簡(jiǎn)介
經(jīng)常有小哥發(fā)出疑問,SQL還能這么寫?我經(jīng)常笑著回應(yīng),SQL確實(shí)可以這么寫。其實(shí)SQL學(xué)起來簡(jiǎn)單,用起來也簡(jiǎn)單,但它還是能寫出很多變化,這些變化讀懂它不難,但要自己Get到這些變化,可能需要想一會(huì)或在網(wǎng)上找一會(huì)。
各種join
關(guān)于join的介紹,比較流行的就是這張圖了,如下:
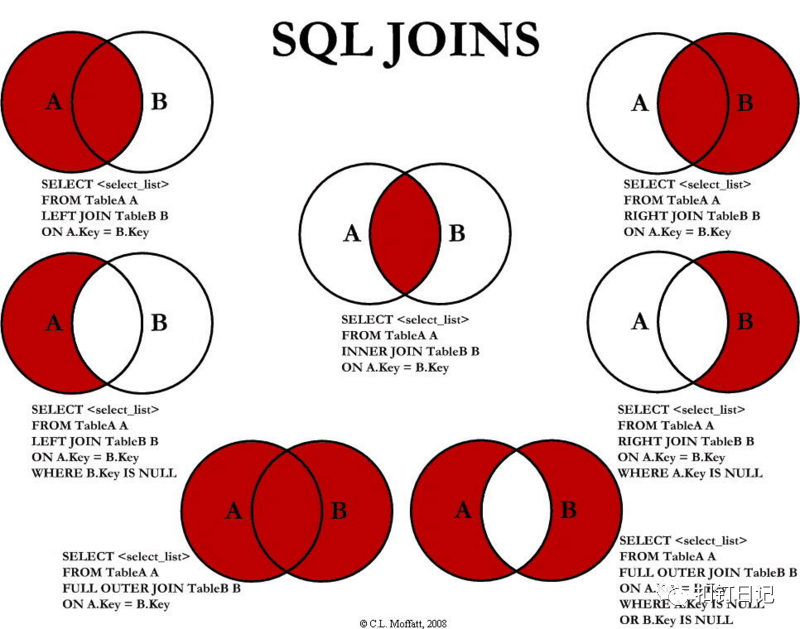
簡(jiǎn)單的解釋如下:
- join:內(nèi)聯(lián)接,也可寫成inner join,取兩表關(guān)聯(lián)字段相交的那部分?jǐn)?shù)據(jù)。
- left join:左外聯(lián)接,也可寫成left outer join,取左表數(shù)據(jù),若關(guān)聯(lián)不到右表,右表為空。
- right join:右外聯(lián)接,也可寫成right outer join,取右表數(shù)據(jù),若關(guān)聯(lián)不到左表,左表為空。
- full join:全聯(lián)接,也可寫成full outer join,取左表和右表中所有數(shù)據(jù)。
但注意上圖,里面還有幾個(gè)Key is null的情況,它可以將兩表相交的那部分?jǐn)?shù)據(jù)排除掉!
也正是因?yàn)檫@個(gè)特性,一種很常見的SQL技巧是,用left join可替換not exists、not in等相關(guān)子查詢,如下:
select * from tableA A
where not exists (select 1 from tableB B where B.Key=A.Key)
-- 使用left join的等價(jià)寫法
select * from tableA A
left join tableB B on B.Key=A.Key where B.Key is null
也比較好理解,只有當(dāng)左表的數(shù)據(jù)在右表中不存在時(shí),B.Key is null才成立。
查詢各類別最大的那條數(shù)據(jù)
比如在學(xué)籍管理系統(tǒng)中,有一類很常見的需求,查詢每學(xué)科分?jǐn)?shù)最高的那條數(shù)據(jù),有如下幾種寫法:
select * from stu_score s
where s.course_id in ('Maths','English')
and s.score = (select max(score) from stu_score s1 where s1.course_id = s.course_id)
比較好理解,考分最高其實(shí)就是過濾出分?jǐn)?shù)等于最大分?jǐn)?shù)的記錄。
在不能使用子查詢的場(chǎng)景下,也可轉(zhuǎn)換成join,如下:
select * from stu_score s
left join stu_score s1 on s1.course_id = s.course_id and s1.score > s.score
where s.course_id in ('Maths','English') and s1.id is null
這和前面用left join改寫not exists類似,通過s1.id is null過濾出left join關(guān)聯(lián)條件不滿足時(shí)的數(shù)據(jù),什么情況left join關(guān)聯(lián)條件不滿足呢,當(dāng)s表記錄是分?jǐn)?shù)最大的那條記錄時(shí),s1.score > s.score條件自然就不成立了,所以它過濾出來的數(shù)據(jù),就是學(xué)科中分?jǐn)?shù)最大的那條記錄。
一直以來,我看到SQL的join的條件大都是a.field=b.field這種形式,導(dǎo)致我以為join只能寫等值條件,實(shí)際上,join條件和where中一樣,支持>、<、like、in甚至是exists子查詢等條件,大家也一定不要忽視了這一點(diǎn)。
上面場(chǎng)景還有一種寫法,就是使用group by先把各學(xué)科最大分算出來,然后再關(guān)聯(lián)出相應(yīng)數(shù)據(jù),如下:
select * from
(select s.course_id,max(s.score) max_score stu_score s where s.course_id in ('Maths','English') group by s.course_id) sm
join stu_score s1 on s1.course_id = sm.course_id and s1.score=sm.max_score
查詢各類別top n數(shù)據(jù)
比如在學(xué)籍管理系統(tǒng)中,查詢每學(xué)科分?jǐn)?shù)前5的記錄,類似這種需求也很常見,比較簡(jiǎn)單明了的寫法如下:
select * from stu_score s
where s.course_id in ('Maths','English')
and (select count(*) from stu_score s1 where s1.course_id = s.course_id and s1.score > s.score) < 5
很顯然,第5名只有4個(gè)學(xué)生比它分?jǐn)?shù)高,第4名只有3個(gè)學(xué)生比它分?jǐn)?shù)高,依此類推。
LATERAL join
MySQL8為join提供了一個(gè)新的語法LATERAL,使得被關(guān)聯(lián)表B在聯(lián)接前可以先根據(jù)關(guān)聯(lián)表A的字段過濾一下,然后再進(jìn)行關(guān)聯(lián)。
這個(gè)新的語法,可以非常簡(jiǎn)單的解決上面top n的場(chǎng)景,如下:
select * from stu_course c
join LATERAL (select * from stu_score s where c.course_id = s.course_id order by s.score desc limit 5) s1 on c.course_id = s1.course_id
where c.course_name in ('數(shù)學(xué)','英語')
如上,每個(gè)學(xué)科查詢出它的前5名記錄,然后再關(guān)聯(lián)起來。
統(tǒng)計(jì)多個(gè)數(shù)量
使用count(*)可以統(tǒng)計(jì)數(shù)量,但有些場(chǎng)景想統(tǒng)計(jì)多個(gè)數(shù)量,如統(tǒng)計(jì)1天內(nèi)單量、1周內(nèi)單量、1月內(nèi)單量。
用count(*)的話,需要掃描3次表,如下:
select count(*) from order where add_time > DATE_SUB(now(), INTERVAL 1 DAY)
union all
select count(*) from order where add_time > DATE_SUB(now(), INTERVAL 1 WEEK)
union all
select count(*) from order where add_time > DATE_SUB(now(), INTERVAL 1 MONTH)
其實(shí)掃描一次表也可以實(shí)現(xiàn),用sum來代替count即可,如下:
select sum(IF(add_time > DATE_SUB(now(), INTERVAL 1 DAY)), 1, 0) day_order_cnt,
sum(IF(add_time > DATE_SUB(now(), INTERVAL 1 WEEK)), 1, 0) week_order_cnt,
sum(IF(add_time > DATE_SUB(now(), INTERVAL 1 MONTH)), 1, 0) month_order_cnt
from order where add_time > DATE_SUB(now(), INTERVAL 1 MONTH)
IF是mysql的邏輯判斷函數(shù),當(dāng)其第一個(gè)參數(shù)為true時(shí),返回第二個(gè)參數(shù)值,即1,否則返回第三個(gè)參數(shù)值0,然后再使用sum加起來,就是各條件為true的數(shù)量了。
數(shù)據(jù)對(duì)比
有時(shí),我們需要對(duì)比兩個(gè)表的數(shù)據(jù)是否一致,最簡(jiǎn)單的方法,就是在兩邊查詢出結(jié)果集,然后逐行逐字段對(duì)比。
但是這樣對(duì)比的效率比較低下,因?yàn)樗獌蓚€(gè)表的數(shù)據(jù)全都查出來,其實(shí)我們不一定非要都查出來,只要計(jì)算出一個(gè)hash值,然后對(duì)比hash值即可,如下:
select BIT_XOR(CRC32(CONCAT(ifnull(column1,''),ifnull(column2,'')))) as checksum
from table_name where add_time > '2020-02-20' and add_time < '2020-02-21';
先使用CONCAT將要對(duì)比的列連接起來,然后使用CRC32或MD5計(jì)算hash值,最后使用聚合函數(shù)BIT_XOR將多行hash值異或合并為一個(gè)hash值。
這個(gè)查詢最終只會(huì)返回1條hash值,查詢數(shù)據(jù)量大大減少了,數(shù)據(jù)對(duì)比效率就上去了。
總結(jié)
SQL看起來簡(jiǎn)單,其實(shí)有很多細(xì)節(jié)與技巧,如果你也有其它技巧,歡迎留言分享討論😃
該文章在 2023/8/25 10:37:56 編輯過
晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲(chǔ)管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

