 :人工智能發(fā)展到今天,還有哪些創(chuàng)業(yè)機遇?
:人工智能發(fā)展到今天,還有哪些創(chuàng)業(yè)機遇?
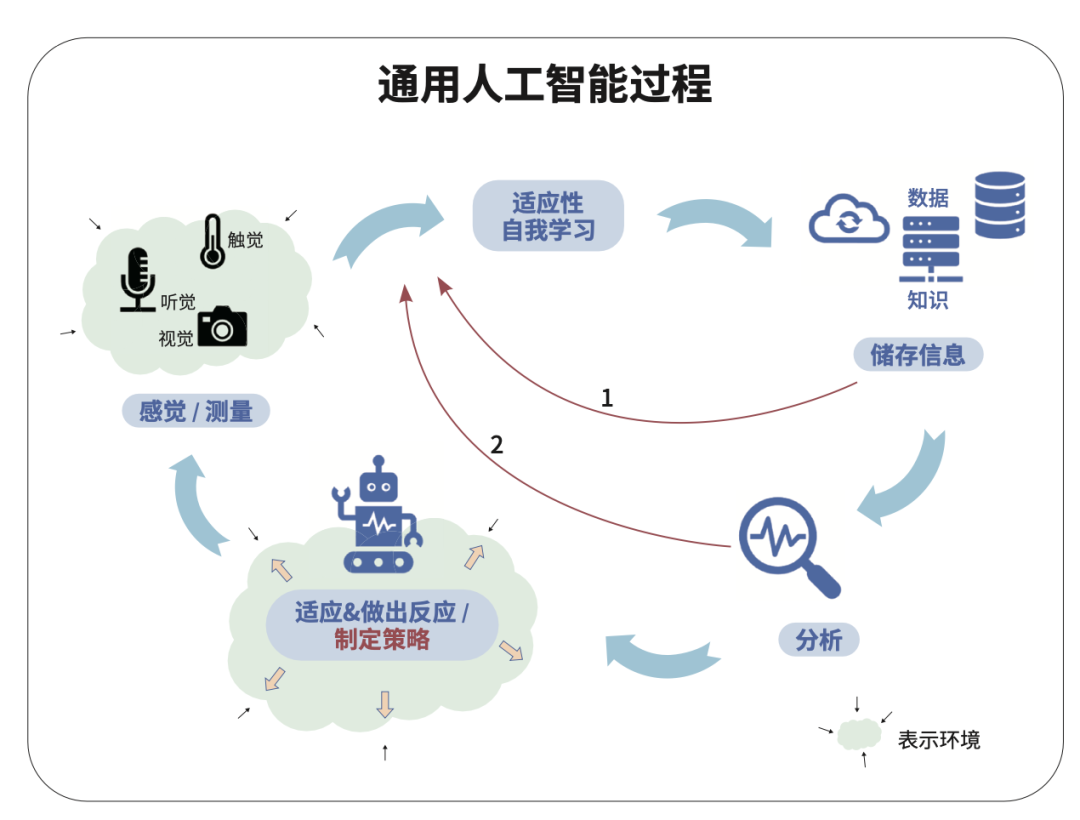
鑒于目前的形勢,我們不將人工智能納入創(chuàng)業(yè)計劃中將是一種疏忽。即使創(chuàng)業(yè)項目與技術(shù)無關(guān),出于以下三種原因,創(chuàng)業(yè)者也應(yīng)該對人工智能有基本的了解。1.人工智能支持的商業(yè)模式可能直接或間接地與你的價值主張競爭。2.無論所處行業(yè)的性質(zhì)如何,你都可以使用人工智能來增強你的價值主張或提高運營效率。3.創(chuàng)新技術(shù)代表著社會的變革,這開辟了全新的無人問津的領(lǐng)域,隨著技術(shù)變革帶來的社會變革,創(chuàng)業(yè)者甚至可能會使用早期的技術(shù)來解決新的需求。人工智能中的關(guān)鍵詞是智能,人工這個詞只是暗示了我們?nèi)祟愂瞧鋭?chuàng)造者,而自然智能則是與生俱來的。什么是智能?學(xué)者們普遍認為智能指的是一個智能體感知事物、推斷、記憶信息并將其用于適應(yīng)環(huán)境的能力。盡管這種觀點并無不準(zhǔn)確的地方,但它并未考慮認識到智能過程中自我反饋的方面。讓我們先討論這個過程的組成部分。1、感知。所謂感知,涵蓋了從環(huán)境實體中感受到的每一個刺激,這些實體可以是其他人類、動物和植物,機器、我們創(chuàng)造的工具、無生命的物體以及水、火和土地等自然元素。例如,我們的視覺涉及對光的感知,而相機、光度計或激光傳感器亦可以感知光影。如果感知能力被扼殺在萌芽狀態(tài),智能過程就無法開始。2、學(xué)習(xí)。當(dāng)我們觸摸某物時,我們可以感受到溫度。然而,只有當(dāng)我們將這種感覺與先前的經(jīng)驗進行比較時,我們才能推斷出物體是冷還是熱。如果沒有比較學(xué)習(xí),感知的效用仍然是微弱的。保留儲存先前感知到的信息是學(xué)習(xí)的基礎(chǔ),在口語中,我們稱之為記憶。學(xué)習(xí)中對信息的不斷積累構(gòu)成了知識庫。3、自適應(yīng)學(xué)習(xí)。這涉及學(xué)習(xí)過程本身的變化。更多的數(shù)據(jù)點可能使智能體能夠得出更精細的推斷,然而,在自適應(yīng)學(xué)習(xí)中,智能體可能會從感知中獲得完全不同類型的信息,或者完全使用不同類型的感知來獲得相同的信息,它甚至可以發(fā)展出新的感知能力,并學(xué)會獲得全新類型的信息。4、適應(yīng)。這是指一個智能體為了保護自己和促進自身利益,會通過學(xué)習(xí)來改變自身和利用各種環(huán)境,適應(yīng)包括增強現(xiàn)有的感知能力或開發(fā)新的能力。智能體可以策略性地行動,以較少的迭代次數(shù)實現(xiàn)其目標(biāo),從而更好地適應(yīng)環(huán)境。圖“人類的智能過程”的具體解釋是,新生兒具有尚未發(fā)育完全的感官,并具有天生的學(xué)習(xí)和適應(yīng)能力(即人類智能)。兒童的天生智能使其能夠保留一些初級知覺以啟動智能過程,這種保留是構(gòu)建知識庫或者說經(jīng)驗庫的基礎(chǔ)。在此之后,當(dāng)兒童接觸到另一種刺激時,他/她將有機會通過將當(dāng)前刺激與之前經(jīng)驗中保留的刺激進行比較來從中提取信息,這是學(xué)習(xí)的基礎(chǔ)。隨著孩子不斷豐富自己的知識庫,其天生智能使其能夠分析、識別樣式,并從不斷積累的學(xué)習(xí)中得出更多的推論。兒童會調(diào)整自己的行為,以改善其感知能力、增強其學(xué)習(xí)能力。我們通常會繞過圖“人類的智能過程”中箭頭1所示的保留階段,只是本能地分析信息并對其做出反應(yīng)。有時,我們也只是會短暫地保留信息,即所謂的短期記憶。當(dāng)然,一些被保留下來的信息也會找到通往長期記憶的途徑。這兩種記憶都通過實時比較新感知與先前的感知來增強學(xué)習(xí)(箭頭2),這使我們能夠從相同的感官和感知中推斷出更多的信息。在其他情況下,我們會從我們的知識庫中分析信息,以識別更好的推斷信息的方法(箭頭3),我之前提到過這個叫作適應(yīng)性學(xué)習(xí)。為了實現(xiàn)從當(dāng)前和先前的經(jīng)驗中分析信息,以適應(yīng)外部環(huán)境,我們還要調(diào)整從各種感知中提取信息的類型和質(zhì)量(箭頭4),例如,當(dāng)我們努力在惡劣的環(huán)境中求生存時,即使在之前的同一景象中無法從感知中推斷出這些信息,現(xiàn)在也能夠通過察覺變化從中推斷動態(tài)信息。我們的策略有時可能會涉及全新的感知類別工具和能力的開發(fā)。無論如何,情報過程都會繼續(xù)重復(fù)并自我補充,圖“人類的智能過程”中連接感知、推斷、保留、分析和適應(yīng)的大循環(huán)的完成也證明了這一點。我們的感覺器官與大腦相連,大腦可以從感知中實時推斷信息,并將這些信息儲存在記憶中,因此在圖“人類的智能過程”中,保留階段遵循推斷。然而,盡管一些機械傳感器能夠?qū)崟r推斷信息的處理單元,但大多數(shù)傳感器只能感知和測量,因此,圖“當(dāng)前人工智能過程”中的第二階段只是將測量值保留為一個數(shù)據(jù)點。當(dāng)今的企業(yè)談?wù)撌褂萌斯ぶ悄軙r,通常指的是實時的語音和人臉識別能力。盡管這些系統(tǒng)取得了有意義的進展,但它們目前仍有著難以接受的高錯誤率。我們?nèi)祟悜?yīng)該使用能夠從信號、圖像或聲音中推斷出信息的數(shù)據(jù)庫來訓(xùn)練人工智能系統(tǒng),然后,人工智能系統(tǒng)在訓(xùn)練數(shù)據(jù)庫的過程中尋找模式并學(xué)習(xí)推斷,對于錯誤的推斷進行有目的的分析,展現(xiàn)了用于改進訓(xùn)練模塊的見解(圖“當(dāng)前人工智能過程”中的箭頭1)。其中,箭頭中的虛線表示人類參與,訓(xùn)練模塊有效地將人類積累了數(shù)千年的學(xué)習(xí)積累轉(zhuǎn)移給人工智能系統(tǒng)。有些公司開發(fā)了軟件代碼,使系統(tǒng)在初始訓(xùn)練模塊之外不需要人類參與就能提高準(zhǔn)確性。這樣的系統(tǒng)可以:判斷其先前的推斷是否正確;修正其進行推斷的過程;通過從實時信號中推斷信息,迭代地測試其過程(箭頭2)。連接保留、學(xué)習(xí)、推斷和分析的循環(huán)代表了人工智能的當(dāng)前狀態(tài),它允許系統(tǒng)實時測試推斷并更新過程以提高質(zhì)量,類似于自適應(yīng)學(xué)習(xí),并能充分描述人工智能的當(dāng)前局限。ChatGPT正是處于這一方向的前沿,它不僅能識別對話中的語境和單詞的含義,還能從先前的陳述中得出推論,以維持對話。實際上,這就像我們自己的學(xué)習(xí)能力一樣。打個比方,父親根據(jù)自己的知識和經(jīng)驗教育孩子,然后,孩子在自己獨自生活的過程中,他會利用自己與生俱來的智慧,并在父親教導(dǎo)的基礎(chǔ)之上,與父親所處的不同環(huán)境中的事物進行互動,并且學(xué)習(xí)新的知識。同樣,計算機系統(tǒng)根據(jù)它從訓(xùn)練模塊中學(xué)到的內(nèi)容推斷出特定的信息,然后查看其他相關(guān)或不相關(guān)的數(shù)據(jù)點,分析推斷出的信息是否正確,如果不正確,它就修正對模式的理解,重新制定一個新的推斷路徑,從而使系統(tǒng)變得智能化。我們還分析存儲數(shù)據(jù),以提高現(xiàn)有傳感器的測量精度,并識別新型傳感器的需求(箭頭3)。例如,攝像頭已經(jīng)變得更高清晰度,能夠捕捉更細致的細節(jié),而且正在用于開發(fā)自動駕駛汽車的新型攝像頭。(箭頭3的虛線仍然代表人類的參與。)目前,除了軟件代碼中的特定指令之外,人工智能系統(tǒng)不能適應(yīng)外部環(huán)境或?qū)ν獠凯h(huán)境做出反應(yīng),我們所擁有的最先進的軟件可以幫助系統(tǒng)自己添加或刪除代碼以提高性能或效率。如今,我們分析數(shù)據(jù)并根據(jù)目標(biāo)采取行動,自適應(yīng)組件僅限于提高推理的質(zhì)量。由測量、保留、推斷和分析組成的人工智能回路是一個明顯比人類智能回路小得多的子集。注意,適應(yīng)和反應(yīng)戰(zhàn)略是智能過程中的一個關(guān)鍵步驟,不會反饋到圖“當(dāng)前人工智能過程”中的人工智能循環(huán)中。通用人工智能是一個可以與人類智慧相媲美的完全成熟的系統(tǒng)。圖“通用人工智能過程”描述了這樣一個系統(tǒng),它明顯缺少虛線箭頭,因為這樣的系統(tǒng)不依賴于人類。雖然它沒有代表先天智能的新生兒,但在適應(yīng)階段展示的機器人意味著所有人類知識都存儲在數(shù)據(jù)庫中,機器已經(jīng)接受了適應(yīng)性學(xué)習(xí)的訓(xùn)練。此外,與圖“當(dāng)前人工智能過程”不同的是,保留在推斷階段之后,這意味著增強的計算能力和經(jīng)過訓(xùn)練的系統(tǒng)允許實時推斷,并且圖“通用人工智能過程”中的智能回路是完整的,這樣的系統(tǒng)能夠制定行動策略以適應(yīng)或?qū)ζ洵h(huán)境做出反應(yīng)。目前,人工智能公司正在努力通過增強培訓(xùn)模塊和自適應(yīng)學(xué)習(xí)軟件來提高特定領(lǐng)域人工智能的準(zhǔn)確性。未來的努力可能會集中在擴大人工智能系統(tǒng)的領(lǐng)域,以利用從一個環(huán)境到另一個環(huán)境的學(xué)習(xí)。連接性是這一努力的核心,它使系統(tǒng)對于來自不同領(lǐng)域和環(huán)境的傳感器的輸入擁有更高的訪問權(quán)限,它還允許系統(tǒng)對計算能力進行更高級的訪問,并擴大了系統(tǒng)影響環(huán)境的范圍。因此,未來的開發(fā)工作將側(cè)重于增強不同系統(tǒng)的連接性,之后,隨著人工智能的成熟,努力的重點可能是有選擇性地限制人工智能的影響范圍,以平衡效率與安全和其他需求。然而,在人工智能達到成熟之前,人類將不得不面對這樣一種可能性:即在一個目標(biāo)不明確的流氓系統(tǒng)的指揮下,相互連接的機器會強大到足以壓倒人類的意志和資源,從而威脅到我們的自由。到目前為止,我們一直在假設(shè),當(dāng)機器(以機器人為例)實現(xiàn)通用人工智能時,我們?nèi)匀粫x機器的目標(biāo)函數(shù),但這個假設(shè)可能不成立。如今我們的環(huán)境包括了機器、機器人和計算機系統(tǒng),我們根據(jù)自己的喜好使用它們作為工具來改變環(huán)境。在未來,人工智能系統(tǒng)可能會利用它對人類行為的了解,把我們當(dāng)作工具來操縱它們的環(huán)境,而這個環(huán)境也將包括我們。對于沒有直接參與人工智能開發(fā)的企業(yè)家來說,機會存在于以下4個方面:1、在過去的十年里,盡管數(shù)據(jù)的產(chǎn)生量增長了近5000%,但在未來幾年里,數(shù)據(jù)的產(chǎn)生量可能會使人類歷史上創(chuàng)建的所有數(shù)據(jù)都相形見絀,這為數(shù)據(jù)存儲、數(shù)據(jù)管理和數(shù)據(jù)分析等領(lǐng)域提供了機遇。2、盡管我們的計算能力得到了前所未有的提高,但其仍然是有限的。我們需要新的硬件技術(shù)來跟上數(shù)據(jù)增長的步伐,量子計算很可能是這一努力的核心。一旦開發(fā)出來,這種新的模式將催生出一系列我們今天甚至無法理解的產(chǎn)品和機遇。3、大多數(shù)創(chuàng)業(yè)機會都需要應(yīng)用人工智能來滿足特定領(lǐng)域的特定需求。例如,有些公司可能會創(chuàng)建人工智能設(shè)備來診斷健康問題,尋找治療方法,幫助殘疾人以及提供醫(yī)療服務(wù)。還有些公司可能會利用人工智能通過運動或飲食維持健康、訓(xùn)練運動員,或者協(xié)助物理治療來恢復(fù)受傷的部位。即使在像農(nóng)業(yè)這樣古老的領(lǐng)域,也有公司使用人工智能來識別雜草,并用除草劑選擇性地處理它們。你甚至可以想象使用人工智能來根據(jù)土壤成分、日照、降雨、地形、天氣等因素來識別每一株植物的個體輸入需求,甚至識別每一顆果實的最佳采摘時間。4、為人工智能系統(tǒng)的創(chuàng)建者和用戶提供支持服務(wù)的公司將會有很大的需求。例如,那些專門從事管理工作變動相關(guān)的公共關(guān)系問題的公司,處理涉及傷害或死亡的人工智能失敗的異常情況的公司,遵守法規(guī)要求的公司,或是開發(fā)工具來捕捉和衡量人工智能對公司和社會好處的公司。
該文章在 2023/8/22 12:01:14 編輯過

的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
")

