之所以推薦使用HTMLPurifier,是因為在剛剛過去的年度地區性網絡安全攻防演練中,我這邊的兩套PHP開發的系統面對WEB輸入攻擊,使用HTMLPurifier與否的遭遇是冰火兩重天。
這兩套系統都有用WAF設備作為第一重屏障,其中在開發中使用了HTMLPurifier的系統,經受了大量的各種WEB輸入攻擊嘗試依然不倒;而另外一套沒有用HTMLPurifier的系統則被各種注入,開發商方面只能疲于奔命地救火。
很顯然這和該開發商本身的安全能力存在不足是直接關系,甚至連WEB輸入需要集中過濾都沒有嚴格做好。不過這不在本次的討論內。我們要關注的是在實現了集中的GET/POST輸入過濾的前提下,HTMLPurifier所能實現的關鍵作用。
HTMLPurifier,簡單稱之為“HTML提純器”吧,是用PHP開發、對標兼容HTML標準的過濾功能函數庫,通過LGPL v2.1+授權許可模式開源。

HTML提純器基于經過仔細審計、被動式但確保安全的白名單,過濾刪除WEB輸入中夾雜的惡意代碼(XSS攻擊,SQL注入攻擊等等),并對WEB輸入內容與HTML標準的符合性進行修正。所以項目開發者把它不叫過濾器,而是叫提純器。
與HTML提純器類似的而且是開源的WEB輸入過濾解決方法(函數庫)也有不少,但這些解決辦法很多沒有持續更新,對新的HTML/CSS標準的兼容性有缺陷,也對防御新的攻擊手段存在欠缺。
關鍵在于如何實現過濾的細節上。HTML提純器的安全性和可靠性在于它是基于白名單放行而不是基于黑名單攔截。網絡安全從業人員都知道,黑名單必然會過時,而白名單基于良好審計的前提是完全可靠的。
XSS攻擊也好,SQL注入也好,這些攻擊手段的成功因素在于惡意利用了HTML規范中一些深層次的規范定義和瀏覽器實現的誤差。這些誤差導致惡意代碼非常容易變化,從而逃脫基于黑名單的過濾檢查。
而HTML提純器基于白名單過濾機制,對整個WEB輸入內容按HTML規范進行分解,檢查輸入內容中的任何一項HTML/CSS屬性,刪除任何白名單之外的元素和屬性,最后按標準規范校驗整理和重新格式化輸入內容。
基于以上實現邏輯,HTML提純器的安全性和可靠性是充足可信的。
HTML提純器的使用方法很簡單,尤其是對于全部環境都是基于UTF-8編碼的情況:
<?php
require_once './HtmlPurifier/HTMLPurifier.auto.php';
$PurifierConfig = HTMLPurifier_Config::createDefault();
$PurifierConfig->set('Core.Encoding', 'utf-8');
$PurifierObj = new HTMLPurifier($PurifierConfig);
$PurifiedData = $PurifierObj ->purify($MaliciousData);
創建默認配置,設置UTF-8編碼,按配置創建對象,調用對象方法執行過濾得到凈化后的內容,就這么簡單。
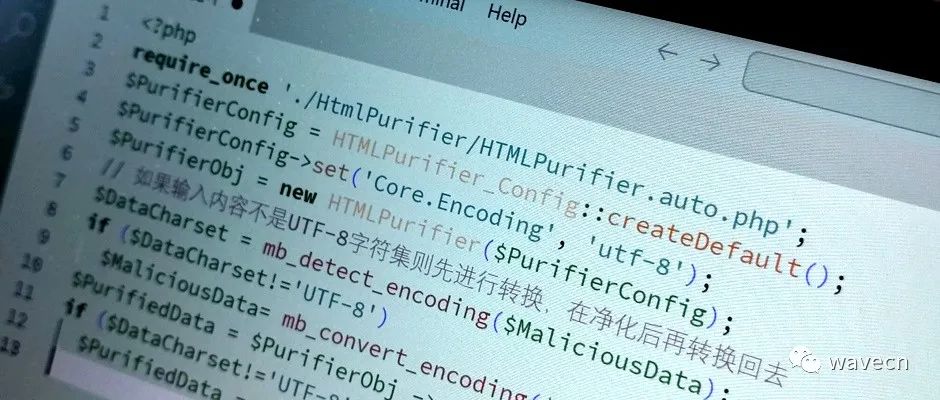
如果WEB環境不是UTF-8而是其他編碼,比如使用GB2312或者GBK編碼,HTML提純器需要在調用前先進行轉碼,然后完成執行過濾純凈化后再轉回去原來的編碼:
<?php
require_once './HtmlPurifier/HTMLPurifier.auto.php';
$PurifierConfig = HTMLPurifier_Config::createDefault();
$PurifierConfig->set('Core.Encoding', 'utf-8');
$PurifierObj = new HTMLPurifier($PurifierConfig);
// 如果輸入內容不是UTF-8字符集則先進行轉換,在凈化后再轉換回去
$DataCharset = mb_detect_encoding($MaliciousData);
if ($DataCharset!='UTF-8')
$MaliciousData= mb_convert_encoding($MaliciousData, 'UTF-8', $DataCharset);
$PurifiedData = $PurifierObj ->purify($MaliciousData);
if ($DataCharset!='UTF-8')
$PurifiedData = mb_convert_encoding($PurifiedData , $DataCharset, 'UTF-8');
必須說明的是上面這只是一個很粗略的例子。因為mb_detect_encoding和mb_convert_encoding實際都不能做到100%有效地檢測和轉換字符集。在應用以上代碼時,需要對輸入內容的字符集先進行假設,比如假設為GB2312/GBK字符集。由于mb_detect_encoding在判斷中文字符集時還存在一些誤判的情況,所以也有人是干脆按中文字符集編碼規范自己另外寫了一套判斷。不過這超越了本文主題,就不展開了,如對此有興趣可以后臺留言。下面是稍微復雜一些的使用例子:自選過濾保留的HTML標記和CSS屬性,并強制所有鏈接都在新窗口打開:
<?php
require_once './HtmlPurifier/HTMLPurifier.auto.php';
$PurifierConfig = HTMLPurifier_Config::createDefault();
$PurifierConfig->set('Core.Encoding', 'UTF-8');
// 可通過參數設置有選擇性地過濾XSS,但會大幅度降低性能,除非必要不建議使用。
// 設置保留的HTML標記,格式是:標記名稱[屬性]
$PurifierConfig->set('HTML.Allowed','div,b,strong,i,em,a[href|title],ul,ol,li,p[style],br,span[style],img[width|height|alt|src]');
// 設置保留的CSS屬性
$PurifierConfig->set('CSS.AllowedProperties', 'font,font-size,font-weight,font-style,font-family,text-decoration,padding-left,color,background-color,text-align');
// 設置強制所有的鏈接在新窗口打開
$PurifierConfig->set('HTML.TargetBlank', TRUE);
// 創建對象并執行過濾
$PurifierObj = new HTMLPurifier($PurifierConfig);
$PurifiedData = $PurifierObj ->purify($MaliciousData);
經過純凈化后的用戶輸入,就可以放心地用htmlspecialchars函數轉義保存到數據庫,以及從數據庫調取對用戶重現了。
如果要說本文的意義,那就是實證了DevSecOps,就是要把安全措施從運維轉移到開發環節。WAF設備始終只是一種輔助手段,并不是從根本上解決安全問題的辦法。
該文章在 2023/10/30 9:27:42 編輯過






 400 186 1886
400 186 1886


