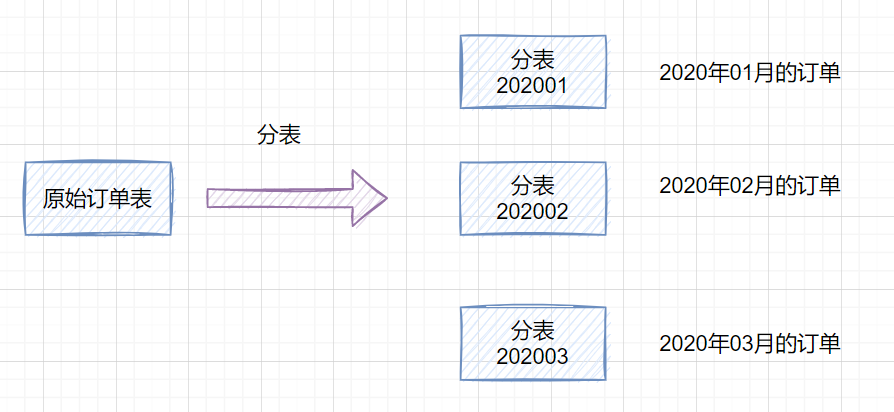 3.3. 水平分庫分表策略分庫分表策略一般有幾種,使用與不同的場景:
3.3.1 range范圍range,即范圍策略劃分表。比如我們可以將表的主鍵,按照從 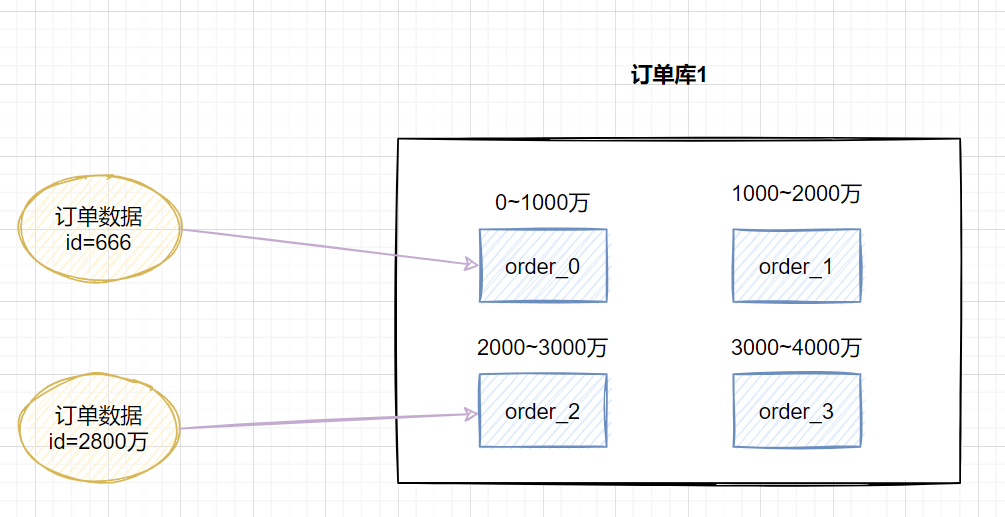 當(dāng)然,有時候我們也可以按時間范圍來劃分,如不同年月的訂單放到不同的表,它也是一種range的劃分策略。 這種方案的優(yōu)點(diǎn):
缺點(diǎn):
3.3.2 hash取模hash取模策略:指定的路由key(一般是user_id、訂單id作為key)對分表總數(shù)進(jìn)行取模,把數(shù)據(jù)分散到各個表中。 比如原始訂單表信息,我們把它分成4張分表: 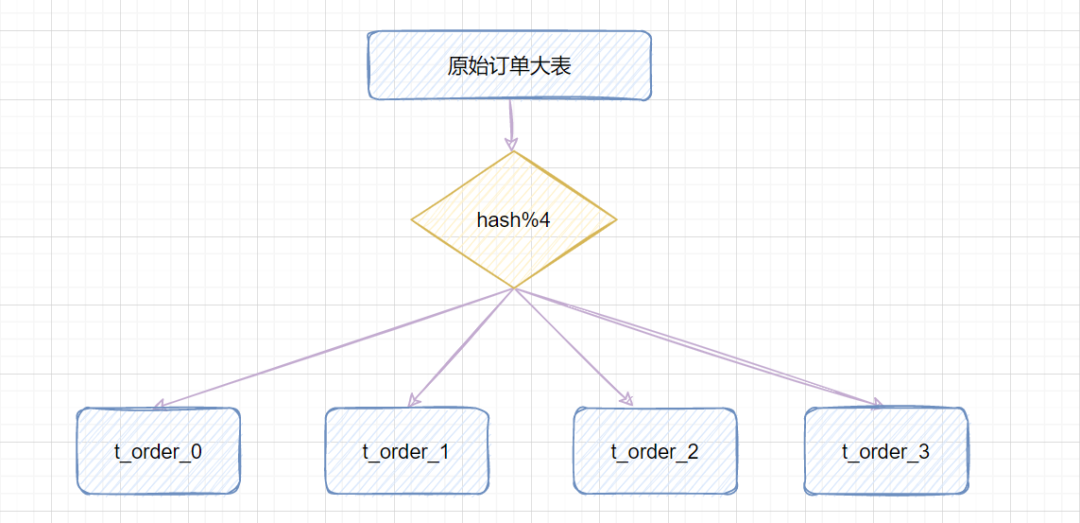
這種方案的優(yōu)點(diǎn):
缺點(diǎn):
3.3.3 range+hash取模混合既然range存在熱點(diǎn)數(shù)據(jù)問題,hash取模擴(kuò)容遷移數(shù)據(jù)比較困難,我們可以綜合兩種方案一起嘛,取之之長,棄之之短。 比較簡單的做法就是,在拆分庫的時候,我們可以先用range范圍方案,比如訂單id在0~4000萬的區(qū)間,劃分為訂單庫1;id在4000萬~8000萬的數(shù)據(jù),劃分到訂單庫2,將來要擴(kuò)容時,id在8000萬~1.2億的數(shù)據(jù),劃分到訂單庫3。然后訂單庫內(nèi),再用hash取模的策略,把不同訂單劃分到不同的表。 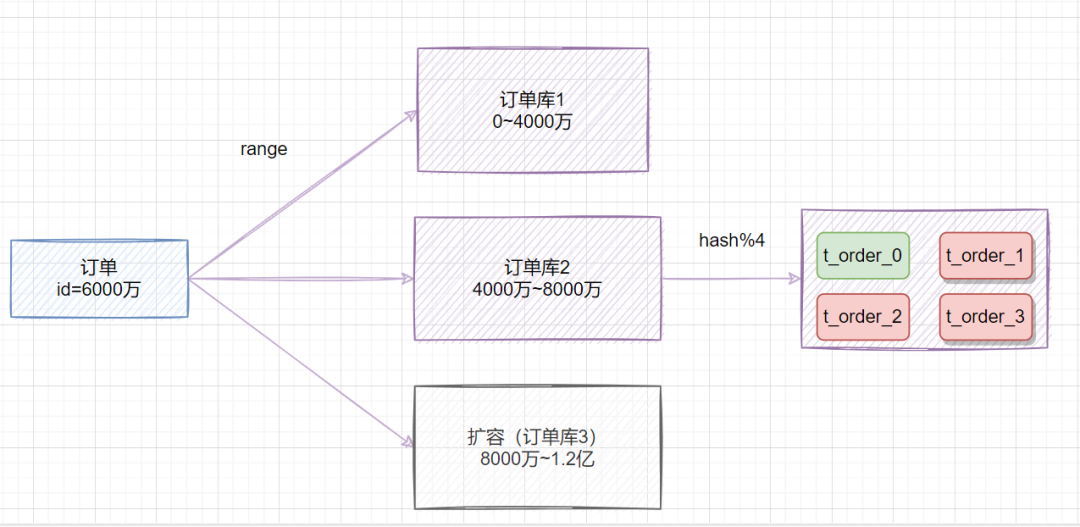 4. 什么時候才考慮分庫分表呢?4.1 什么時候分表?如果你的系統(tǒng)處于快速發(fā)展時期,如果每天的訂單流水都新增幾十萬,并且,訂單表的查詢效率明變慢時,就需要規(guī)劃分庫分表了。一般B+樹索引高度是2~3層最佳,如果數(shù)據(jù)量千萬級別,可能高度就變4層了,數(shù)據(jù)量就會明顯變慢了。不過業(yè)界流傳,一般500萬數(shù)據(jù)就要考慮分表了。 4.2 什么時候分庫業(yè)務(wù)發(fā)展很快,還是多個服務(wù)共享一個單體數(shù)據(jù)庫,數(shù)據(jù)庫成為了性能瓶頸,就需要考慮分庫了。比如訂單、用戶等,都可以抽取出來,新搞個應(yīng)用(其實(shí)就是微服務(wù)思想),并且拆分?jǐn)?shù)據(jù)庫(訂單庫、用戶庫)。 5. 分庫分表會導(dǎo)致哪些問題分庫分表之后,也會存在一些問題:
5.1 事務(wù)問題分庫分表后,假設(shè)兩個表在不同的數(shù)據(jù)庫,那么本地事務(wù)已經(jīng)無效啦,需要使用分布式事務(wù)了。 5.2 跨庫關(guān)聯(lián)跨節(jié)點(diǎn)Join的問題:解決這一問題可以分兩次查詢實(shí)現(xiàn) 5.3 排序問題跨節(jié)點(diǎn)的count,order by,group by以及聚合函數(shù)等問題:可以分別在各個節(jié)點(diǎn)上得到結(jié)果后在應(yīng)用程序端進(jìn)行合并。 5.4 分頁問題
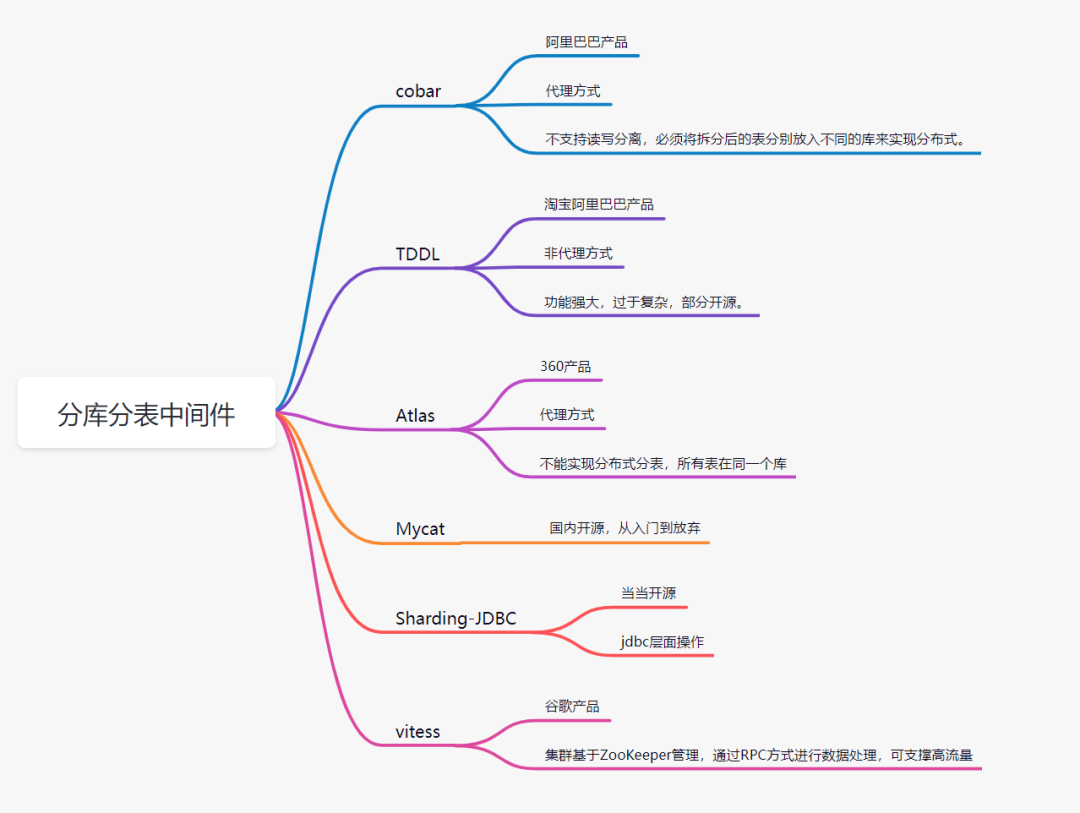
5.5 分布式ID數(shù)據(jù)庫被切分后,不能再依賴數(shù)據(jù)庫自身的主鍵生成機(jī)制啦,最簡單可以考慮UUID,或者使用雪花算法生成分布式ID。 6. 分庫分表中間件目前流行的分庫分表中間件比較多:
 該文章在 2023/6/28 16:12:38 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

