10倍提升你的SQL查詢速度
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
 作為一名數(shù)據(jù)分析師,SQL是必備技能之一。其優(yōu)勢(shì)也比較明顯:易于理解,維護(hù)和擴(kuò)展。然而,最大的挑戰(zhàn)在于,隨著數(shù)據(jù)量的增加,我們就會(huì)遇到延遲的瓶頸,或者說查詢太昂貴(耗時(shí))而無法運(yùn)行。 在這篇文章中我將會(huì)給出一些克服瓶頸的經(jīng)驗(yàn),這些 tips 也許會(huì)讓延遲減小10倍甚至100倍。So,讓我們一起深入了解吧。 1. 理解 SQL 的查詢順序SQL 就像一個(gè)迷你版的編程語(yǔ)言,它按順序處理數(shù)據(jù)。 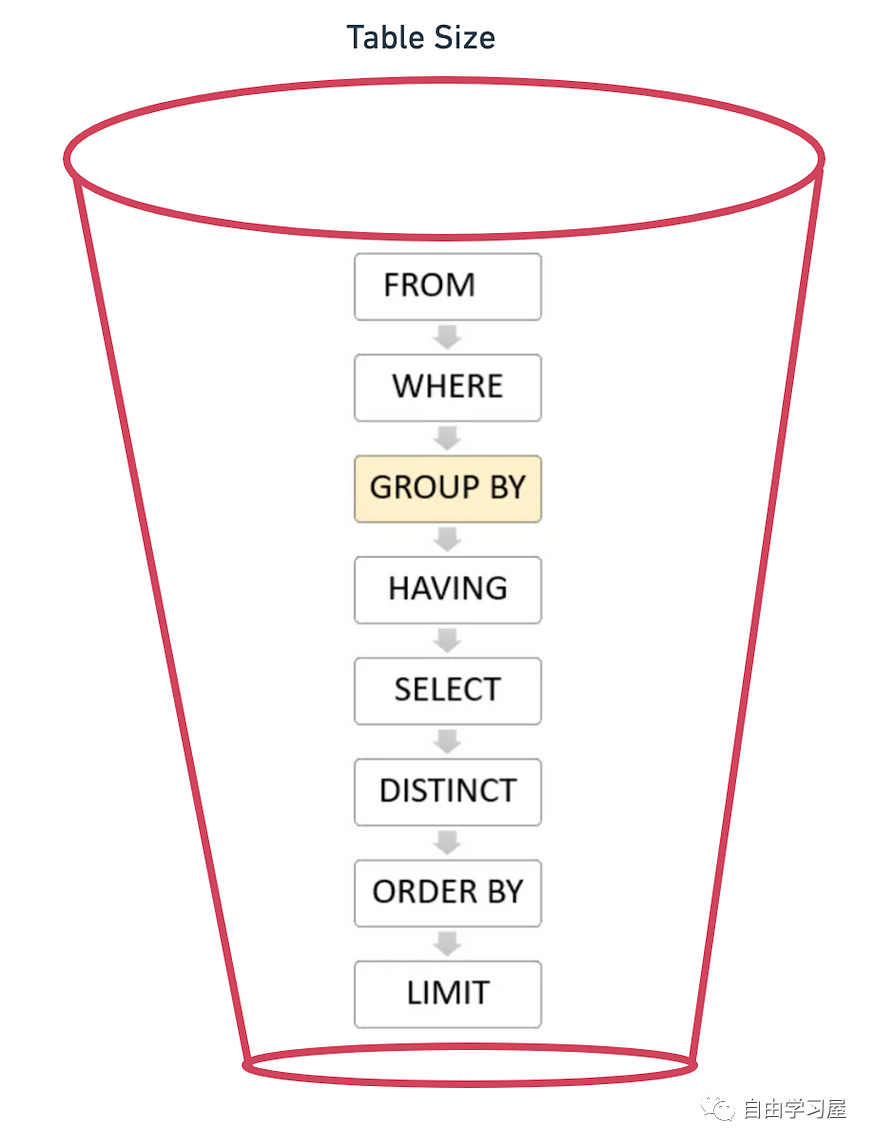 使用諸如“ 2. 用星型模式加快查詢速度在數(shù)據(jù)庫(kù)設(shè)計(jì)中,數(shù)據(jù)工程師喜歡對(duì)數(shù)據(jù)庫(kù)進(jìn)行規(guī)范化,減少數(shù)據(jù)表之間的冗余,從而優(yōu)化存儲(chǔ)、理清數(shù)據(jù)關(guān)系。然而,凡事皆有利弊,與之對(duì)應(yīng)的缺點(diǎn)是查詢時(shí)需要多個(gè)連接和子查詢來對(duì)數(shù)據(jù)進(jìn)行非規(guī)范化以提取所需的信息。 
為了加快查詢速度,建議首先對(duì)維度表進(jìn)行非規(guī)范化或聯(lián)接,因?yàn)榫S度表通常較小并且聯(lián)接速度更快。之后,如果可能的話,與大型事實(shí)表連接。在上述情況下,請(qǐng)嘗試在查詢的最后一步處理大型銷售表。根據(jù)前人的實(shí)踐經(jīng)驗(yàn),遵循這一理念通常可以將查詢速度提高 10 倍左右。 3. 通過了解關(guān)鍵索引將查詢速度提高 100 倍在下面的示例中,用戶可以按時(shí)間或按列遍歷/查詢數(shù)據(jù)。從視覺上看,按時(shí)間(逐行)或按列遍歷數(shù)據(jù),時(shí)間復(fù)雜度可能不會(huì)有太大差異。  然而,實(shí)際上,數(shù)據(jù)并不是以連續(xù)的方式存儲(chǔ)的。它更像是一個(gè)鏈表數(shù)據(jù)結(jié)構(gòu)。通過時(shí)間查詢與通過列查詢之間存在巨大差異。 如下圖所示,通過在查詢中使用時(shí)間索引,您可以輕松地將遍歷時(shí)間或查詢時(shí)間縮短10倍。隨著列數(shù)量的增加,效率增益甚至更大。國(guó)外某小哥親述在其項(xiàng)目工作中,在處理大型表(數(shù) GB 數(shù)據(jù))時(shí),他們將查詢時(shí)間從 41 天縮短到大約 40 分鐘,速度提高了約 100 倍。 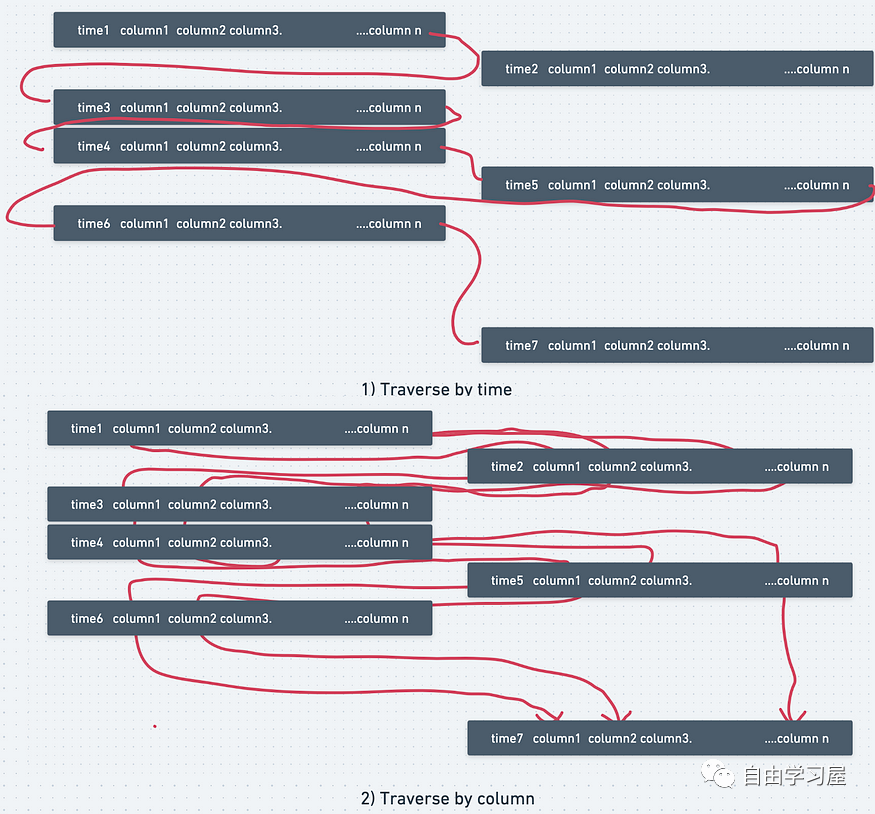 在這種情況下,基于時(shí)間塊運(yùn)行的查詢可能比按列運(yùn)行的查詢快 10 到 100 倍,因?yàn)閿?shù)據(jù)庫(kù)是按時(shí)間索引的。 此外,您可以要求數(shù)據(jù)分析師或數(shù)據(jù)工程師根據(jù)您的業(yè)務(wù)需求重新索引您的數(shù)據(jù)庫(kù)。 -- two queries to pull large data datable 4. 利用 Python 的能力在現(xiàn)實(shí)項(xiàng)目中,完成上述步驟后,由于 SQL 的帶寬或數(shù)據(jù)庫(kù)服務(wù)器的計(jì)算能力瓶頸,你的 SQL 查詢?nèi)匀徊粔蚩臁?/p> 這個(gè)時(shí)候就可以使用 Python/Pandas 將中間表緩存到本地驅(qū)動(dòng)器或云驅(qū)動(dòng)器,之后用戶就可以使用 Python 執(zhí)行繁重的表連接或聚合步驟,這樣通常會(huì)比在數(shù)據(jù)庫(kù)中執(zhí)行類似的步驟快得多。 下面是一個(gè)代碼示例,通過 Jupyter Notebook 執(zhí)行 PostgreSQL 查詢并將查詢結(jié)果導(dǎo)出為 dataframe: 5. 總結(jié)在這篇文章中,我們總結(jié)了四種加快你 SQL 查詢速度的方式:
希望這篇文章對(duì)您有用,如果您有更好的技巧或建議,請(qǐng)與我們一同分享。 Thank you for your reading, happy querying!
該文章在 2023/11/16 20:36:36 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")


