[點晴永久免費OA]完全圖解GPT-2:看完這篇就夠了
當前位置:點晴教程→點晴OA辦公管理信息系統
→『 經驗分享&問題答疑 』
完全圖解GPT-2:看完這篇就夠了
在過去的一年中,BERT、Transformer XL、XLNet 等大型自然語言處理模型輪番在各大自然語言處理任務排行榜上刷新最佳紀錄,可謂你方唱罷我登場。其中,GPT-2 由于其穩定、優異的性能吸引了業界的關注。 今年涌現出了許多機器學習的精彩應用,令人目不暇接,OpenAI 的 GPT-2 就是其中之一。它在文本生成上有著驚艷的表現,其生成的文本在上下文連貫性和情感表達上都超過了人們對目前階段語言模型的預期。僅從模型架構而言,GPT-2 并沒有特別新穎的架構,它和只帶有解碼器的 transformer 模型很像。 然而,GPT-2 有著超大的規模,它是一個在海量數據集上訓練的基于 transformer 的巨大模型。GPT-2 成功的背后究竟隱藏著什么秘密?本文將帶你一起探索取得優異性能的 GPT-2 模型架構,重點闡釋其中關鍵的自注意力(self-attention)層,并且看一看 GPT-2 采用的只有解碼器的 transformer 架構在語言建模之外的應用。 作者之前寫過一篇相關的介紹性文章「The Illustrated Transformer」,本文將在其基礎上加入更多關于 transformer 模型內部工作原理的可視化解釋,以及這段時間以來關于 transformer 模型的新進展。基于 transformer 的模型在持續演進,我們希望本文使用的這一套可視化表達方法可以使此類模型更容易解釋。 第一部分:GPT-2 和語言建模首先,究竟什么是語言模型(language model)? 何為語言模型簡單說來,語言模型的作用就是根據已有句子的一部分,來預測下一個單詞會是什么。最著名的語言模型你一定見過,就是我們手機上的輸入法,它可以根據當前輸入的內容智能推薦下一個詞。
從這個意義上說,我們可以說 GPT-2 基本上相當于輸入法的單詞聯想功能,但它比你手機上安裝的此類應用大得多,也更加復雜。OpenAI 的研究人員使用了一個從網絡上爬取的 40GB 超大數據集「WebText」訓練 GPT-2,該數據集也是他們的工作成果的一部分。 如果從占用存儲大小的角度進行比較,我現在用的手機輸入法「SwiftKey」也就占用了 50MB 的空間,而 GPT-2 的最小版本也需要至少 500MB 的空間來存儲它的全部參數,最大版本的 GPT-2 甚至需要超過 6.5GB 的存儲空間。
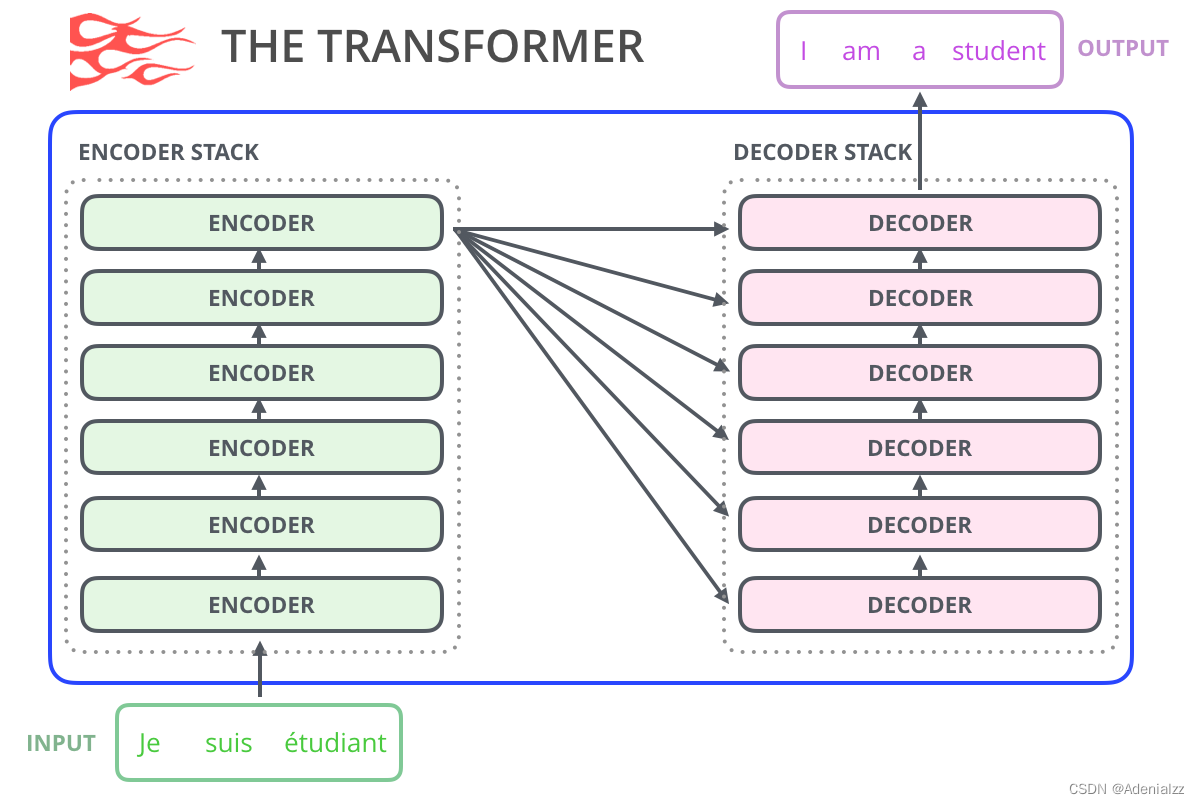
讀者可以用 AllenAI GPT-2 Explorer 來體驗 GPT-2 模型。它可以給出可能性排名前十的下一個單詞及其對應概率,你可以選擇其中一個單詞,然后看到下一個可能單詞的列表,如此往復,最終完成一篇文章。 使用 Transformers 進行語言建模正如本文作者在「The Illustrated Transformer 」這篇文章中所述,原始的 transformer 模型由編碼器(encoder)和解碼器(decoder)組成,二者都是由被我們稱為「transformer 模塊」的部分堆疊而成。這種架構在機器翻譯任務中取得的成功證實了它的有效性,值得一提的是,這個任務之前效果最好的方法也是基于編碼器-解碼器架構的。
Transformer 的許多后續工作嘗試去掉編碼器或解碼器,也就是只使用一套堆疊得盡可能多的 transformer 模塊,然后使用海量文本、耗費大量的算力進行訓練(研究者往往要投入數十萬美元來訓練這些語言模型,而在 AlphaStar 項目中則可能要花費數百萬美元)。
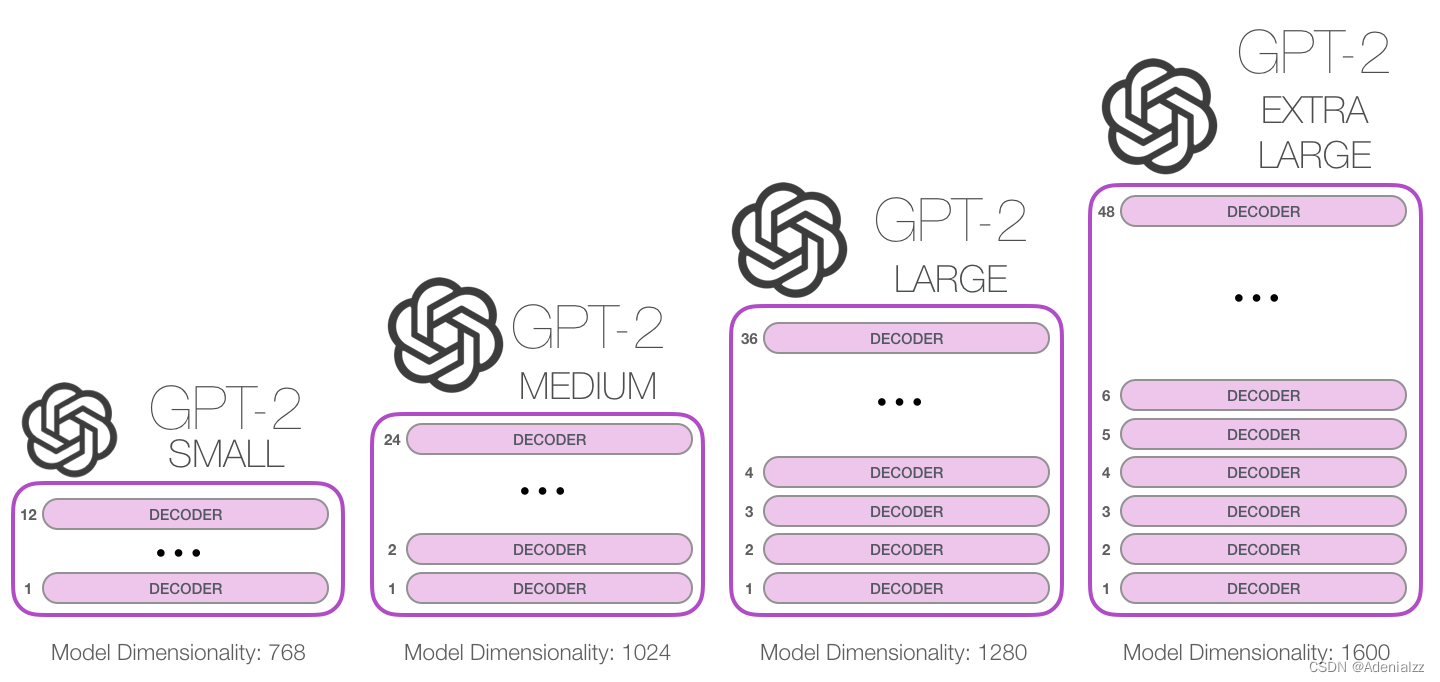
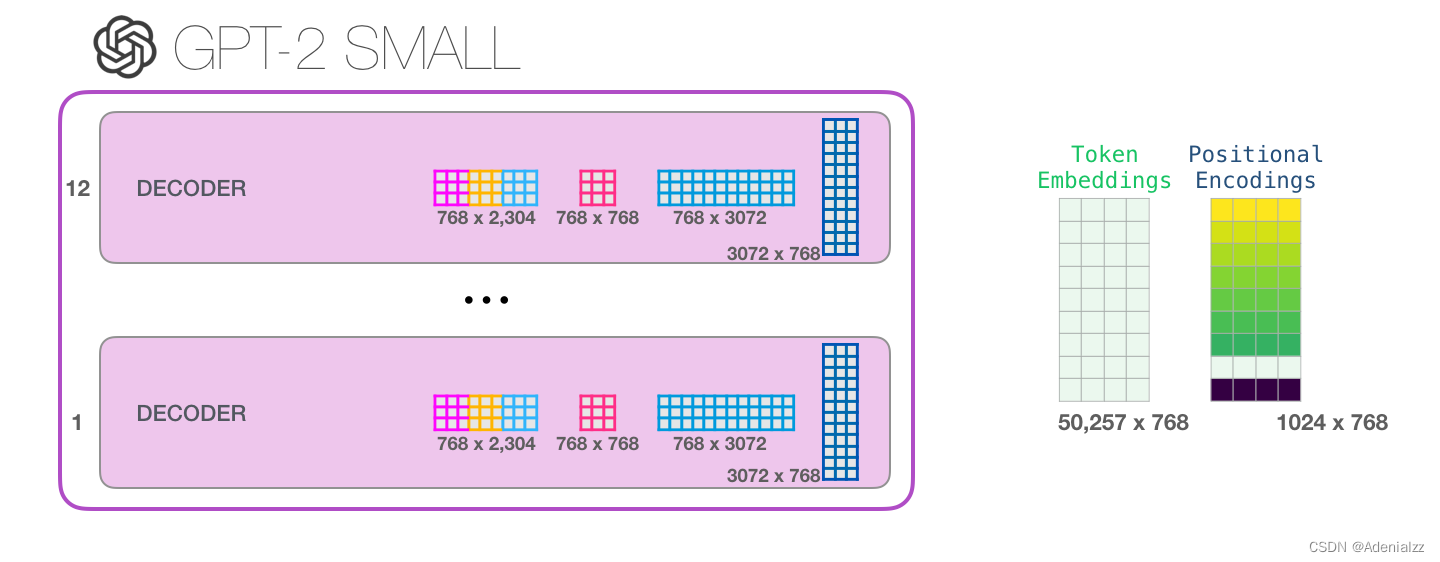
那么我們究竟能將這些模塊堆疊到多深呢?事實上,這個問題的答案也就是區別不同 GPT-2 模型的主要因素之一,如下圖所示。「小號」的 GPT-2 模型堆疊了 12 層,「中號」24 層,「大號」36 層,還有一個「特大號」堆疊了整整 48 層。
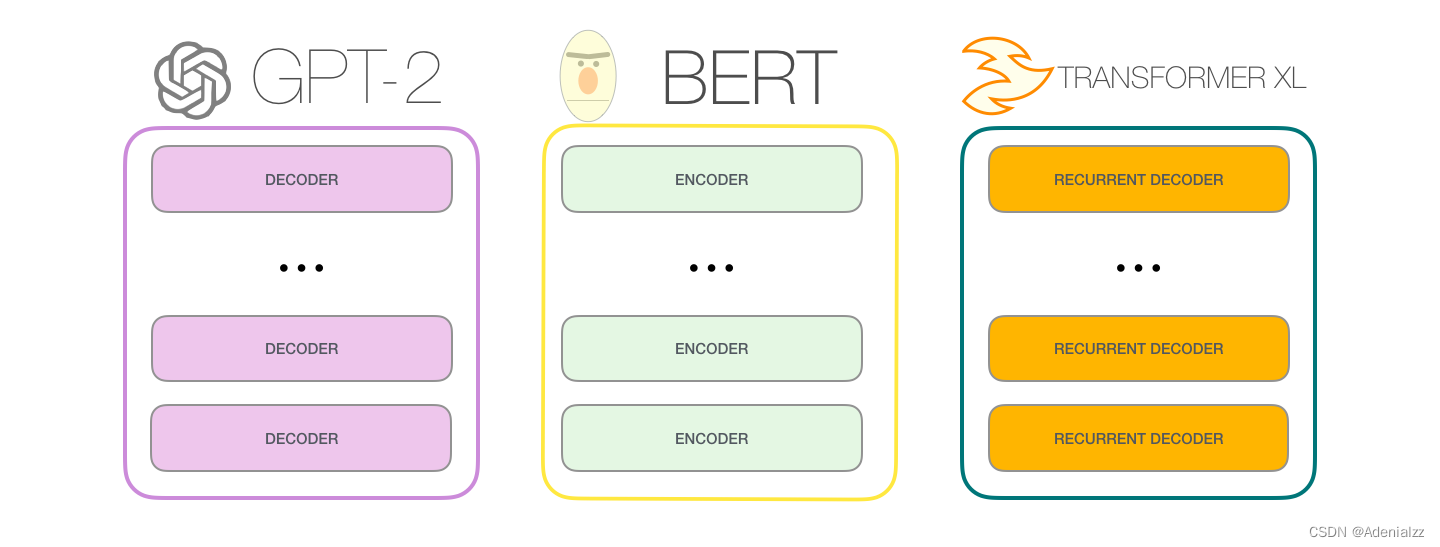
與 BERT 的區別
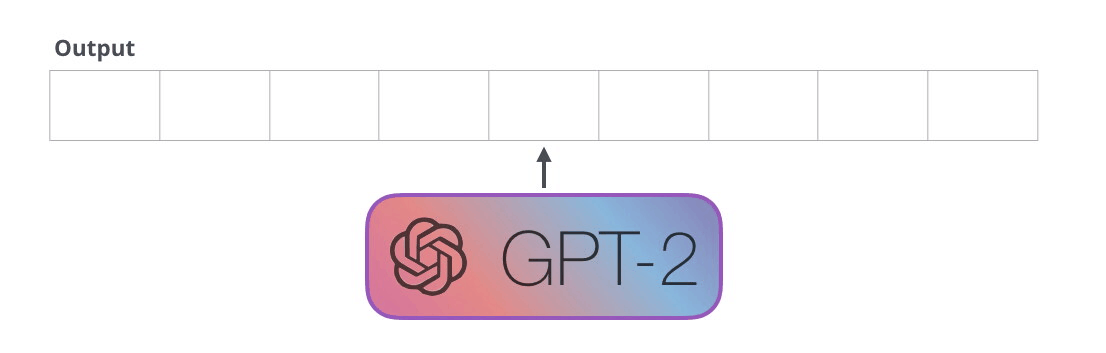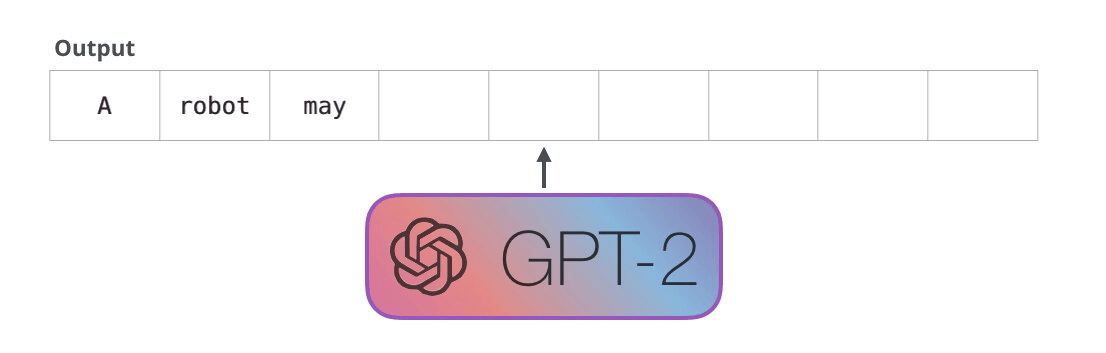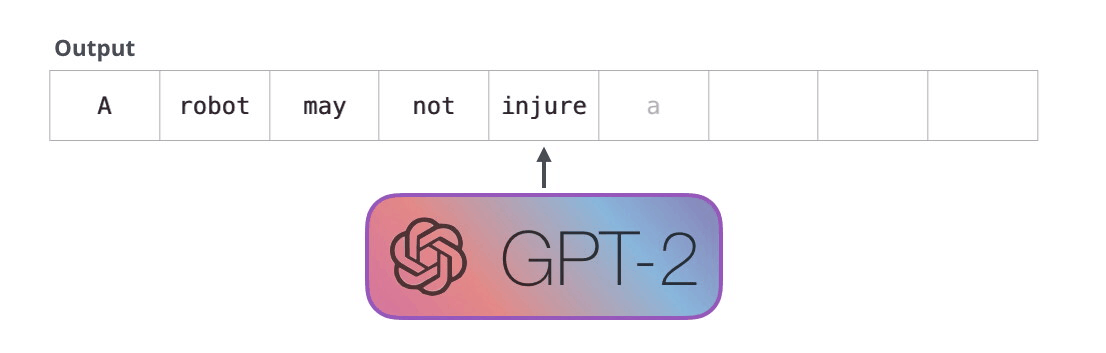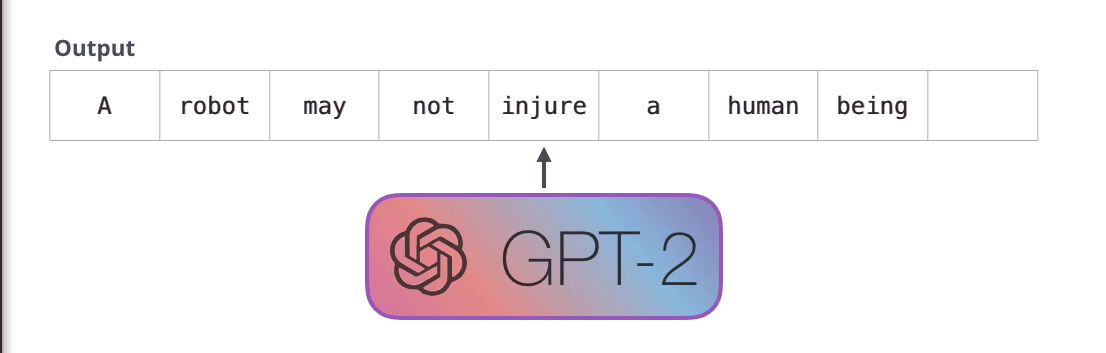
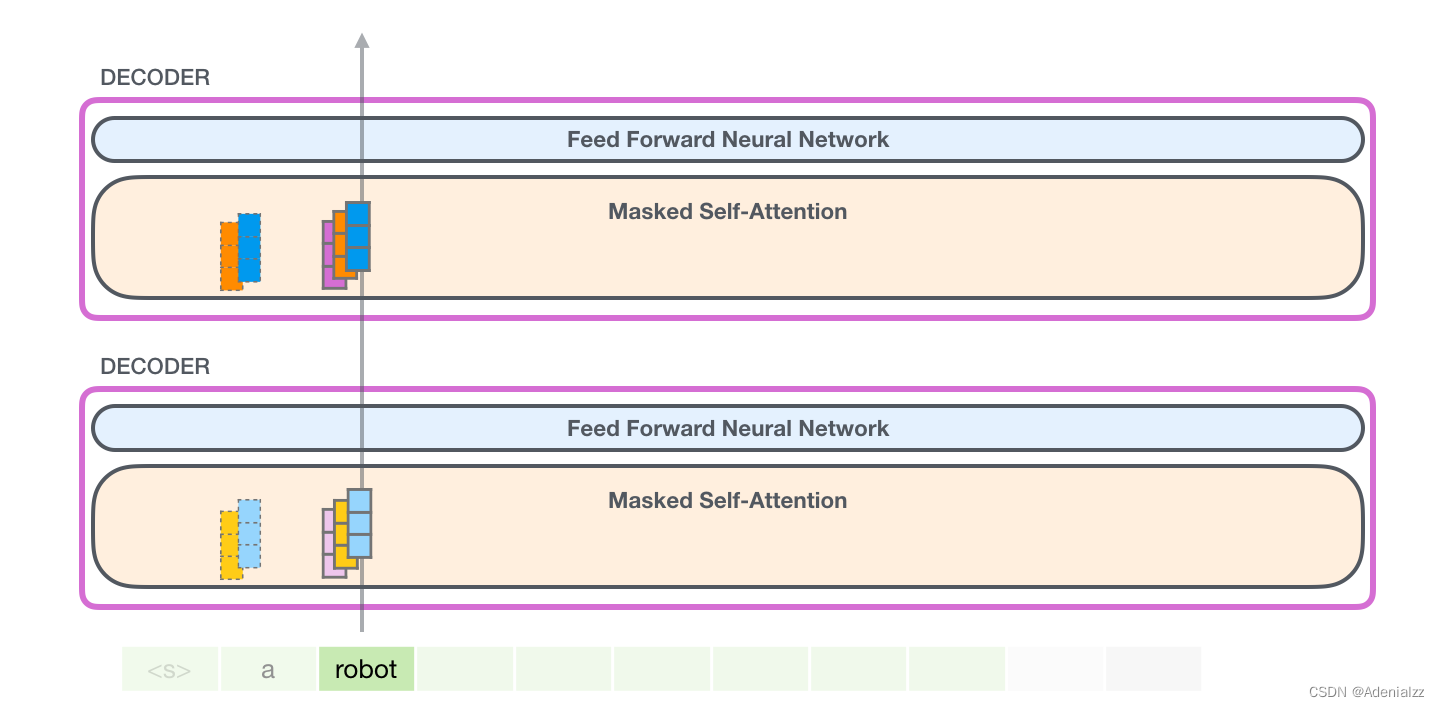
GPT-2 是使用「transformer 解碼器模塊」構建的,而 BERT 則是通過「transformer 編碼器」模塊構建的。我們將在下一節中詳述二者的區別,但這里需要指出的是,二者一個很關鍵的不同之處在于:GPT-2 就像傳統的語言模型一樣,一次只輸出一個單詞(token)。下面是引導訓練好的模型「背誦」機器人第一法則的例子:
這種模型之所以效果好是因為在每個新單詞產生后,該單詞就被添加在之前生成的單詞序列后面,這個序列會成為模型下一步的新輸入。這種機制叫做自回歸(auto-regression),同時也是令 RNN 模型效果拔群的重要思想。
GPT-2,以及一些諸如 TransformerXL 和 XLNet 等后續出現的模型,本質上都是自回歸模型,而 BERT 則不然。這就是一個權衡的問題了。雖然沒有使用自回歸機制,但 BERT 獲得了結合單詞前后的上下文信息的能力,從而取得了更好的效果。XLNet 使用了自回歸,并且引入了一種能夠同時兼顧前后的上下文信息的方法。 Transformer 模塊的演進原始的 transformer 論文引入了兩種類型的 transformer 模塊,分別是:編碼器模塊和解碼器模塊。 編碼器模塊首先是編碼器(encoder)模塊:
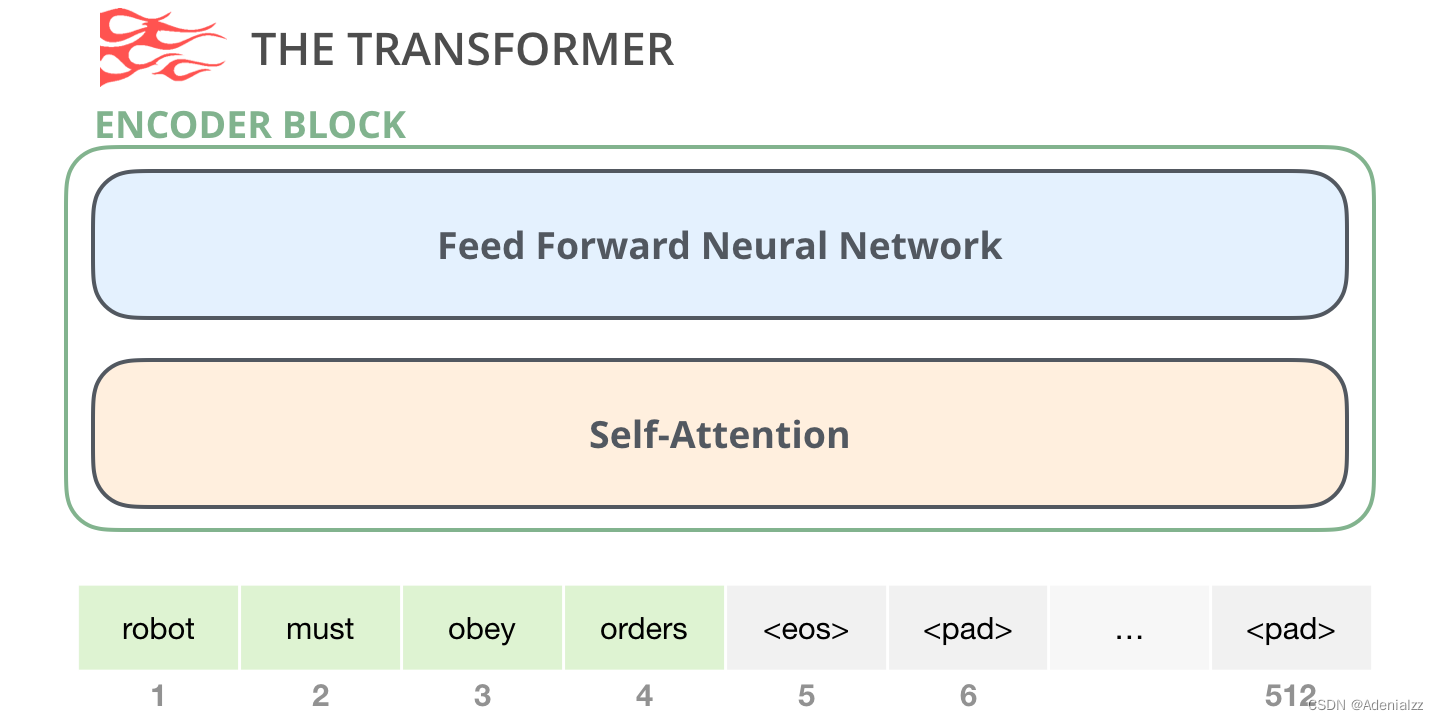
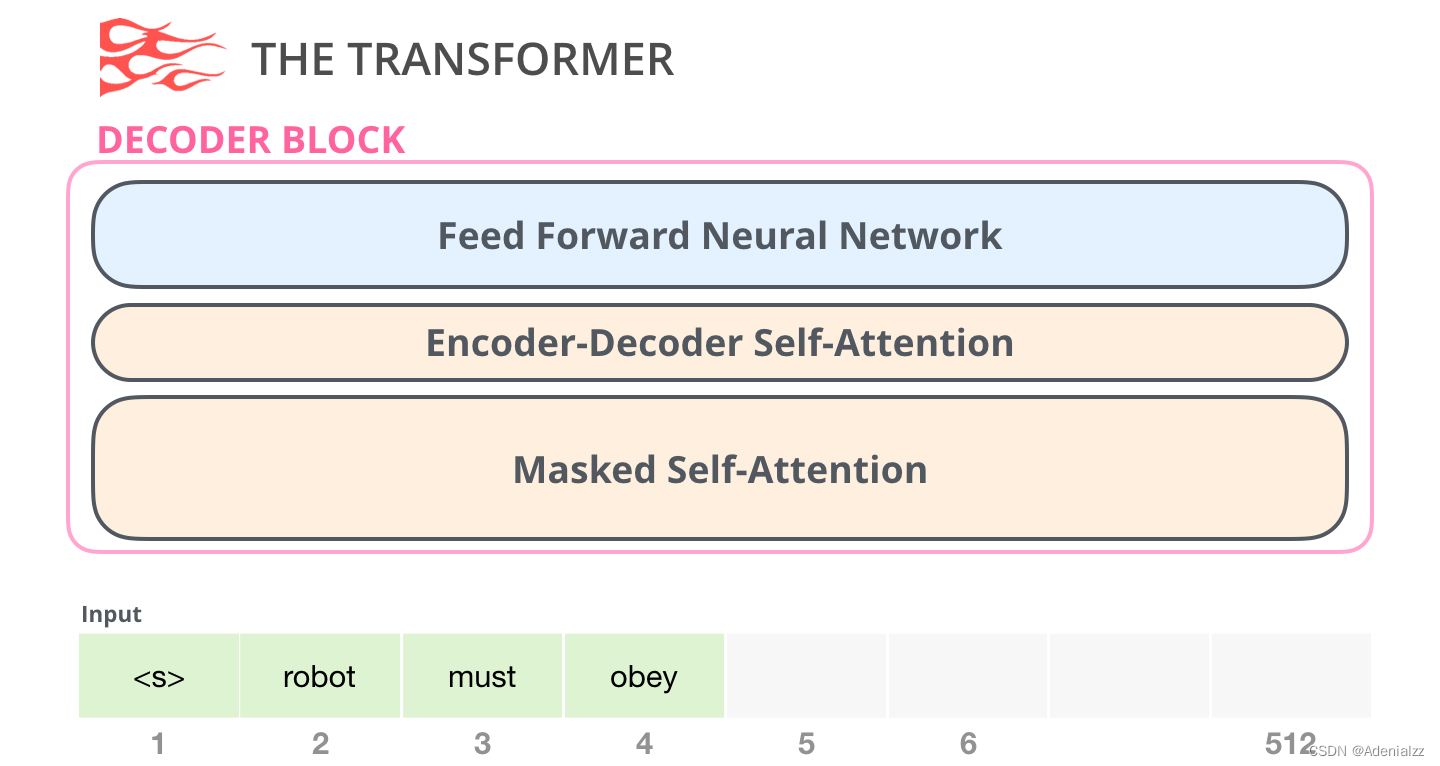
原始 transformer 論文中的編碼器模塊可以接受長度不超過最大序列長度(如 512 個單詞)的輸入。如果序列長度小于該限制,我們就在其后填入預先定義的空白單詞(如上圖中的 解碼器模塊其次是解碼器模塊,它與編碼器模塊在架構上有一點小差異——加入了一層使得它可以重點關注編碼器輸出的某一片段,也就是下圖中的編碼器-解碼器自注意力(encoder-decoder self-attention)層。
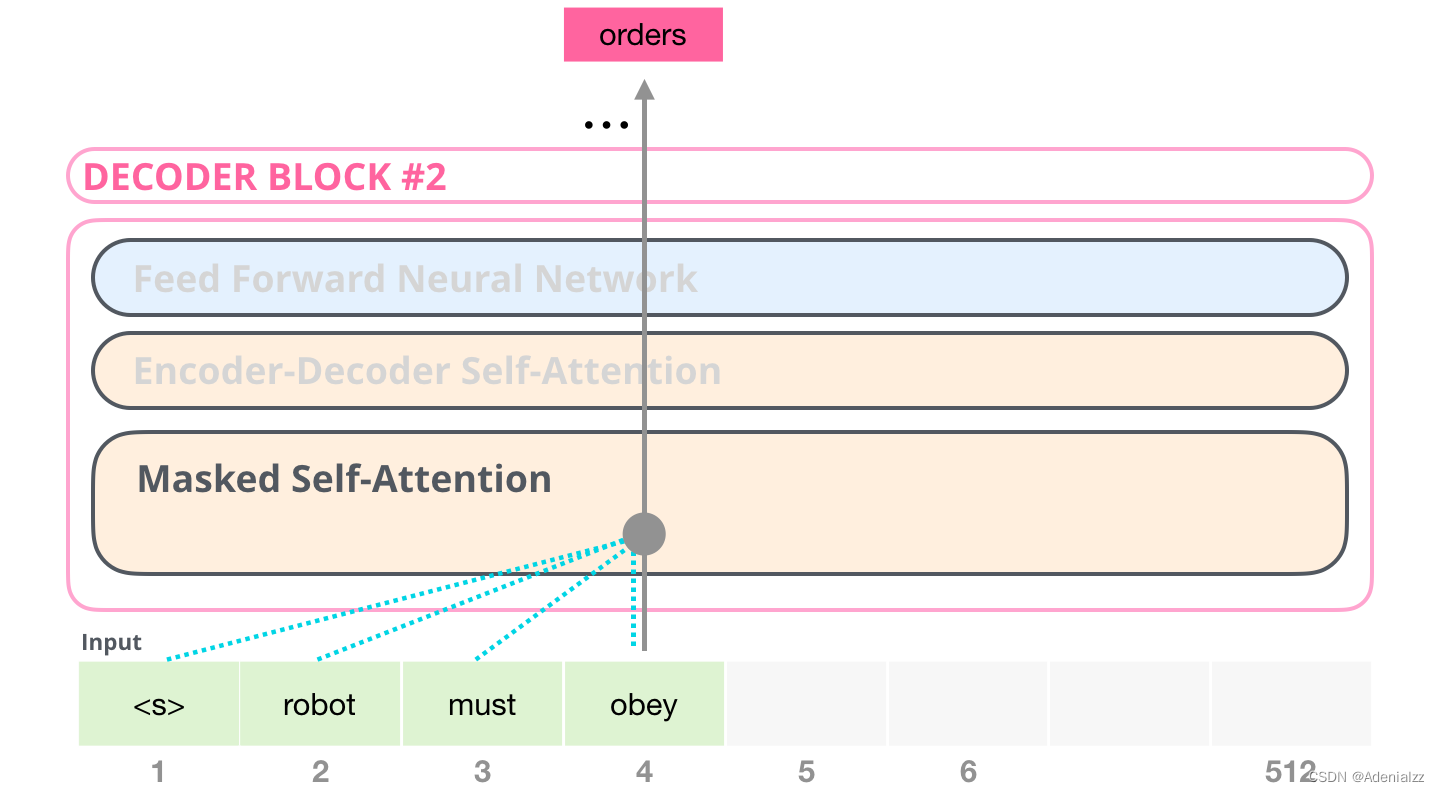
解碼器在自注意力(self-attention)層上還有一個關鍵的差異:它將后面的單詞掩蓋掉了。但并不像 BERT 一樣將它們替換成特殊定義的單詞 舉個例子,如果我們重點關注 4 號位置單詞及其前續路徑,我們可以模型只允許注意當前計算的單詞以及之前的單詞:
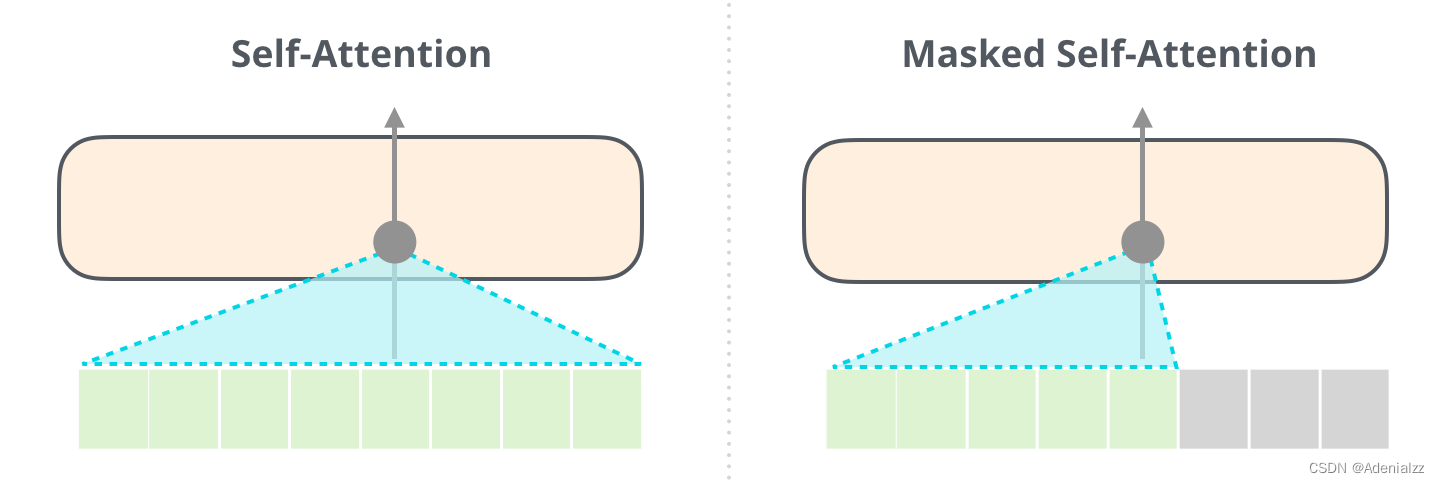
能夠清楚地區分 BERT 使用的自注意力(self-attention)模塊和 GPT-2 使用的帶掩模的自注意力(masked self-attention)模塊很重要。普通的自注意力模塊允許一個位置看到它右側單詞的信息(如下左圖),而帶掩模的自注意力模塊則不允許這么做(如下右圖)。
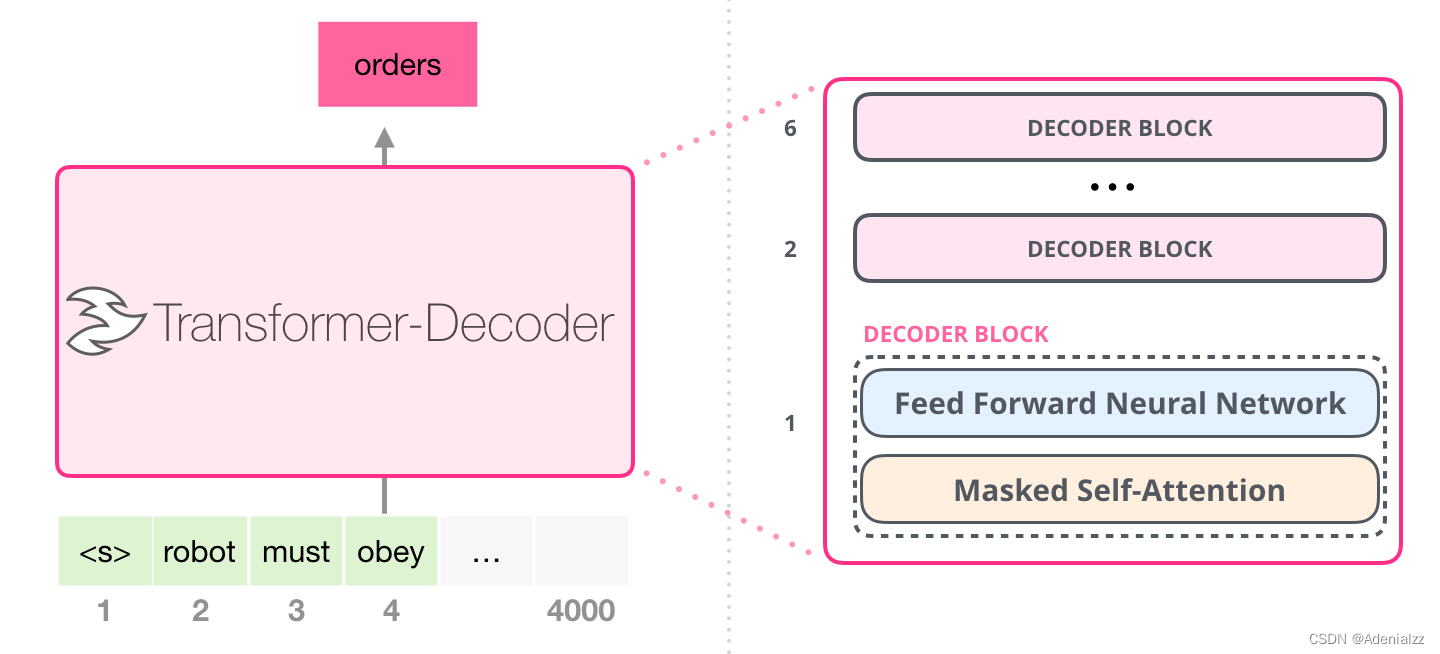
只包含解碼器的模塊在 transformer 原始論文發表之后,一篇名為「Generating Wikipedia by Summarizing Long Sequences」的論文提出用另一種 transformer 模塊的排列方式來進行語言建模——它直接扔掉了所有的 transformer 編碼器模塊……我們姑且就管它叫做「Transformer-Decoder」模型吧。這個早期的基于 transformer 的模型由 6 個 transformer 解碼器模塊堆疊而成:
圖中所有的解碼器模塊都是一樣的,因此本文只展開了第一個解碼器的內部結構。可以看見,它使用了帶掩模的自注意力層。請注意,該模型在某個片段中可以支持最長 4000 個單詞的序列,相較于 transformer 原始論文中最長 512 單詞的限制有了很大的提升。 這些解碼器模塊和 transformer 原始論文中的解碼器模塊相比,除了去除了第二個自注意力層之外,并無很大不同。一個相似的架構在字符級別的語言建模中也被驗證有效,它使用更深的自注意力層構建語言模型,一次預測一個字母/字符。 OpenAI 的 GPT-2 模型就用了這種只包含編碼器(decoder-only)的模塊。 GPT-2 內部機制速成
接下來,我們將深入剖析 GPT-2 的內部結構,看看它是如何工作的。
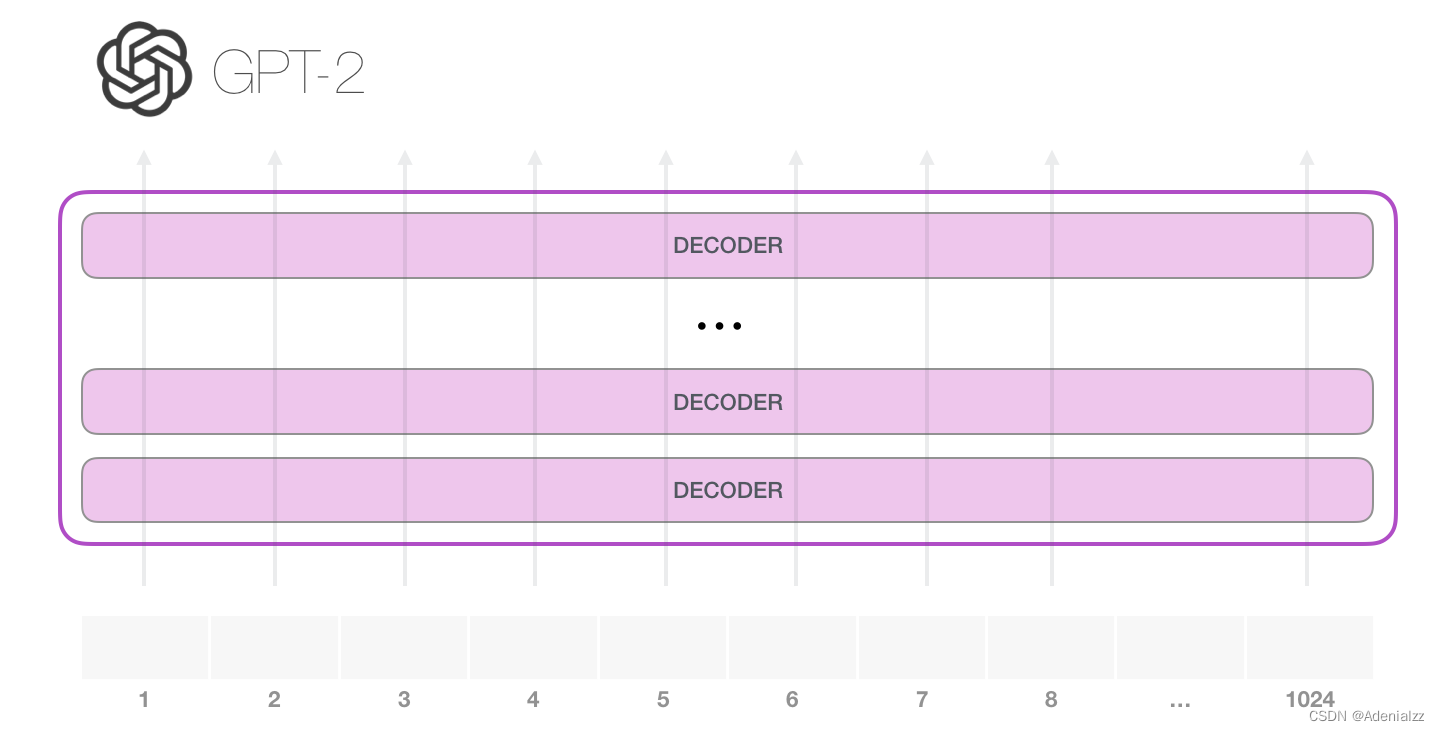
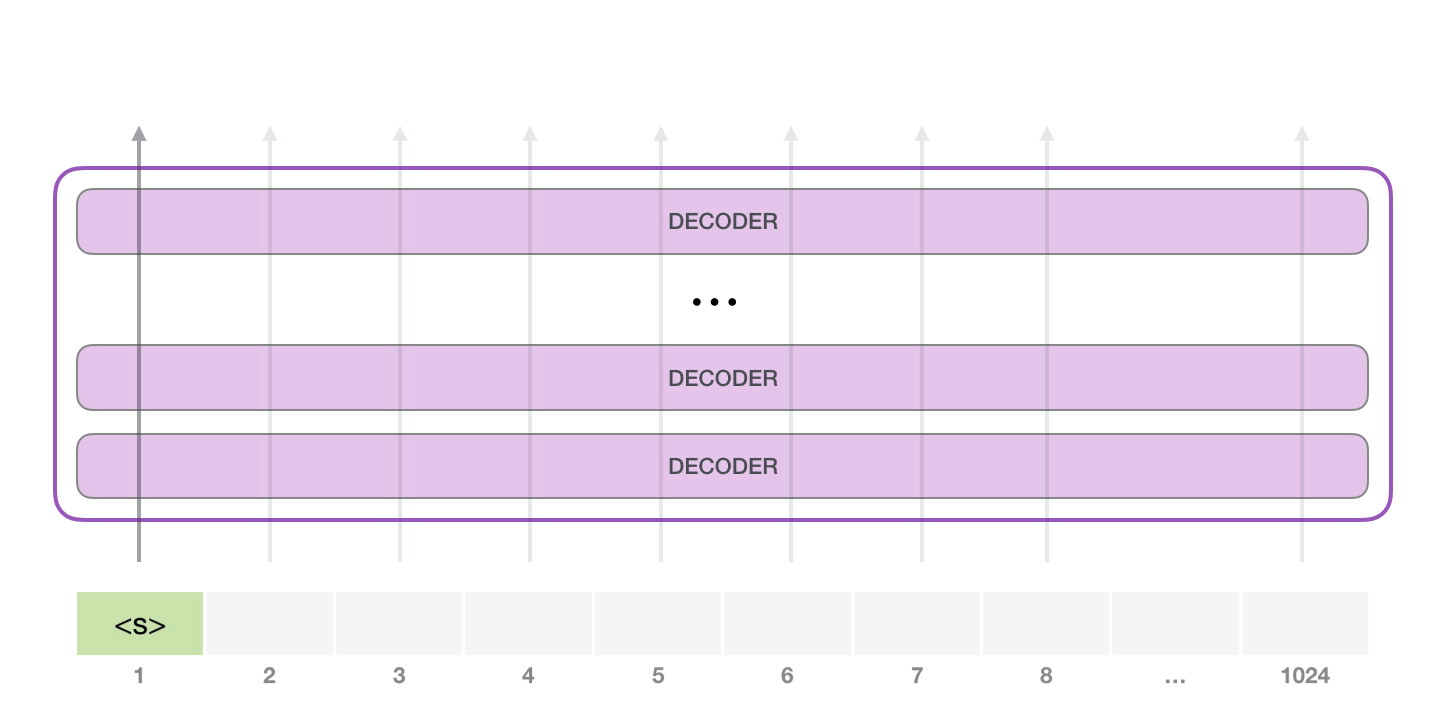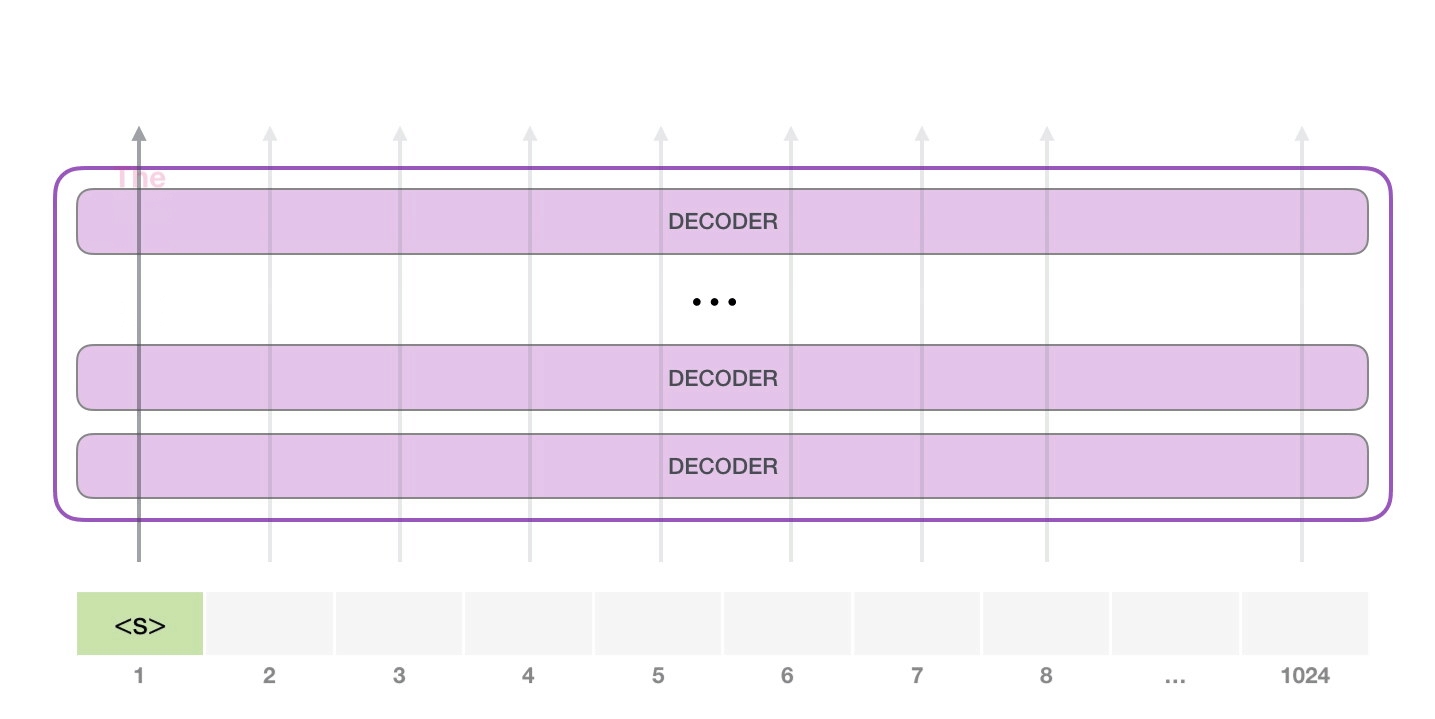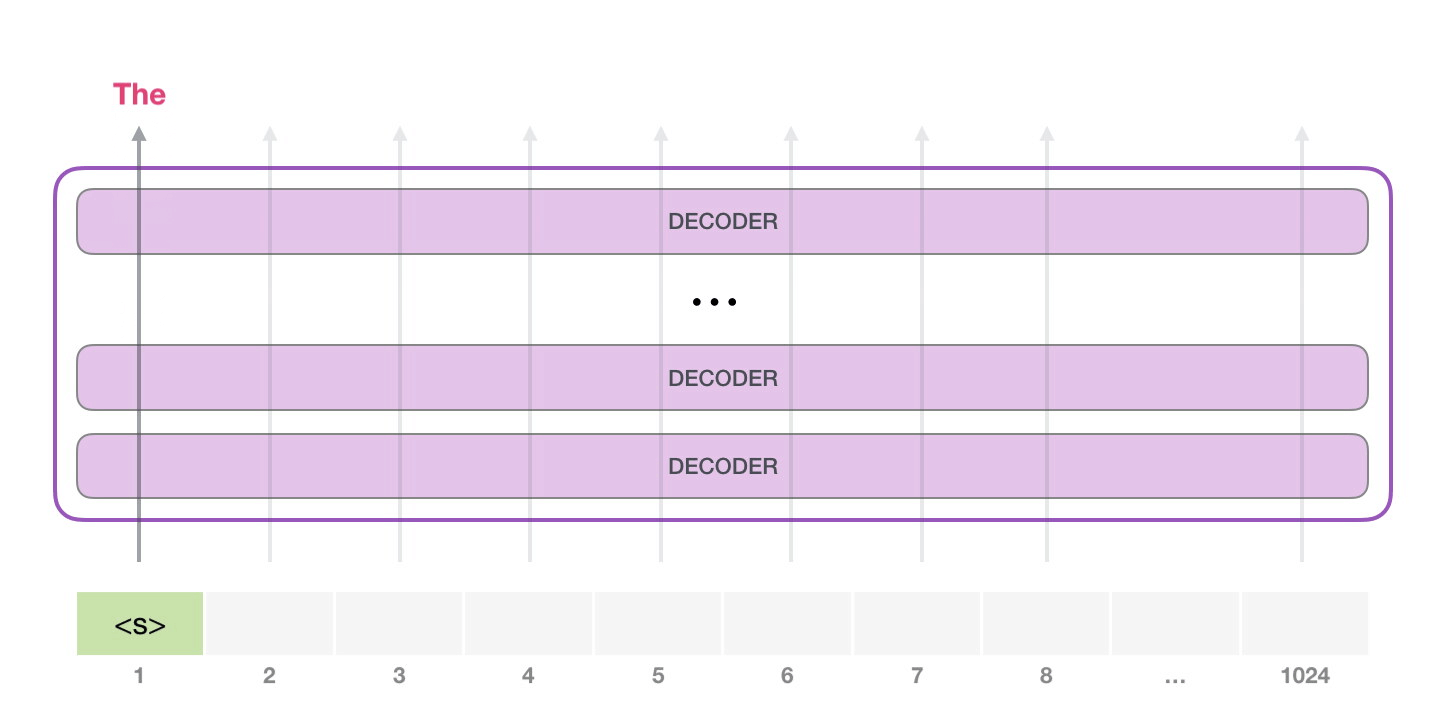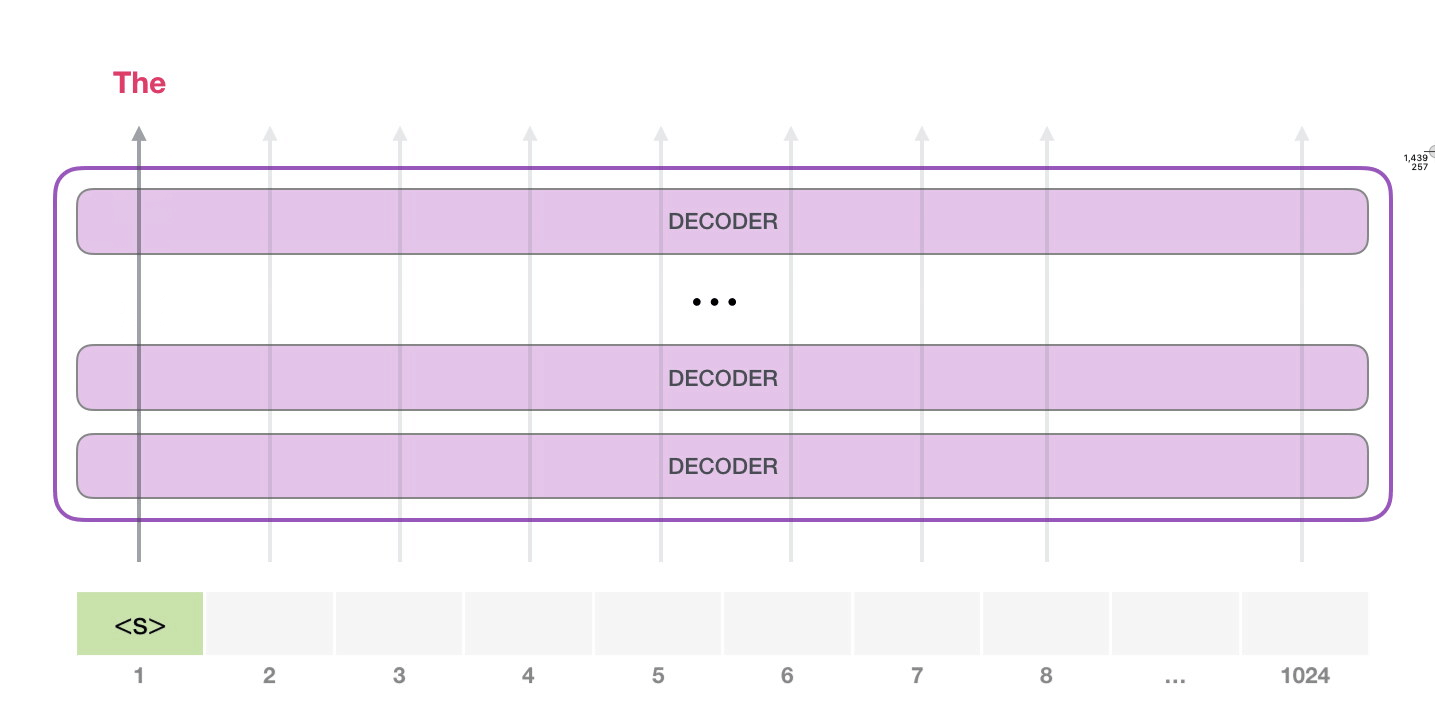
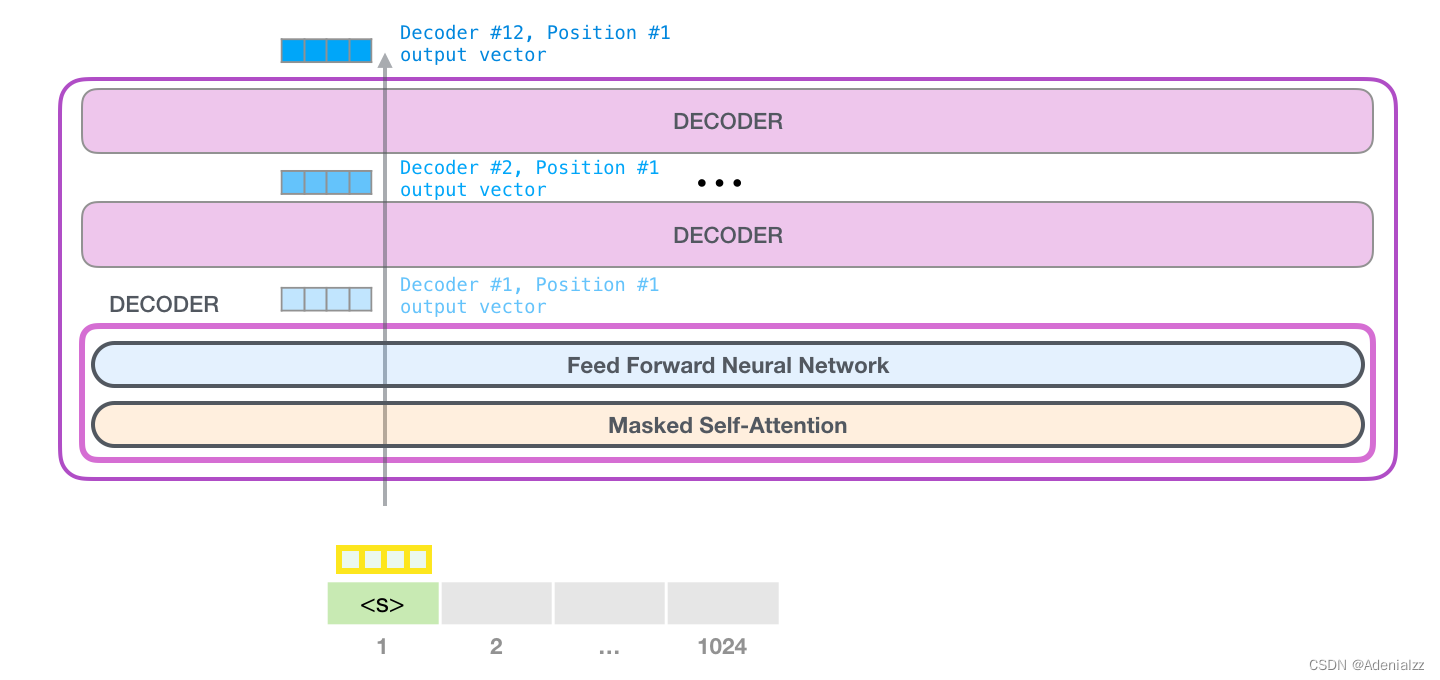
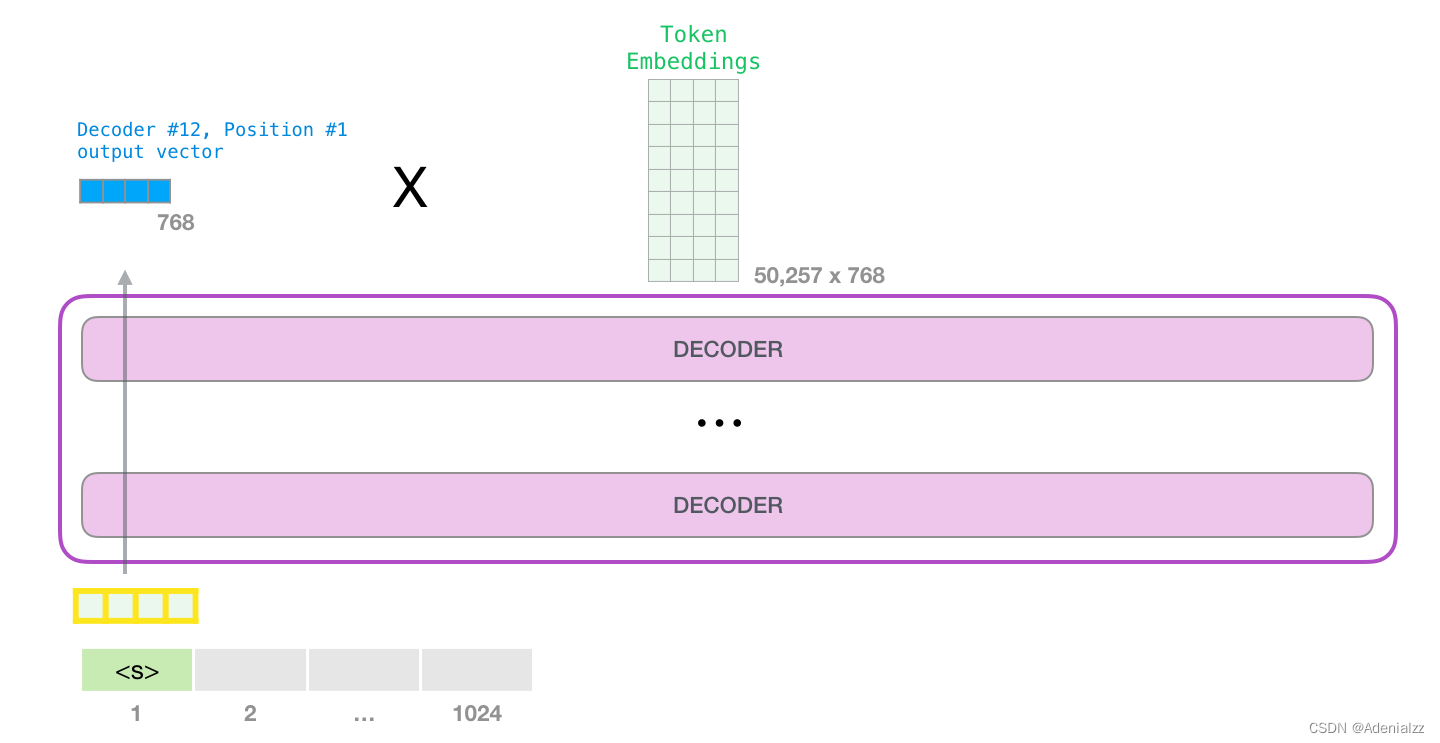
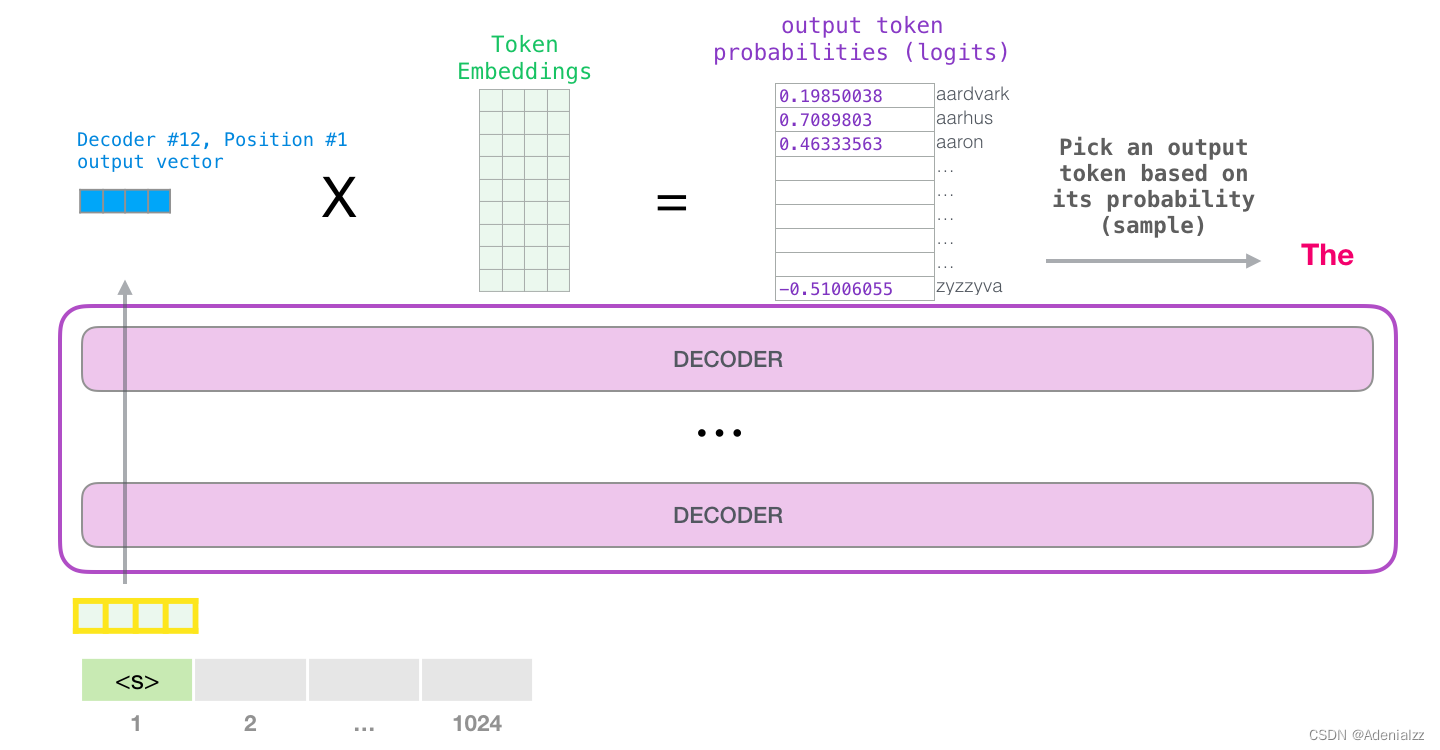
GPT-2 可以處理最長 1024 個單詞的序列。每個單詞都會和它的前續路徑一起「流過」所有的解碼器模塊。 想要運行一個訓練好的 GPT-2 模型,最簡單的方法就是讓它自己隨機工作(從技術上說,叫做生成無條件樣本)。換句話說,我們也可以給它一點提示,讓它說一些關于特定主題的話(即生成交互式條件樣本)。在隨機情況下,我們只簡單地提供一個預先定義好的起始單詞(訓練好的模型使用 此時,模型的輸入只有一個單詞,所以只有這個單詞的路徑是活躍的。單詞經過層層處理,最終得到一個向量。向量可以對于詞匯表的每個單詞計算一個概率(詞匯表是模型能「說出」的所有單詞,GPT-2 的詞匯表中有 50000 個單詞)。在本例中,我們選擇概率最高的單詞「The」作為下一個單詞。 但有時這樣會出問題——就像如果我們持續點擊輸入法推薦單詞的第一個,它可能會陷入推薦同一個詞的循環中,只有你點擊第二或第三個推薦詞,才能跳出這種循環。同樣的,GPT-2 也有一個叫做「top-k」的參數,模型會從概率前 k 大的單詞中抽樣選取下一個單詞。顯然,在之前的情況下,top-k = 1。
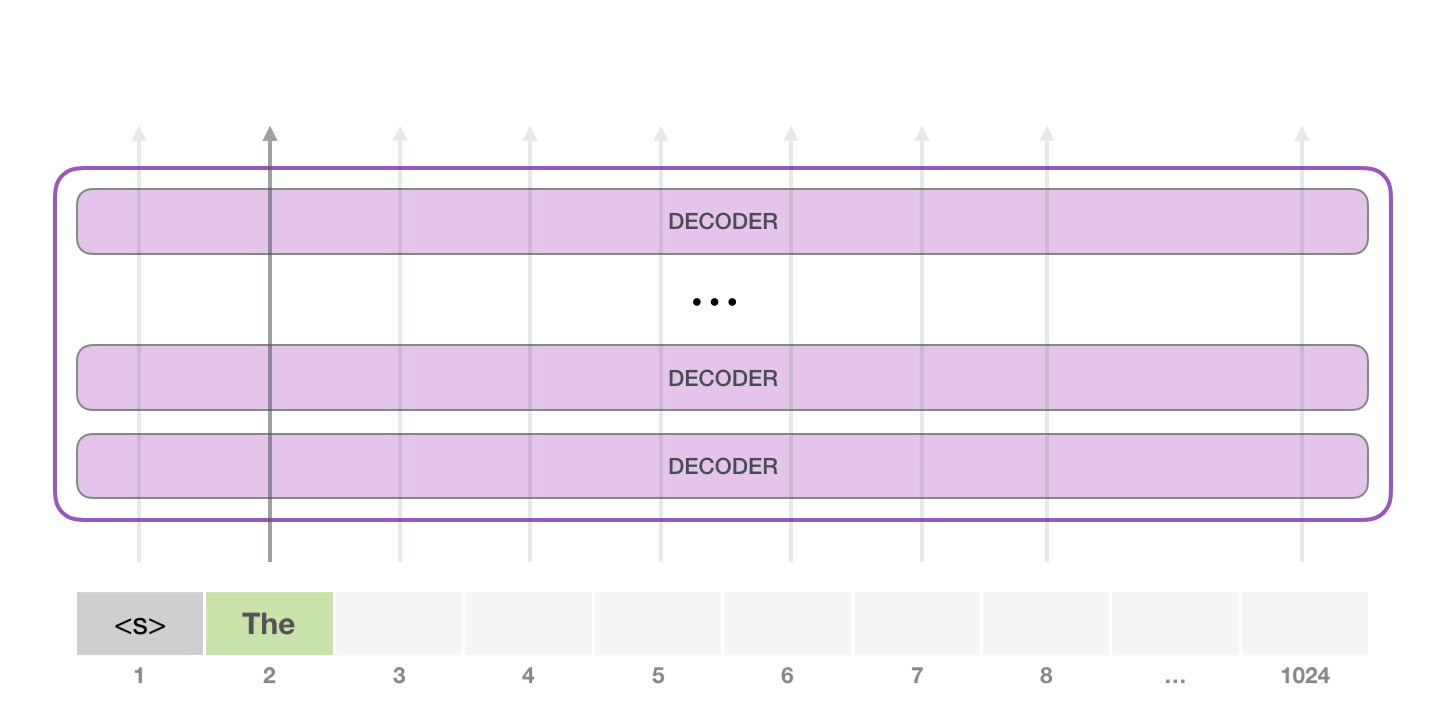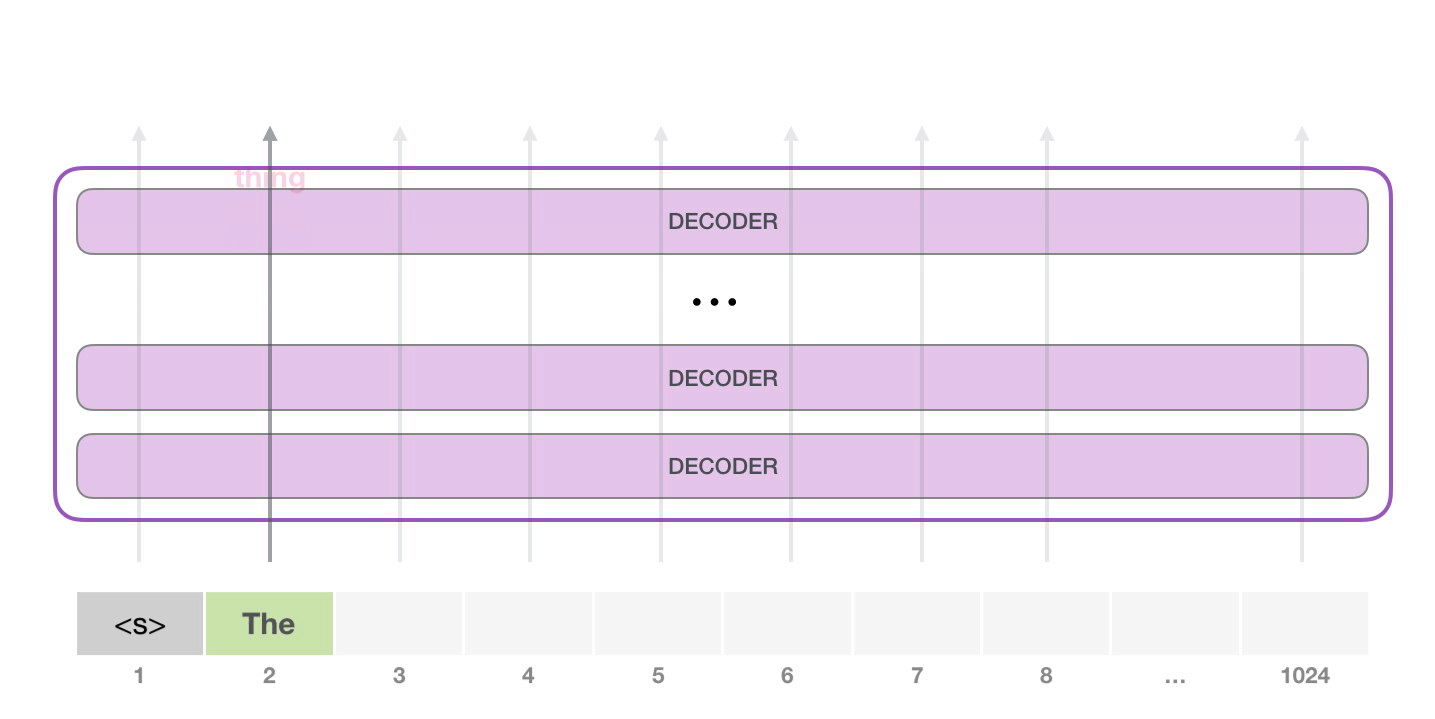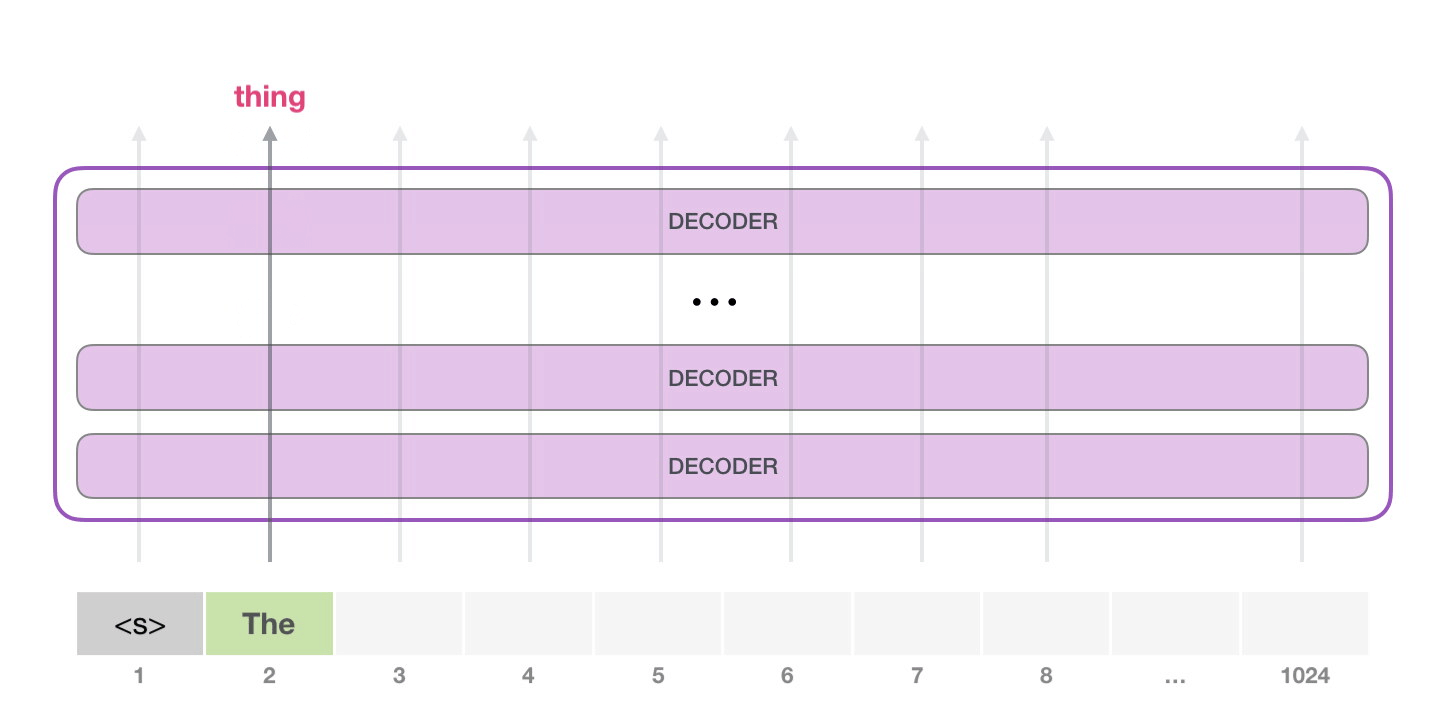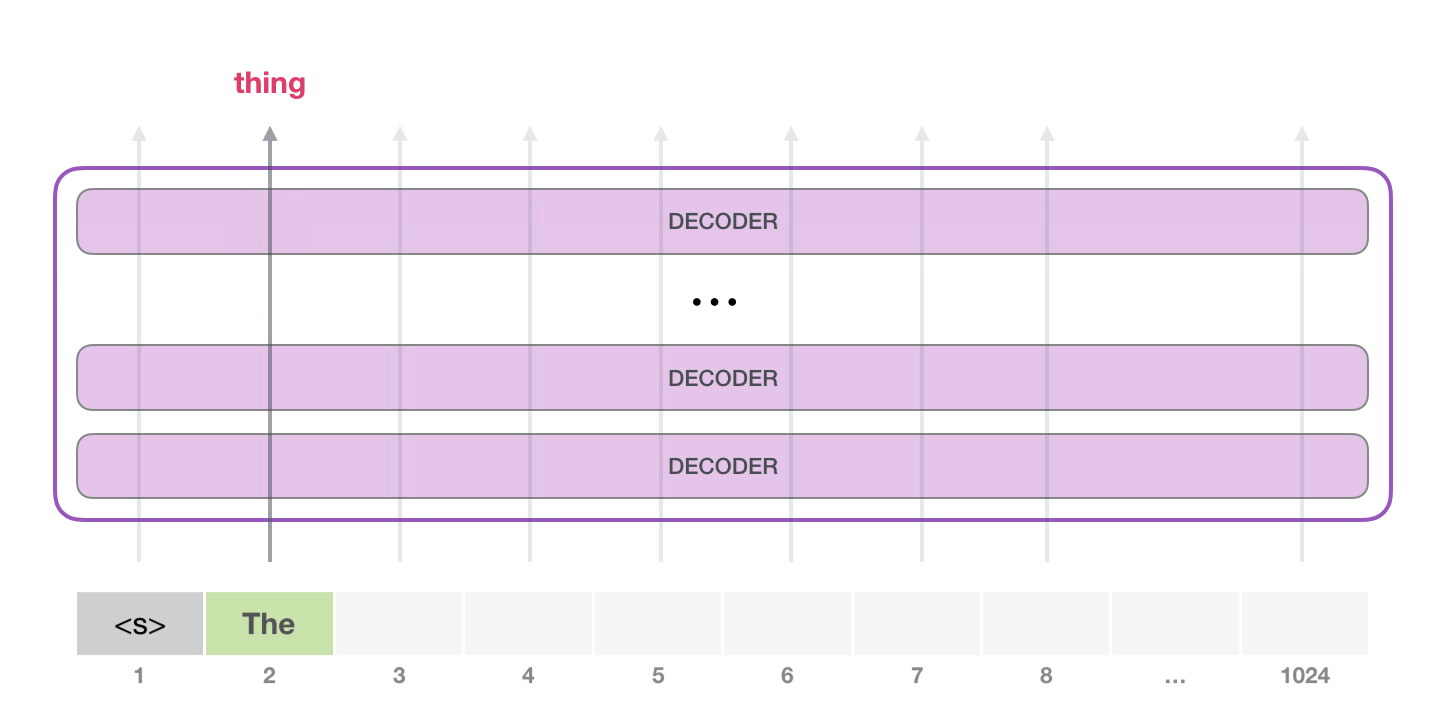
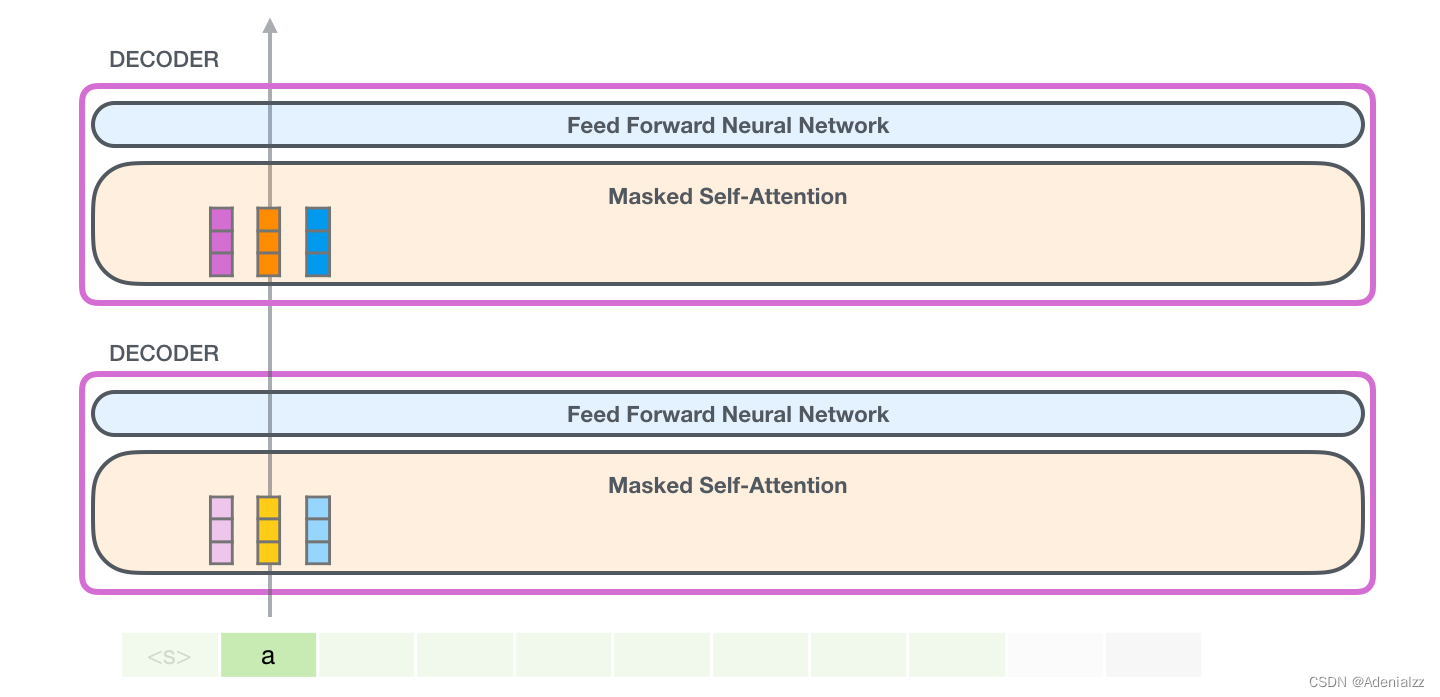
接下來,我們將輸出的單詞添加在輸入序列的尾部構建新的輸入序列,讓模型進行下一步的預測:
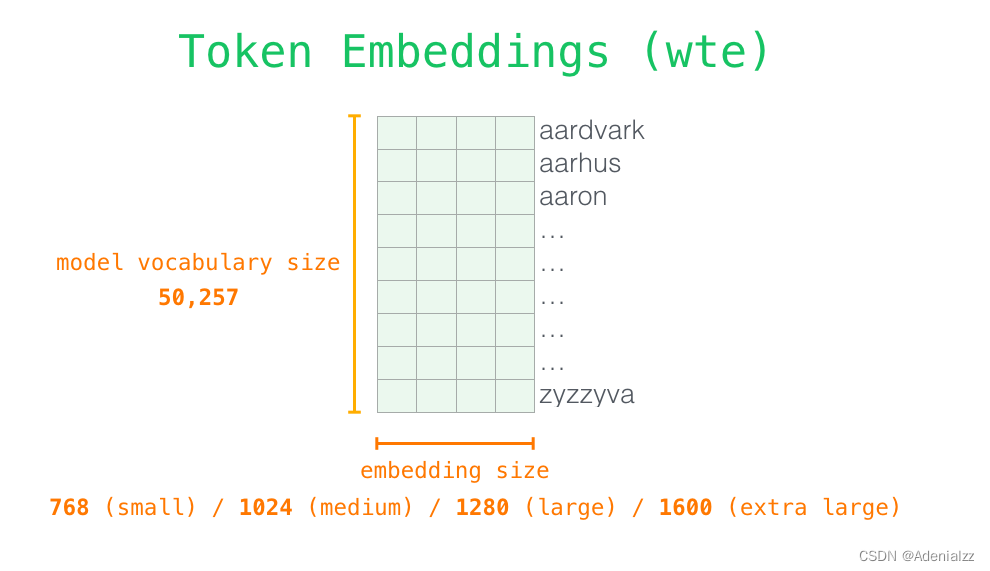
請注意,第二個單詞的路徑是當前唯一活躍的路徑了。GPT-2 的每一層都保留了它們對第一個單詞的解釋,并且將運用這些信息處理第二個單詞(具體將在下面一節對自注意力機制的講解中詳述),GPT-2 不會根據第二個單詞重新解釋第一個單詞。 更加深入了解內部原理輸入編碼讓我們更加深入地了解一下模型的內部細節。首先,讓我們從模型的輸入開始。正如我們之前討論過的其它自然語言處理模型一樣,GPT-2 同樣從嵌入矩陣中查找單詞對應的嵌入向量,該矩陣也是模型訓練結果的一部分。
每一行都是一個詞嵌入向量:一個能夠表征某個單詞,并捕獲其意義的數字列表。嵌入向量的長度和 GPT-2 模型的大小有關,最小的模型使用了長為 768 的嵌入向量來表征一個單詞。 所以在一開始,我們需要在嵌入矩陣中查找起始單詞
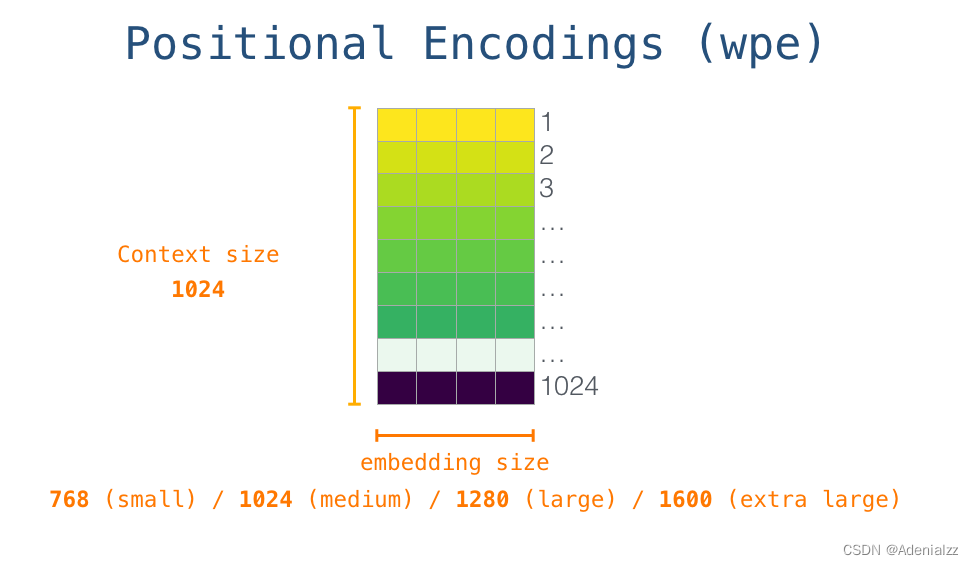
至此,輸入單詞在進入模型第一個 transformer 模塊之前所有的處理步驟就結束了。如上文所述,訓練后的 GPT-2 模型包含兩個權值矩陣:嵌入矩陣和位置編碼矩陣。
將單詞輸入第一個 transformer 模塊之前需要查到它對應的嵌入向量,再加上 1 號位置位置對應的位置向量。 堆棧之旅第一個 transformer 模塊處理單詞的步驟如下:首先通過自注意力層處理,接著將其傳遞給神經網絡層。第一個 transformer 模塊處理完但此后,會將結果向量被傳入堆棧中的下一個 transformer 模塊,繼續進行計算。每一個 transformer 模塊的處理方式都是一樣的,但每個模塊都會維護自己的自注意力層和神經網絡層中的權重。
回顧自注意力機制語言的含義是極度依賴上下文的,比如下面這個機器人第二法則:
我在這句話中高亮表示了三個地方,這三處單詞指代的是其它單詞。除非我們知道這些詞指代的上下文聯系起來,否則根本不可能理解或處理這些詞語的意思。當模型處理這句話的時候,它必須知道:
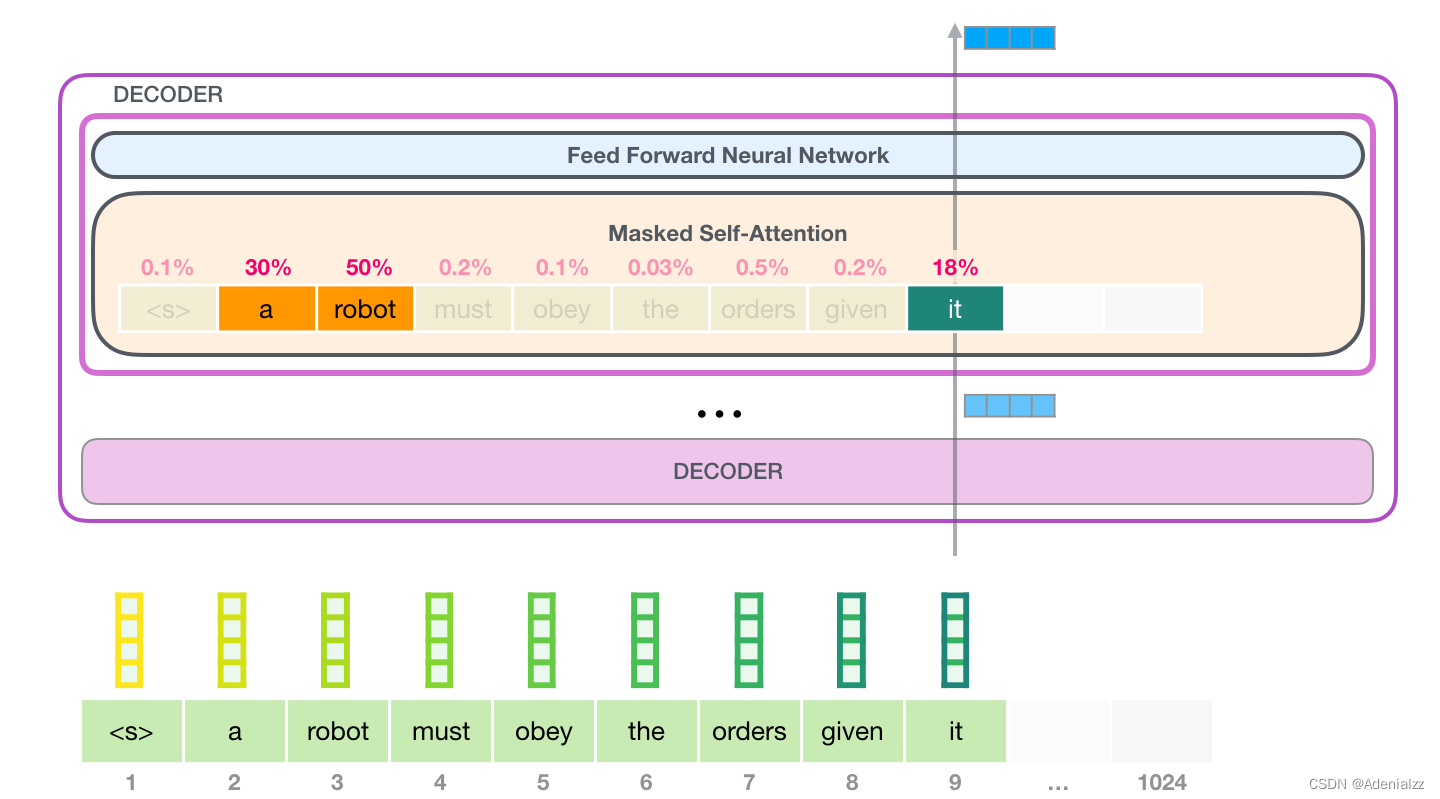
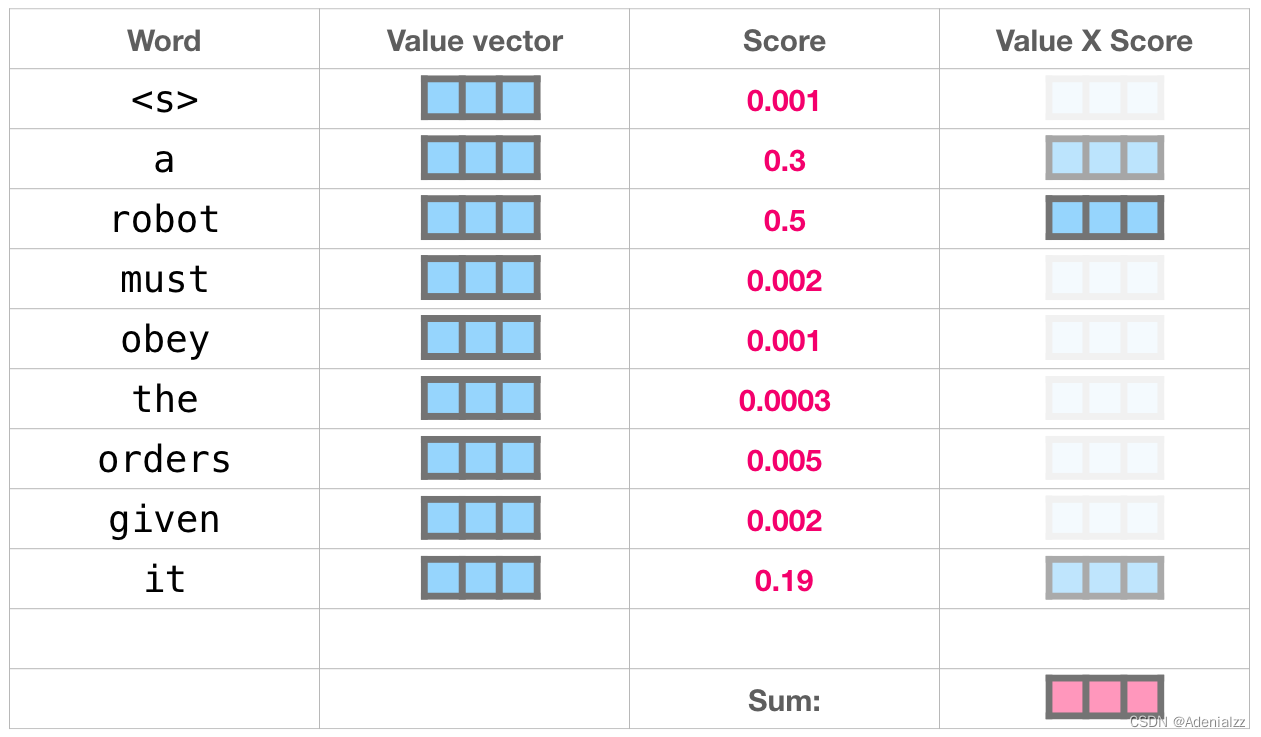
這就是自注意力機制所做的工作,它在處理每個單詞(將其傳入神經網絡)之前,融入了模型對于用來解釋某個單詞的上下文的相關單詞的理解。具體做法是,給序列中每一個單詞都賦予一個相關度得分,之后對他們的向量表征求和。 舉個例子,最上層的 transformer 模塊在處理單詞「it」的時候會關注「a robot」,所以「a」、「robot」、「it」這三個單詞與其得分相乘加權求和后的特征向量會被送入之后的神經網絡層。
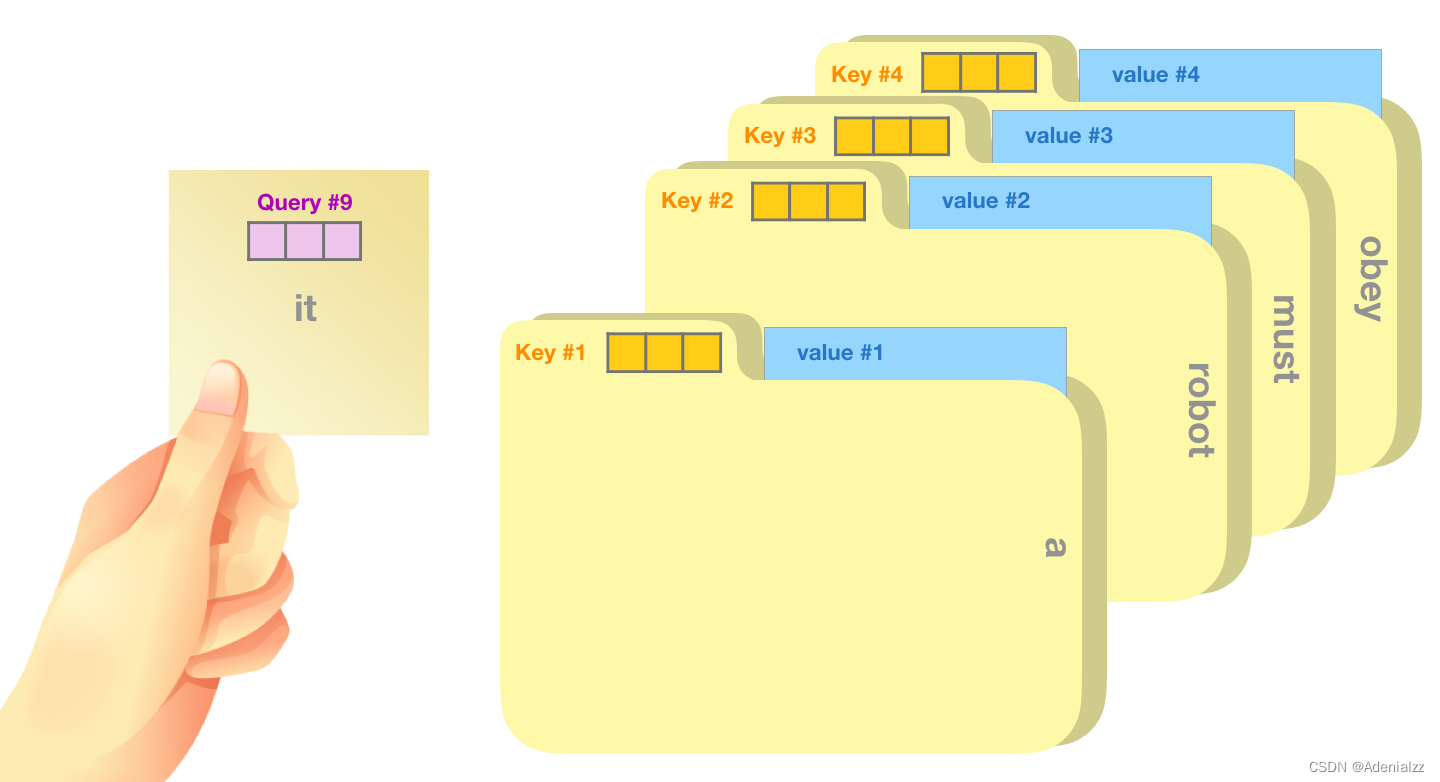
自注意力機制沿著序列中每一個單詞的路徑進行處理,主要由 3 個向量組成:
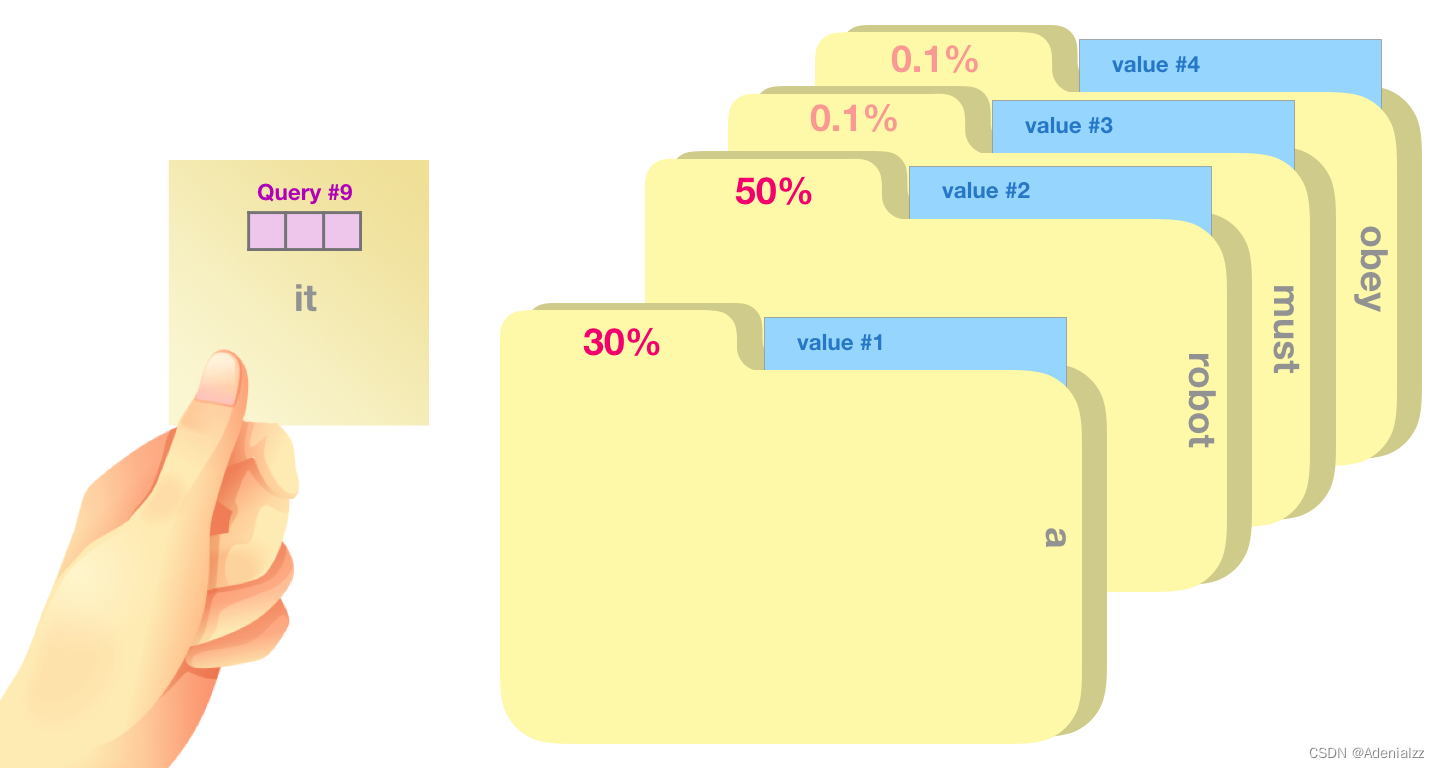
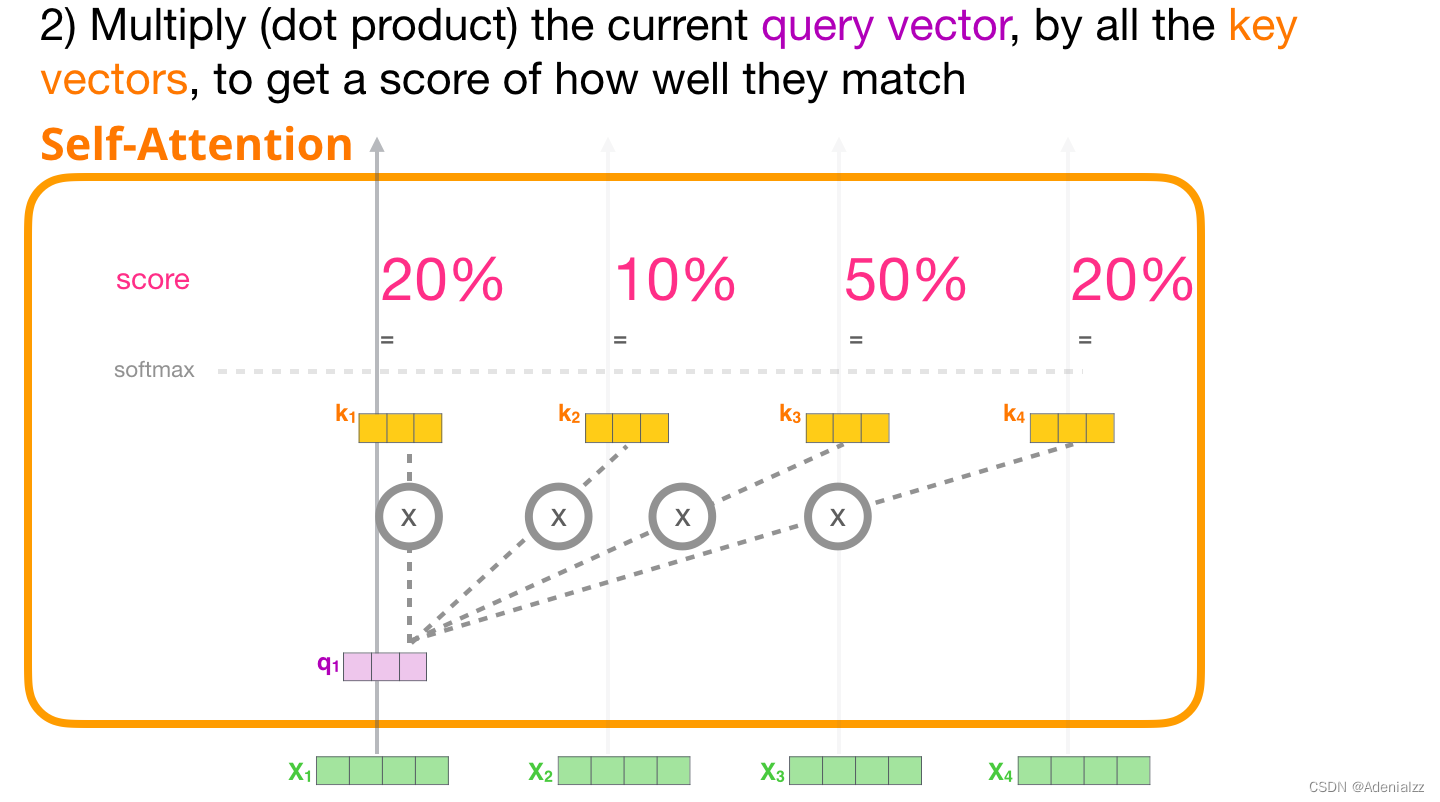
一個簡單粗暴的比喻是在檔案柜中找文件。查詢向量就像一張便利貼,上面寫著你正在研究的課題。鍵向量像是檔案柜中文件夾上貼的標簽。當你找到和便利貼上所寫相匹配的文件夾時,拿出它,文件夾里的東西便是值向量。只不過我們最后找的并不是單一的值向量,而是很多文件夾值向量的混合。 將單詞的查詢向量分別乘以每個文件夾的鍵向量,得到各個文件夾對應的注意力得分(這里的乘指的是向量點乘,乘積會通過 softmax 函數處理)。
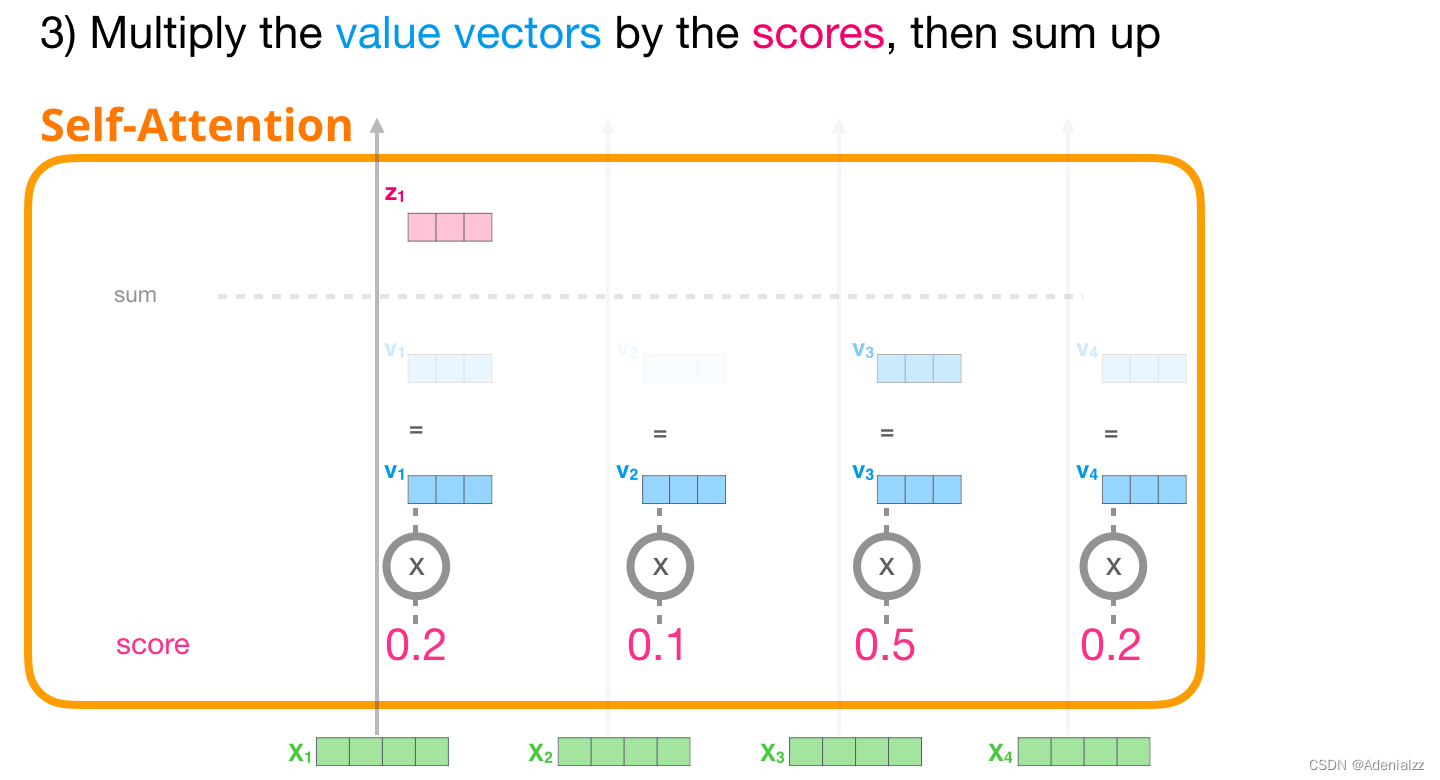
我們將每個文件夾的值向量乘以其對應的注意力得分,然后求和,得到最終自注意力層的輸出。
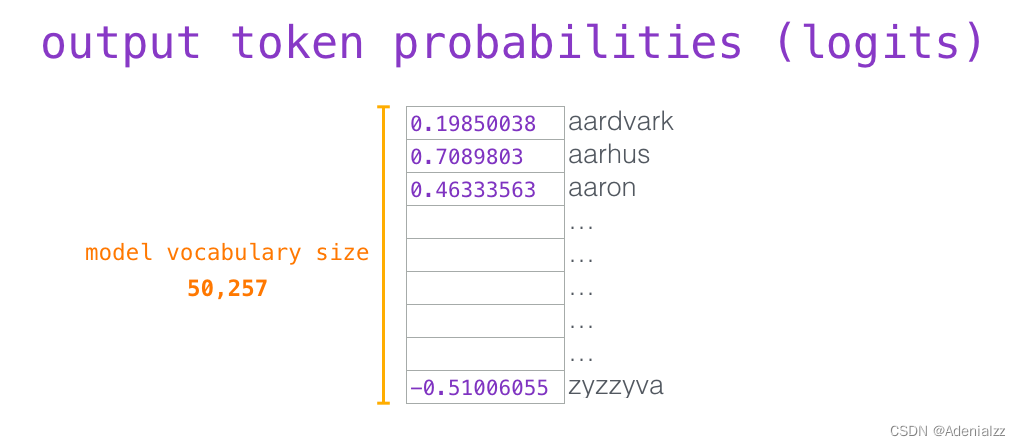
這樣將值向量加權混合得到的結果是一個向量,它將其 50% 的「注意力」放在了單詞「robot」上,30% 的注意力放在了「a」上,還有 19% 的注意力放在「it」上。我們之后還會更詳細地講解自注意力機制,讓我們先繼續向前探索 transformer 堆棧,看看模型的輸出。 模型輸出當最后一個 transformer 模塊產生輸出之后(即經過了它自注意力層和神經網絡層的處理),模型會將輸出的向量乘上嵌入矩陣。
我們知道,嵌入矩陣的每一行都對應模型的詞匯表中一個單詞的嵌入向量。所以這個乘法操作得到的結果就是詞匯表中每個單詞對應的注意力得分。
我們簡單地選取得分最高的單詞作為輸出結果(即 top-k = 1)。但其實如果模型考慮其他候選單詞的話,效果通常會更好。所以,一個更好的策略是對于詞匯表中得分較高的一部分單詞,將它們的得分作為概率從整個單詞列表中進行抽樣(得分越高的單詞越容易被選中)。通常一個折中的方法是,將 top-k 設為 40,這樣模型會考慮注意力得分排名前 40 位的單詞。
這樣,模型就完成了一輪迭代,輸出了一個單詞。模型會接著不斷迭代,直到生成一個完整的序列——序列達到 1024 的長度上限或序列中產生了一個終止符。 第一部分結語:大家好,這就是 GPT-2 本文是 GPT-2 模型工作原理的一個概覽。如果你還是對自注意力層內部深層的細節很好奇,請繼續關注機器之心的系列文章。我們將引入更多可視化語言來試著解釋自注意力層的工作原理,同時也是為了能夠更好地描述之后基于 transformer 的模型(說的就是你們,TransformerXL 還有 XLNet)。 這篇文章中有一些過分簡化的地方:
第二部分:圖解自注意力機制在前面的文章中,我們用這張圖來展示了自注意力機制在處理單詞「it」的層中的應用:
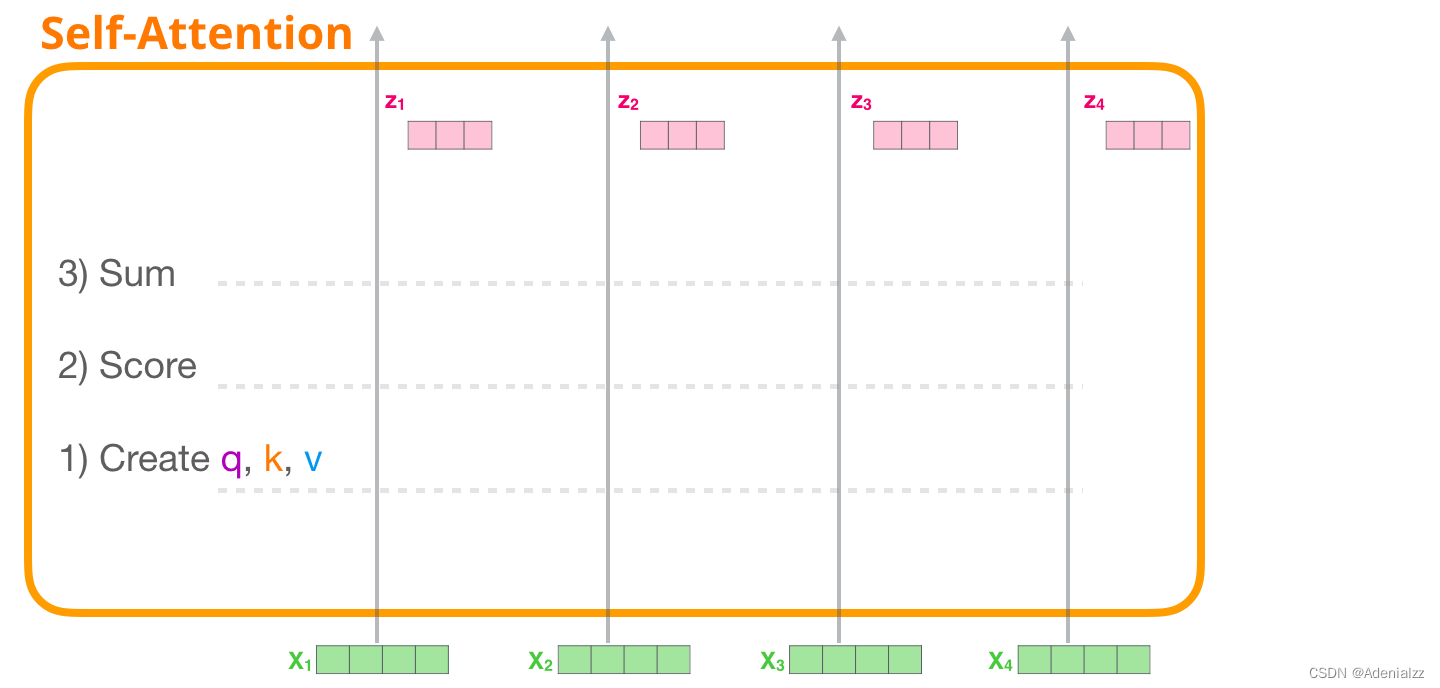
在本節中,我們會詳細介紹該過程是如何實現的。請注意,我們將會以試圖弄清單個單詞被如何處理的角度來看待這個問題。這也是我們會展示許多單個向量的原因。這實際上是通過將巨型矩陣相乘來實現的。但是我想直觀地看看,在單詞層面上發生了什么。 自注意力機制(不使用掩模)首先,我們將介紹原始的自注意力機制,它是在編碼器模塊里計算的。先看一個簡易的 transformer 模塊,它一次只能處理 4 個詞(token)。 自注意力機制通過以下三個主要步驟來實現:
1 創建查詢、鍵和值向量我們重點關注第一條路徑。我們用它的查詢值與其它所有的鍵向量進行比較,這使得每個鍵向量都有一個對應的注意力得分。自注意力機制的第一步就是為每個詞(token)路徑(我們暫且忽略注意力頭)計算三個向量:查詢向量、鍵向量、值向量。
2 注意力得分計算出上述三個向量后,我們在第二步中只用查詢向量和鍵向量。我們重點關注第一個詞,將它的查詢向量與其它所有的鍵向量相乘,得到四個詞中的每個詞的注意力得分。
3 求和現在,我們可以將注意力得分與值向量相乘。在我們對其求和后,注意力得分較高的值將在結果向量中占很大的比重。
注意力得分越低,我們在圖中顯示的值向量就越透明。這是為了表明乘以一個小的數是如何削弱向量值的影響的。 如果我們在每一個路徑都執行相同的操作,最終會得到一個表征每個詞的向量,它包括了這個詞的適當的上下文,然后將這些信息在 transformer 模塊中傳遞給下一個子層(前饋神經網絡):
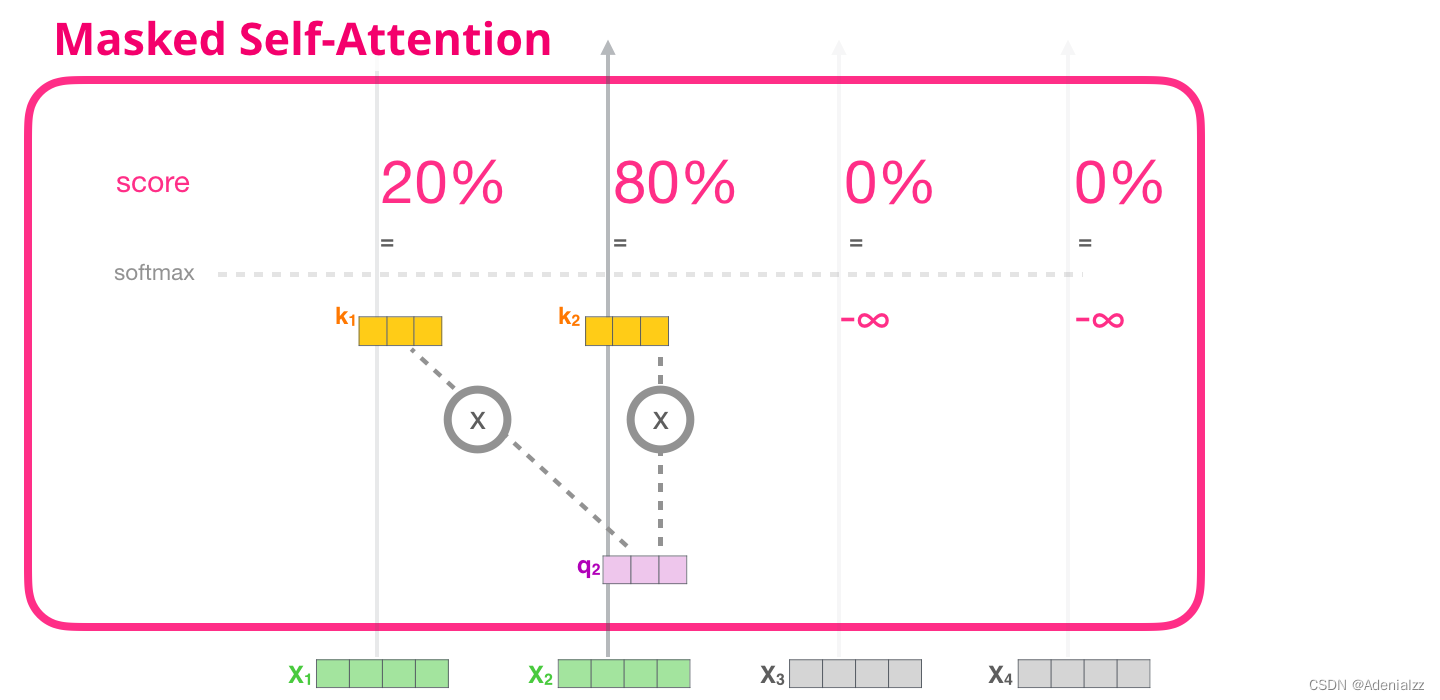
圖解掩模自注意力機制現在我們已經介紹了 transformer 模塊中自注意力機制的步驟,接下來我們介紹掩模自注意力機制(masked self-attention)。在掩模自注意力機制中,除了第二步,其余部分與自注意力機制相同。假設模型輸入只包含兩個詞,我們正在觀察第二個詞。在這種情況下,后兩個詞都被屏蔽了。因此模型會干擾計算注意力得分的步驟。基本上,它總是為序列中后續的詞賦予 0 分的注意力得分,因此模型不會在后續單詞上得到最高的注意力得分:
我們通常使用注意力掩模矩陣來實現這種屏蔽操作。不妨想象一個由四個單詞組成的序列(例如「robot must obey orders」(機器人必須服從命令))在語言建模場景中,這個序列被分成四步進行處理——每個單詞一步(假設現在每個單詞(word)都是一個詞(token))。由于這些模型都是批量執行的,我們假設這個小型模型的批處理大小為 4,它將整個序列(包含 4 步)作為一個批處理。
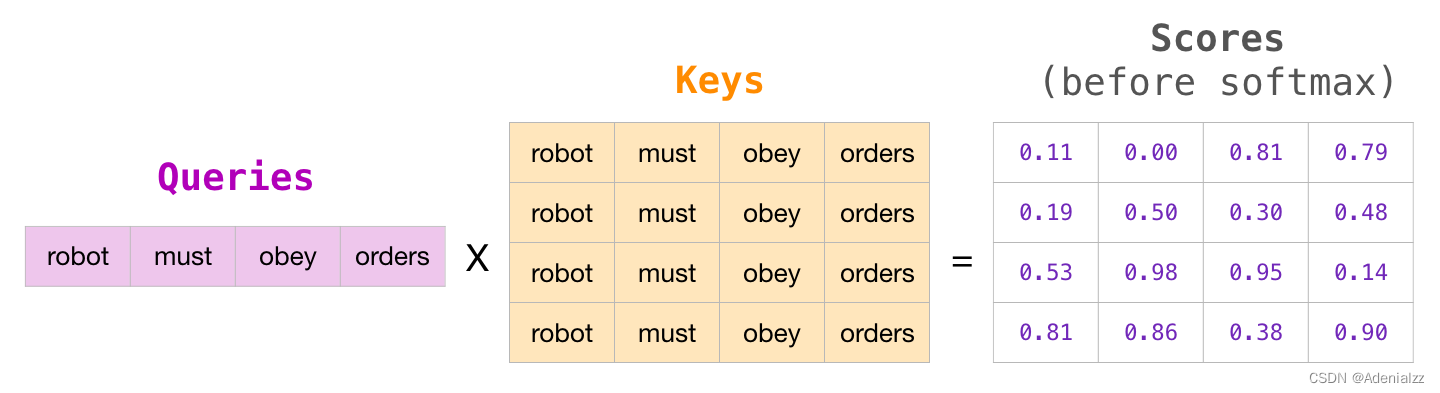
在矩陣形式中,我們通過將查詢矩陣和鍵矩陣相乘來計算注意力得分。該過程的可視化結果如下所示,下圖使用的是與單元格中該單詞相關聯的查詢(或鍵)向量,而不是單詞本身:
在相乘之后,我們加上注意力掩模三角矩陣。它將我們想要屏蔽的單元格設置為負無窮或非常大的負數(例如,在 GPT2 中為 -10 億):
然后,對每一行執行 softmax 操作,從而得到我們在自注意力機制中實際使用的注意力得分:
此分數表的含義如下:
GPT-2 的掩模自注意力機制接下來,我們將更詳細地分析 GPT-2 的掩模自注意力機制。 模型評價時:一次只處理一個詞我們可以通過掩模自注意機制的方式執行 GPT-2。但是在模型評價時,當我們的模型每輪迭代后只增加一個新單詞時,沿著先前已經處理過的路徑再重新計算詞(tokrn)的自注意力是效率極低的。 在這種情況下,我們處理第一個詞(暫時忽略
GPT-2 保存了詞「a」的鍵向量和值向量。每個自注意力層包括了該詞相應的鍵和值向量。
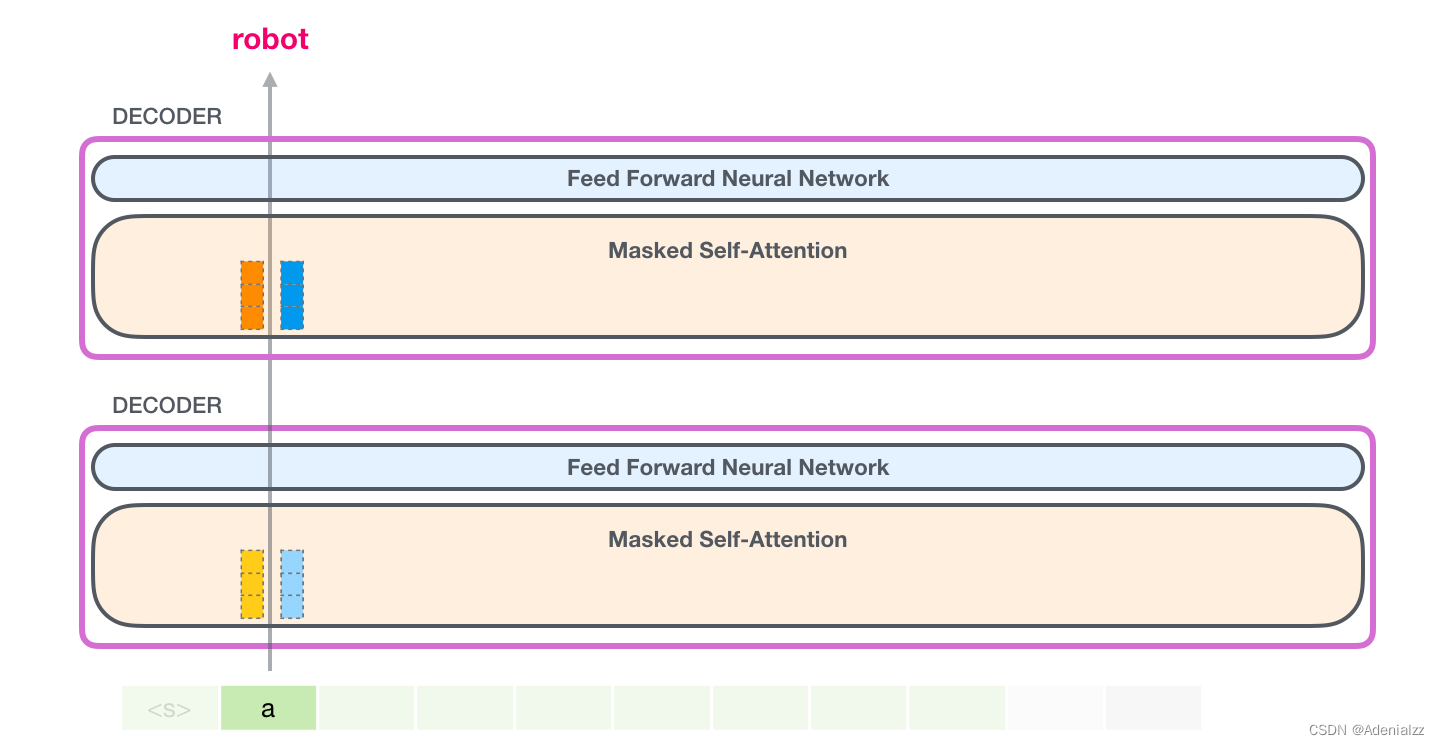
在下一次迭代中,當模型處理單詞「robot」時,它不再需要為詞「a」生成查詢、鍵和值向量。它只需要復用第一次迭代中保存的向量:
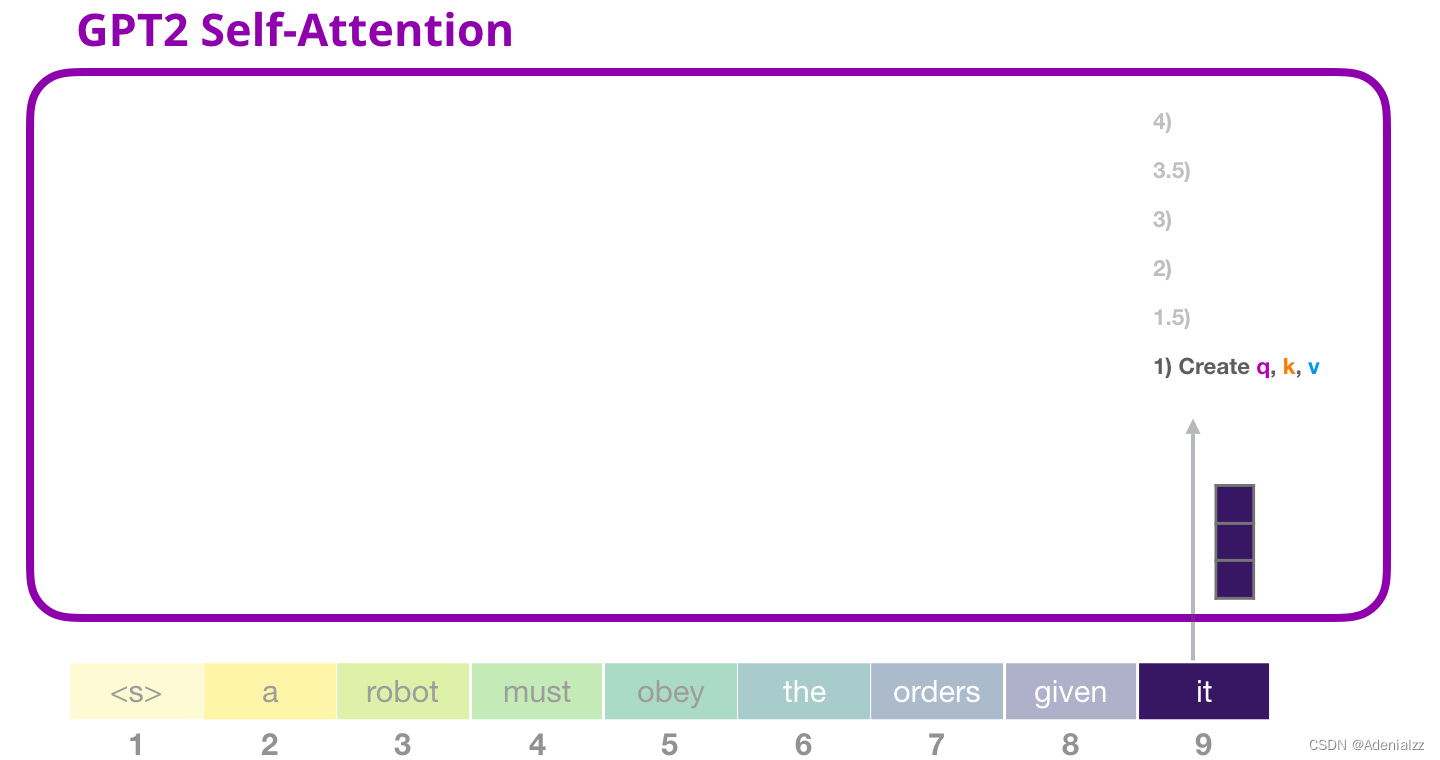
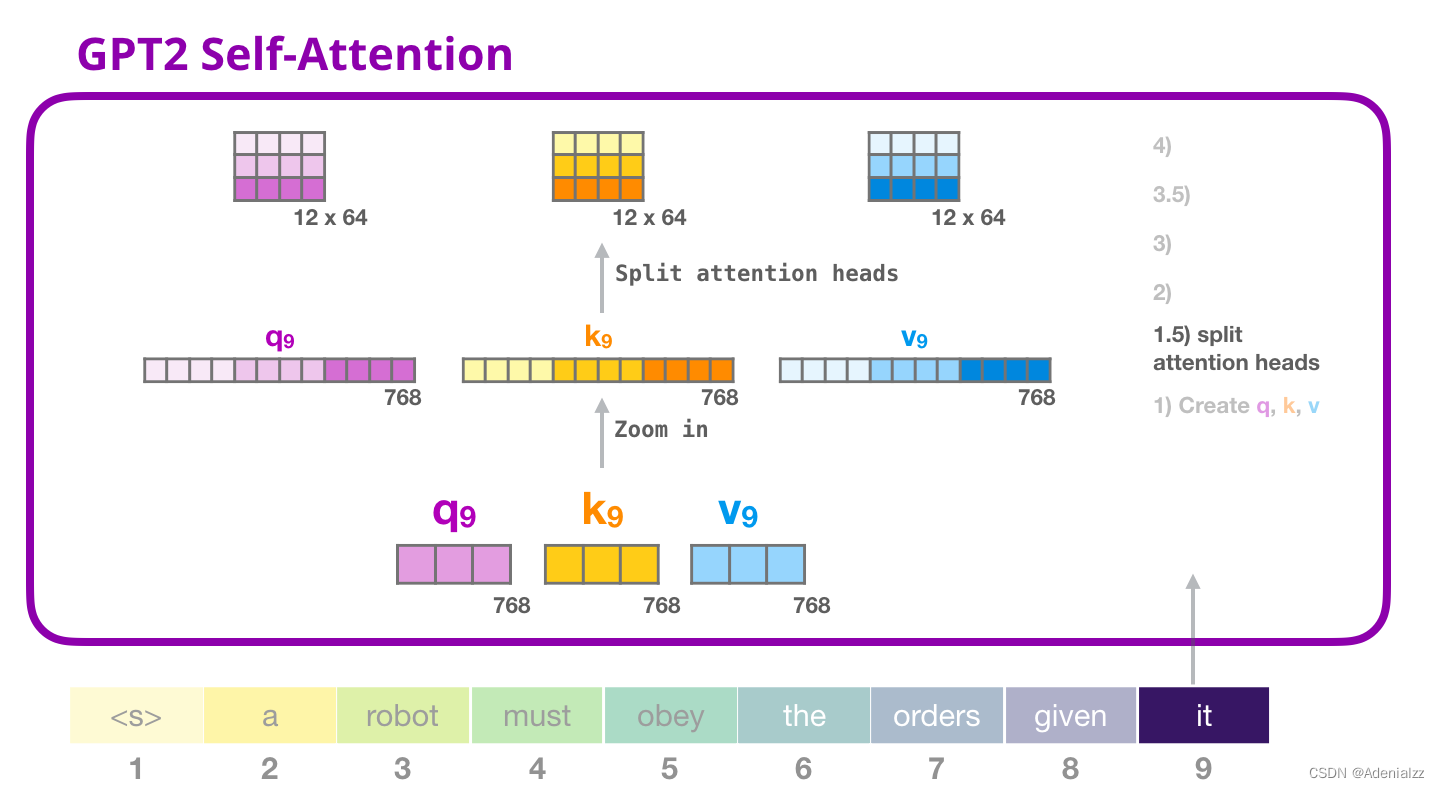
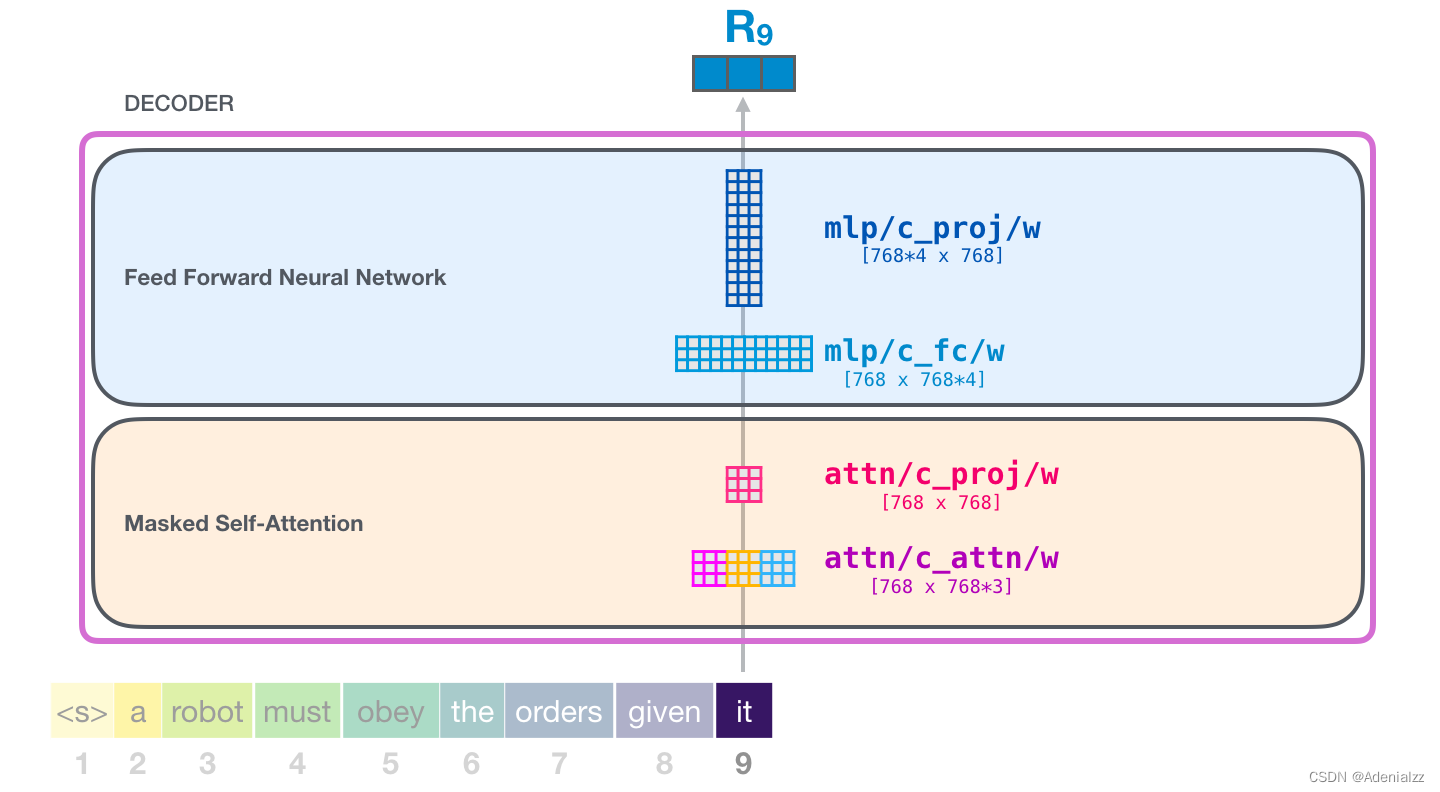
GPT-2 自注意力機制:1-創建查詢、鍵和值假設模型正在處理單詞「it」。對于下圖中底部的模塊來說,它對該詞的輸入則是「it」的嵌入向量+序列中第九個位置的位置編碼
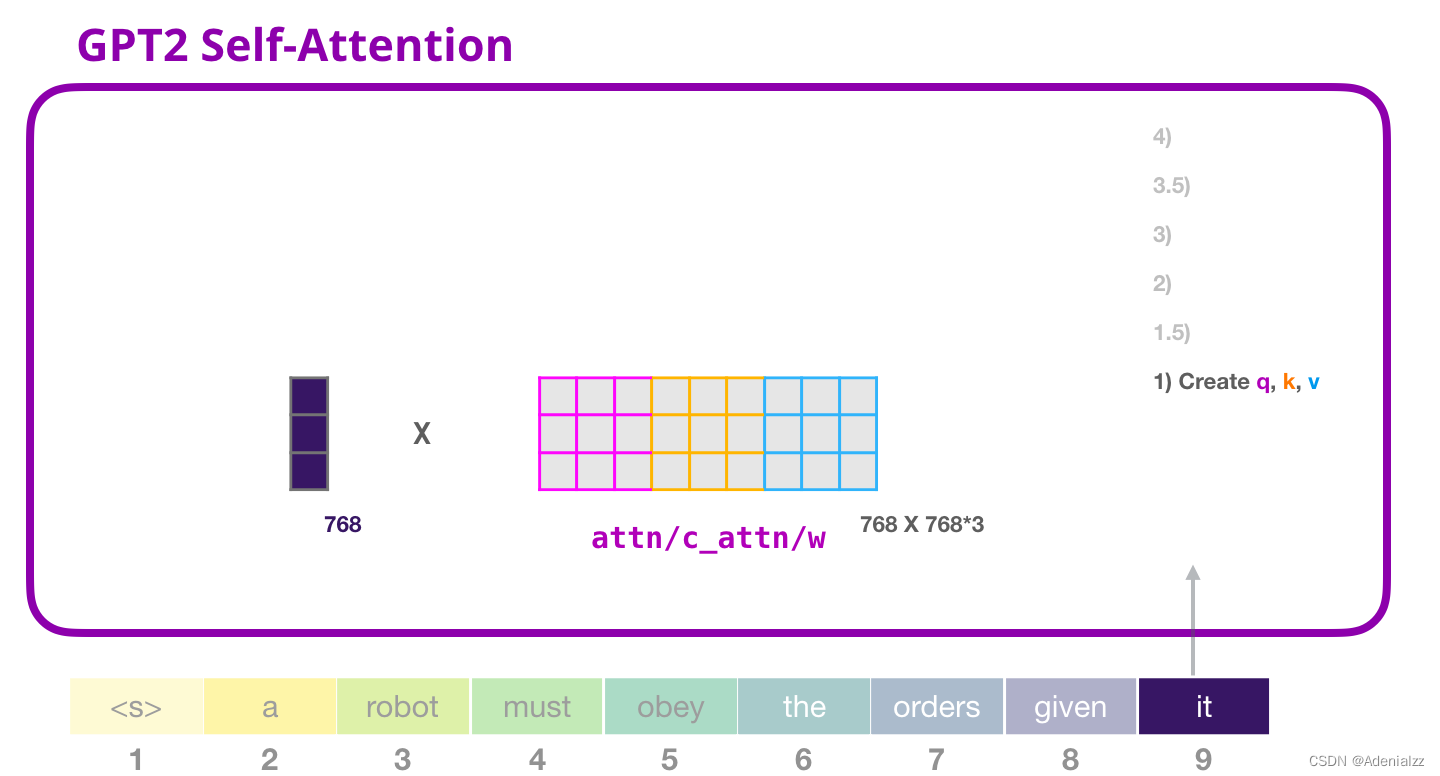
Transformer 中的每個模塊都有自己的權重(之后會詳細分析)。我們首先看到的是用于創建查詢、鍵和值的權重矩陣。
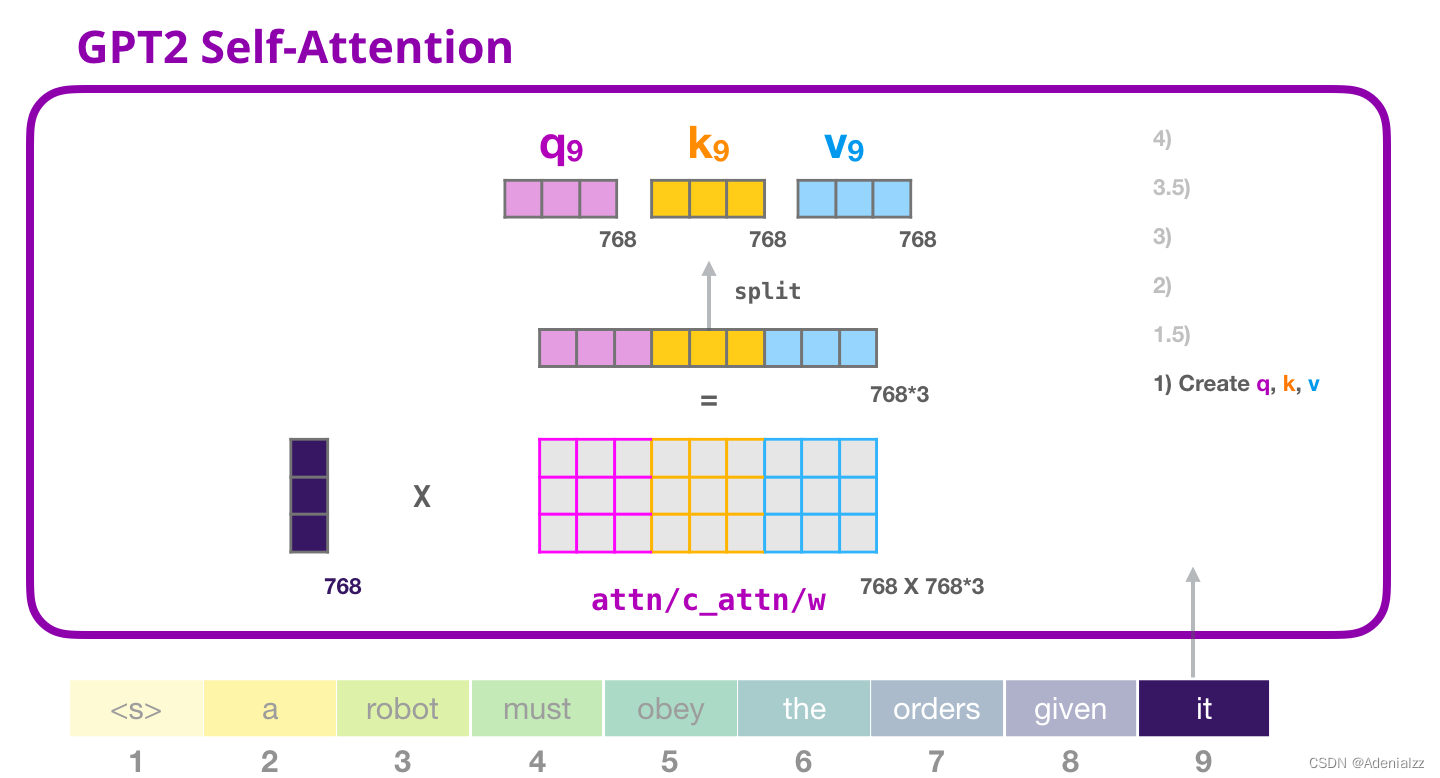
自注意力機制將它的輸入與權重矩陣相乘(并加上一個偏置向量,這里不作圖示)。 相乘后得到的向量從基本就是單詞「it」的查詢、鍵和值向量連接 的結果。
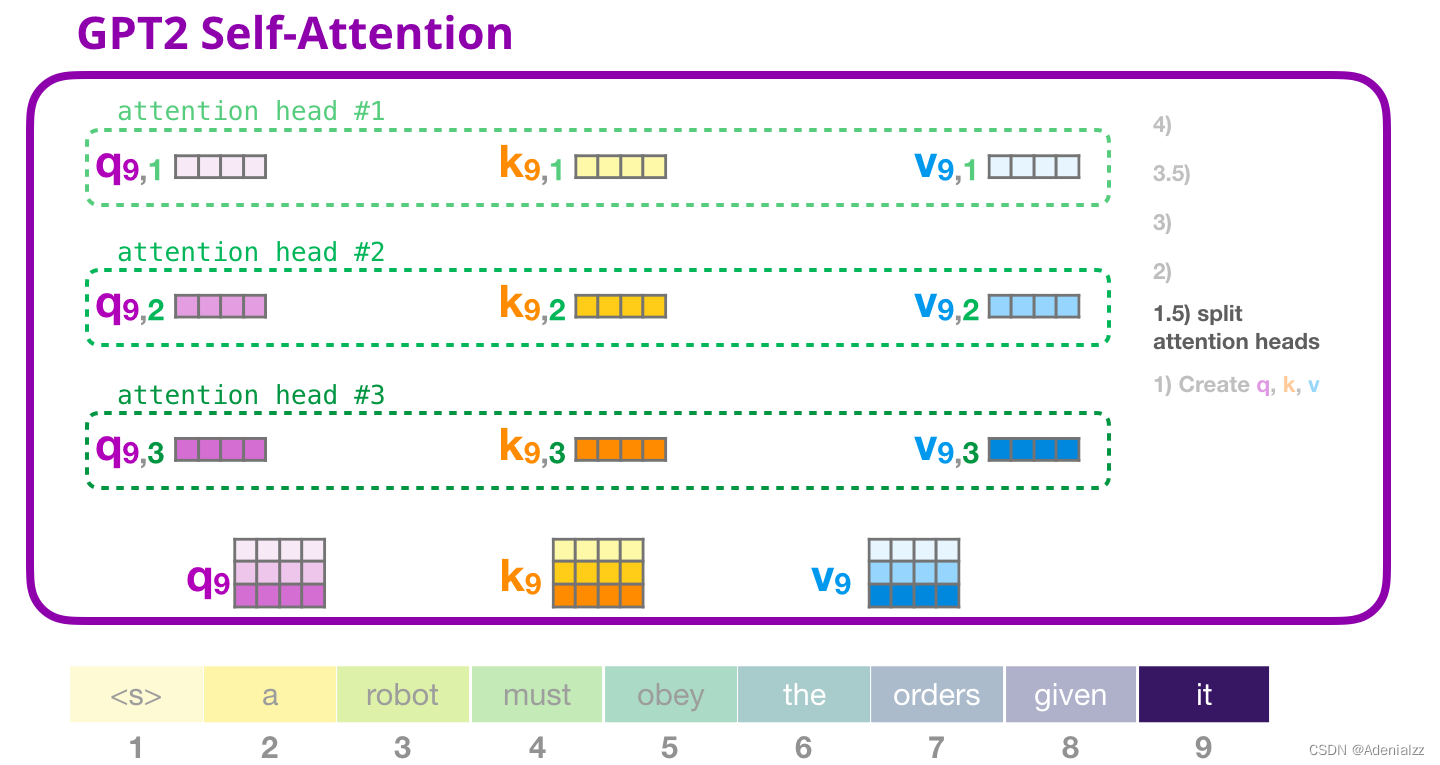
將輸入向量和注意力權重向量相乘(之后加上偏置向量)得到這個詞的鍵、值和查詢向量。 GPT-2 自注意力機制:1.5-分裂成注意力頭在前面的示例中,我們直接介紹了自注意力機制而忽略了「多頭」的部分。現在,對這部分概念有所了解會大有用處。自注意力機制是在查詢(Q)、鍵(K)、值(V)向量的不同部分多次進行的。「分裂」注意力頭指的是,簡單地將長向量重塑成矩陣形式。在小型的 GPT-2 中,有 12 個注意力頭,因此這是重塑矩陣中的第一維:
在前面的示例中,我們介紹了一個注意力頭的情況。多個注意力頭可以想象成這樣(下圖為 12 個注意力頭中的 3 個的可視化結果):
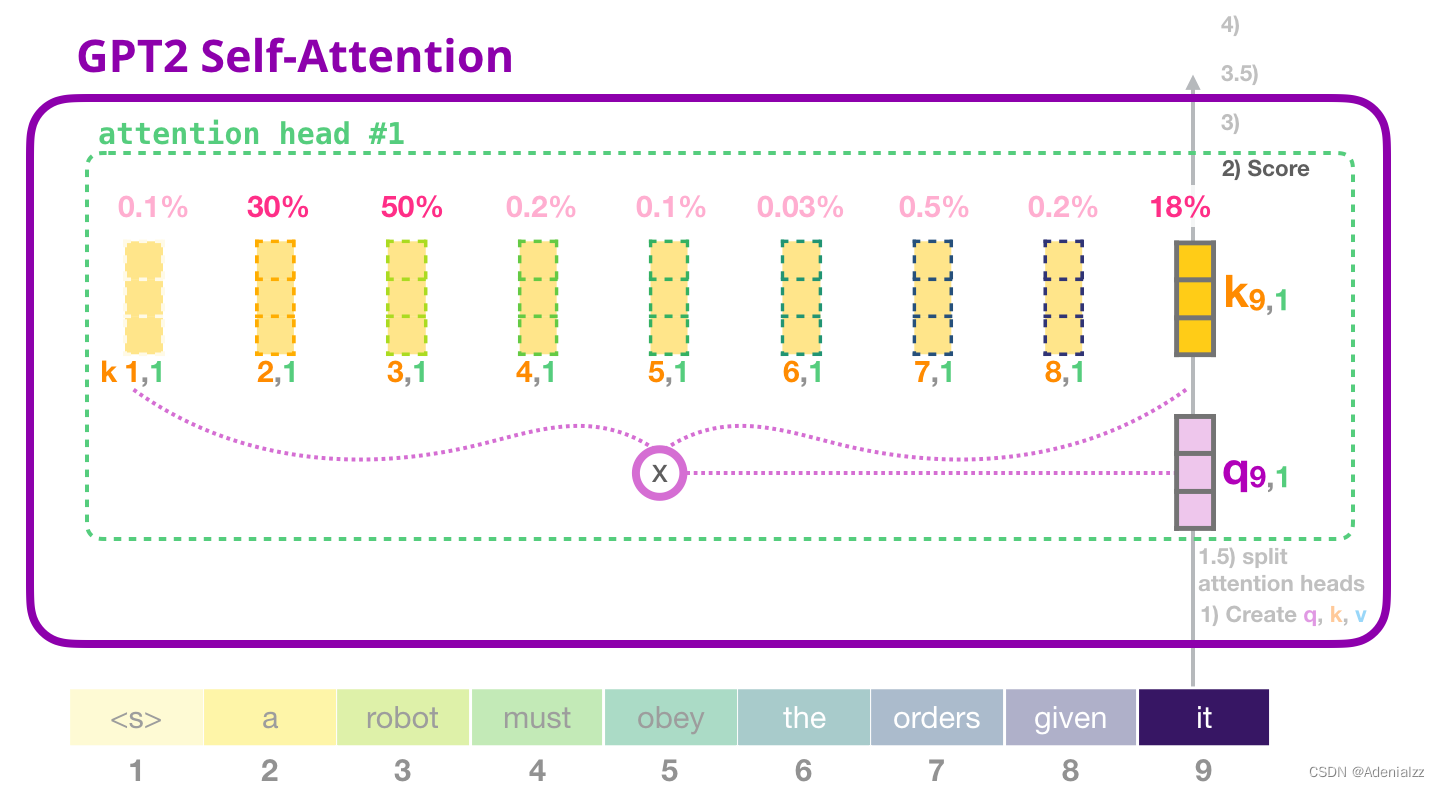
GPT-2 自注意力機制:2-計算注意力得分我們接下來介紹計算注意力得分的過程——此時我們只關注一個注意力頭(其它注意力頭都進行類似的操作)。
當前關注的詞(token)可以對與其它鍵詞的鍵向量相乘得到注意力得分(在先前迭代中的第一個注意力頭中計算得到):
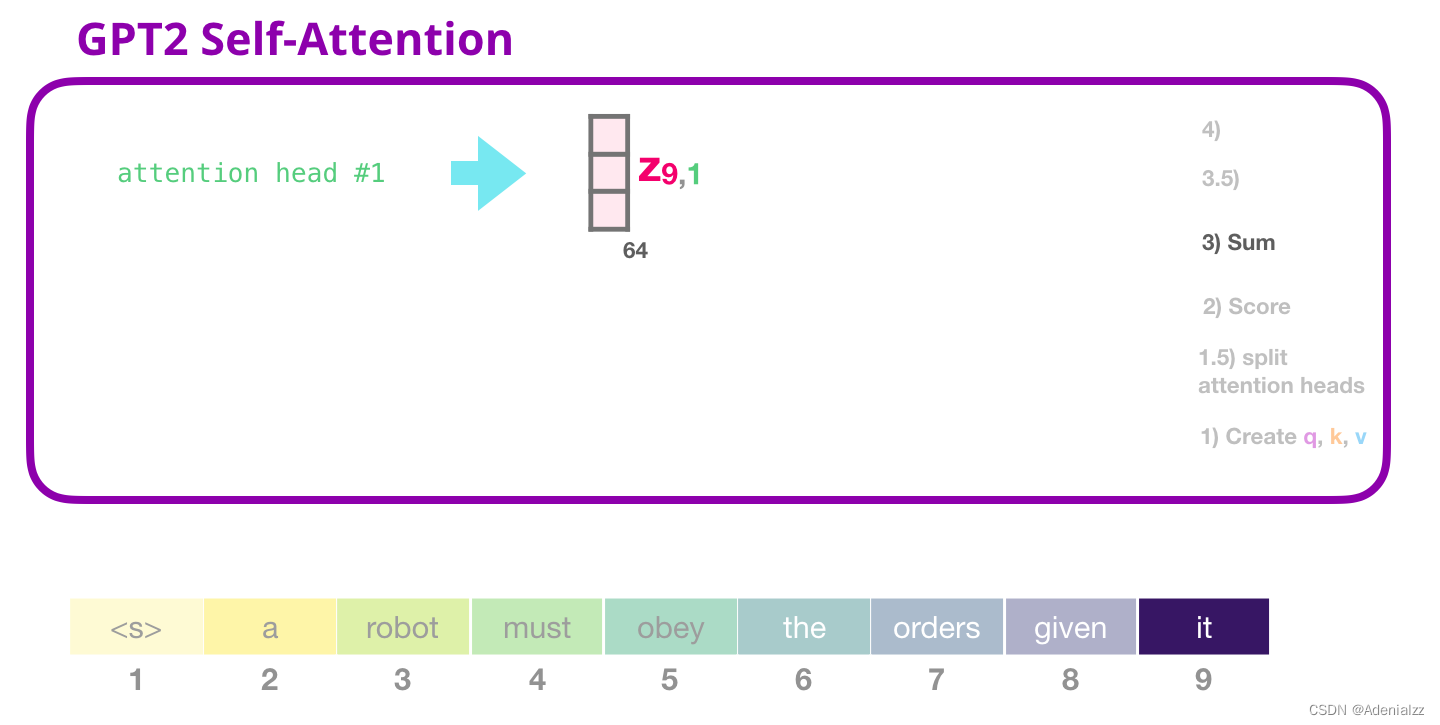
GPT-2 自注意力機制:3-求和正如前文所述,我們現在可以將每個值向量乘上它的注意力得分,然后求和,得到的是第一個注意力頭的自注意力結果:
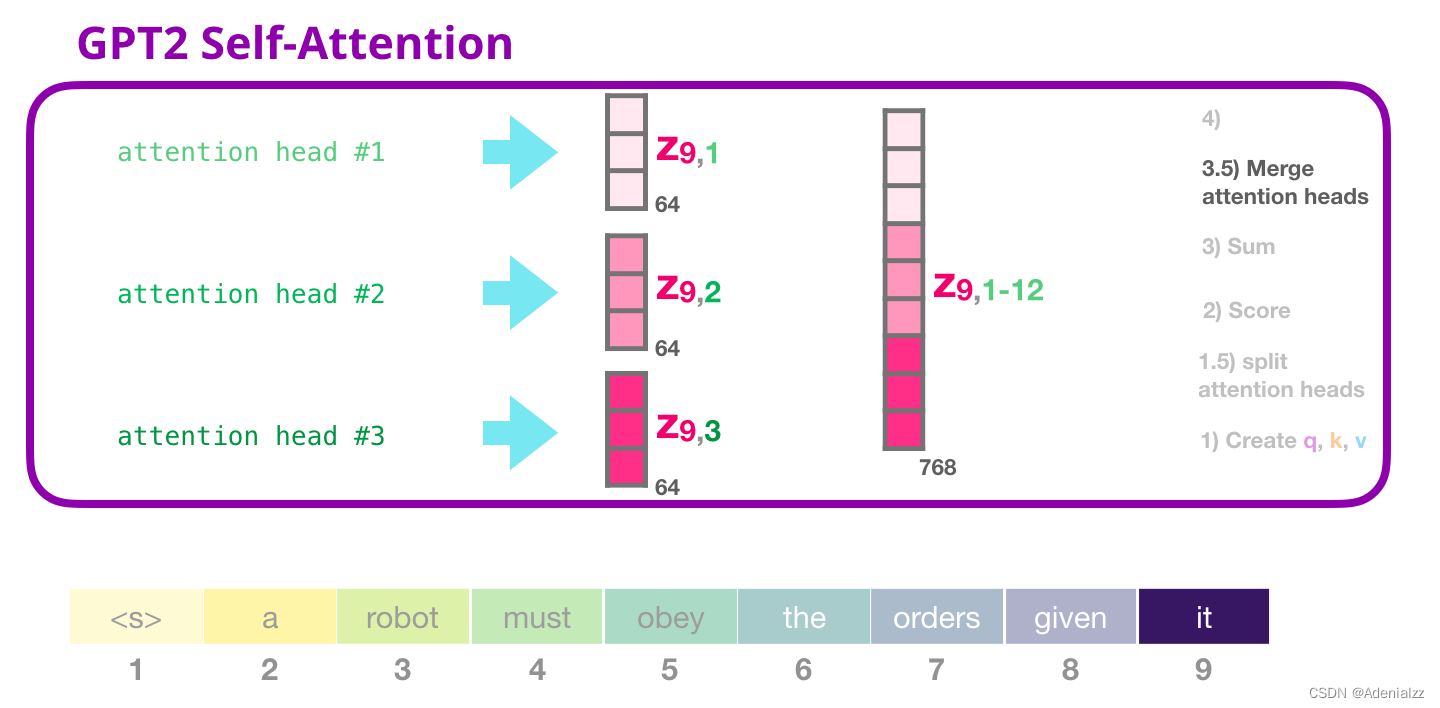
GPT-2 自注意力機制:3.5-合并多個注意力頭我們處理多個注意力頭的方式是先將它們連接成一個向量:
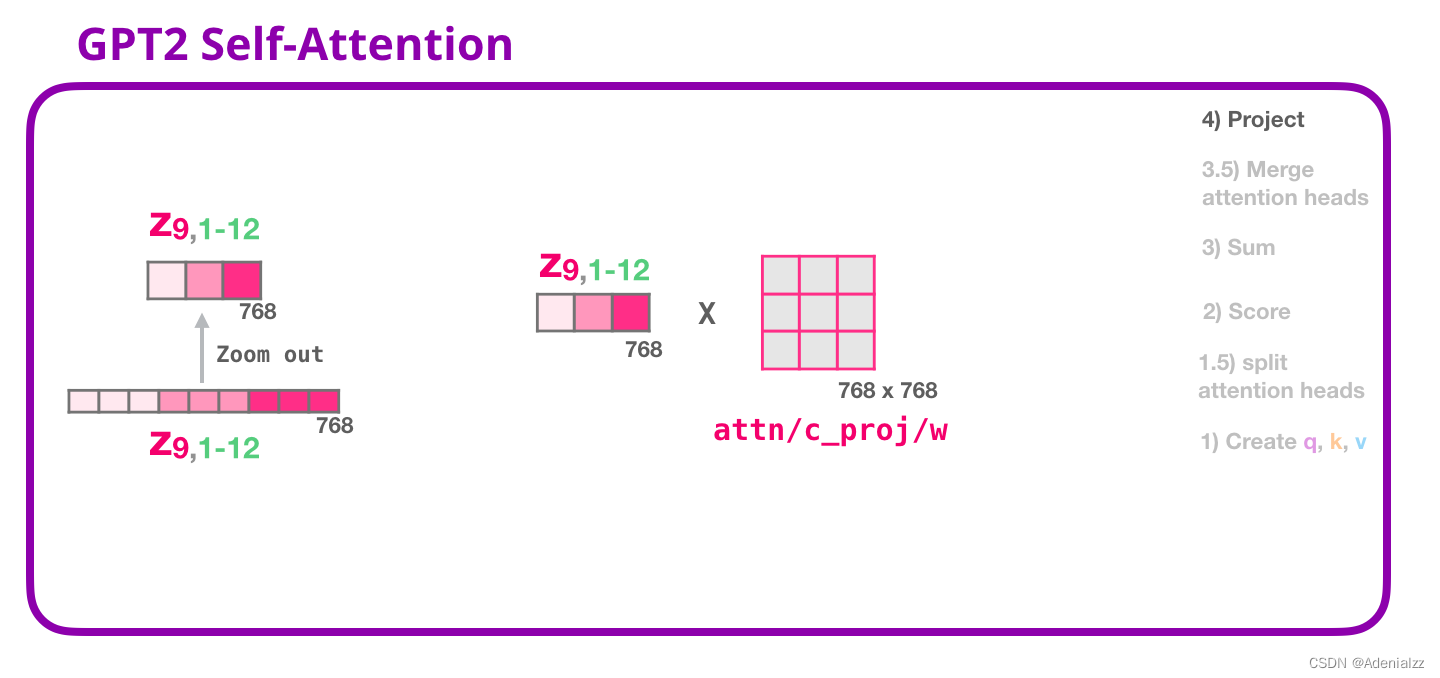
但是這個向量還不能被傳遞到下一個子層。我們首先需要將這個隱含狀態的混合向量轉變成同質的表示形式。 GPT-2 自注意力機制:4-投影我們將讓模型學習如何最好地將連接好的自注意力結果映射到一個前饋神經網絡可以處理的向量。下面是我們的第二個大型權重矩陣,它將注意力頭的結果投影到自注意力子層的輸出向量中:
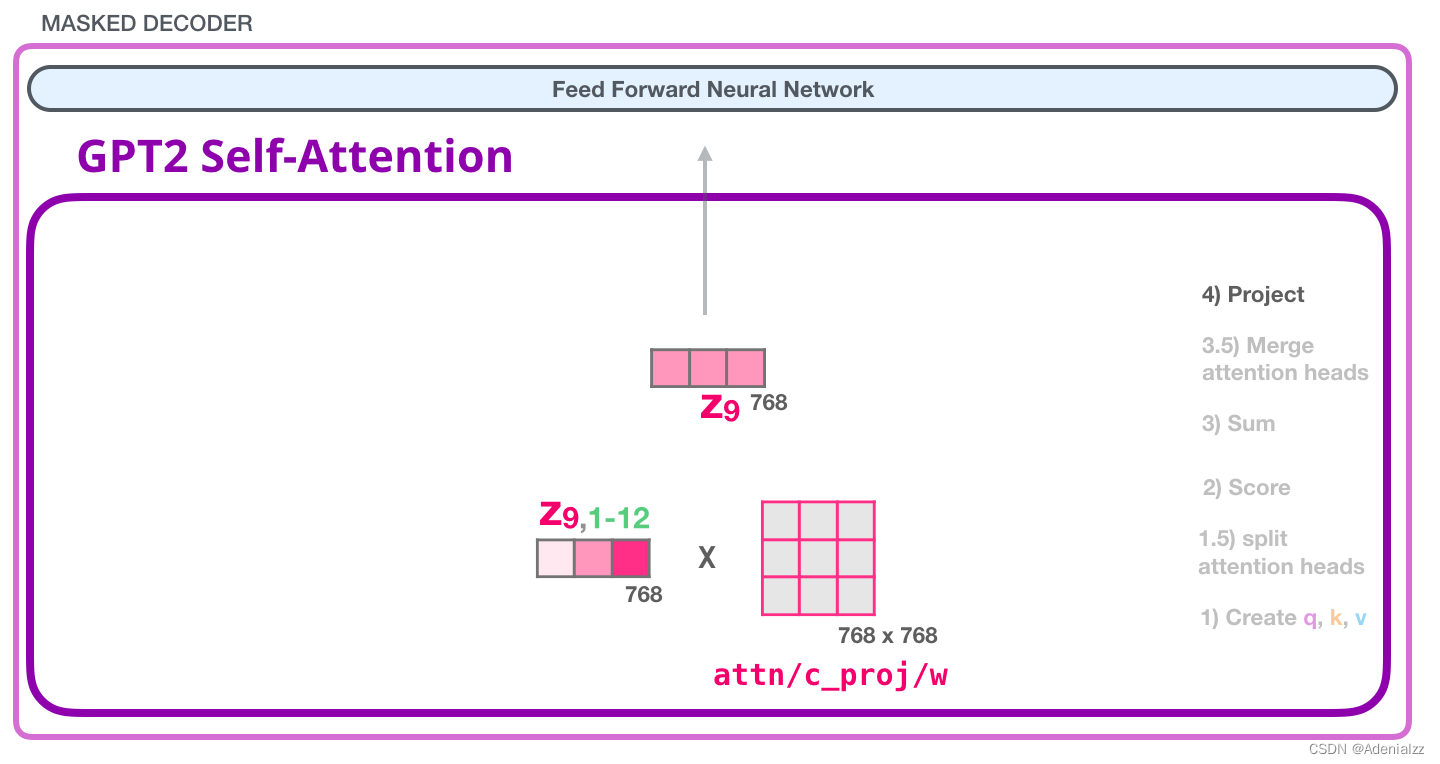
通過這個操作,我們可以生成能夠傳遞給下一層的向量:
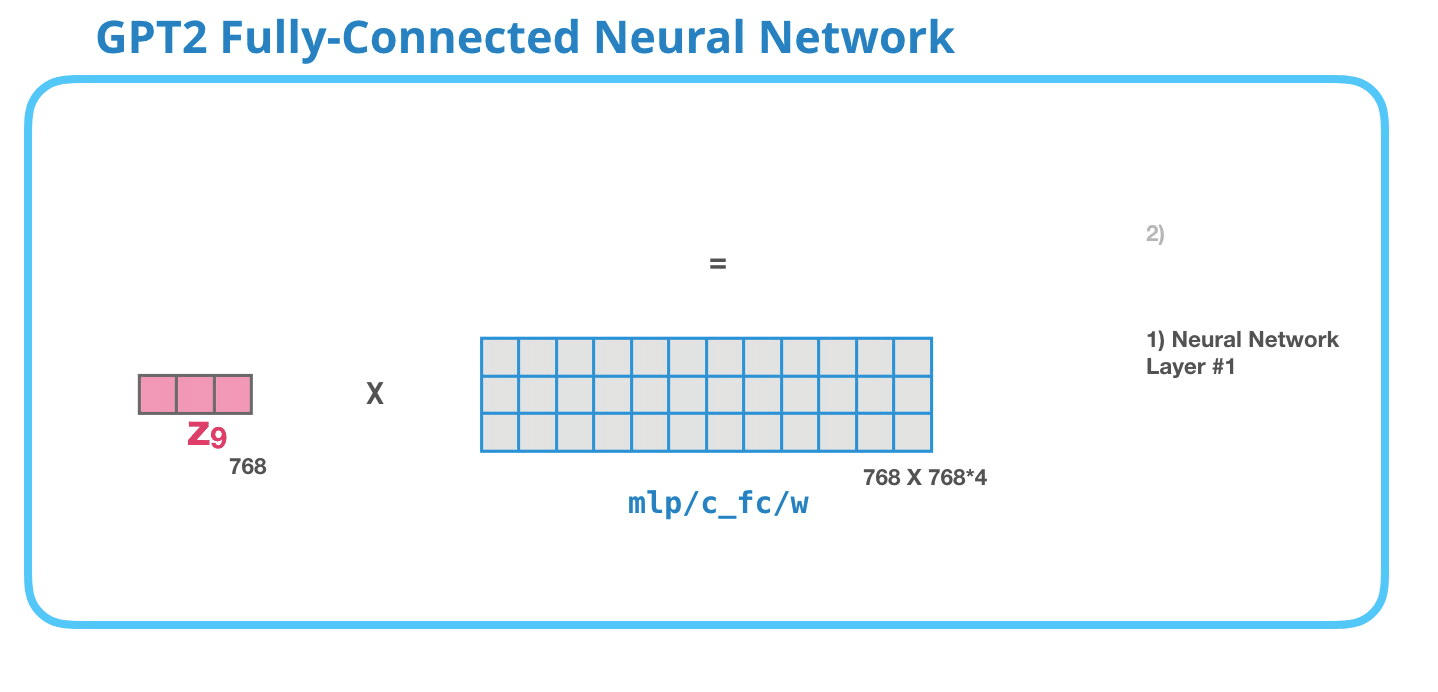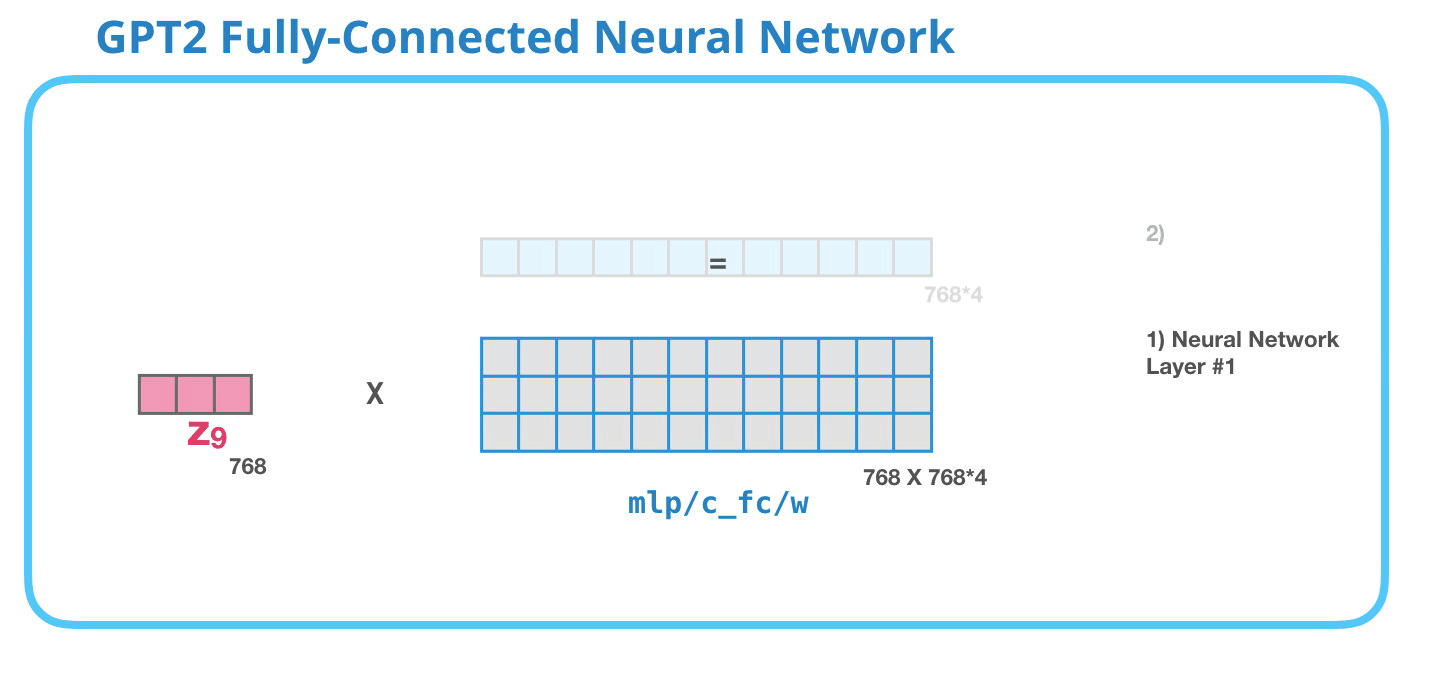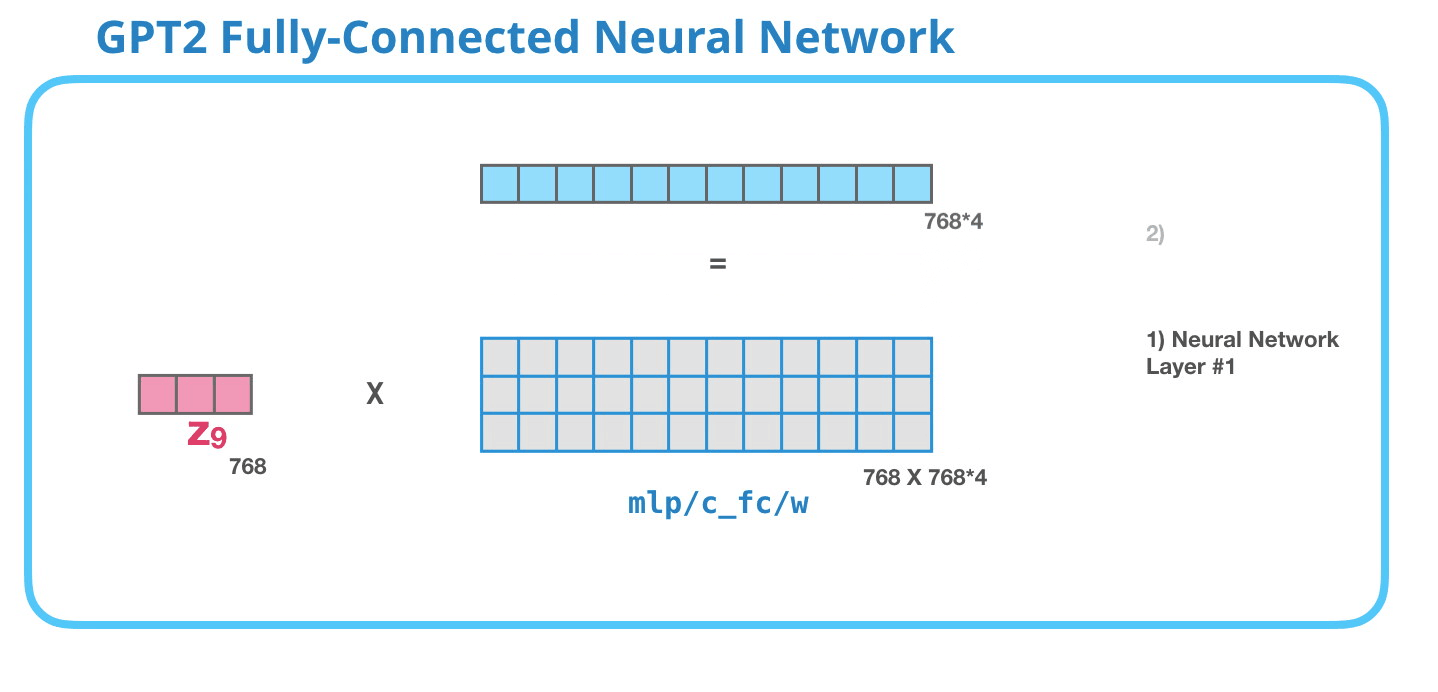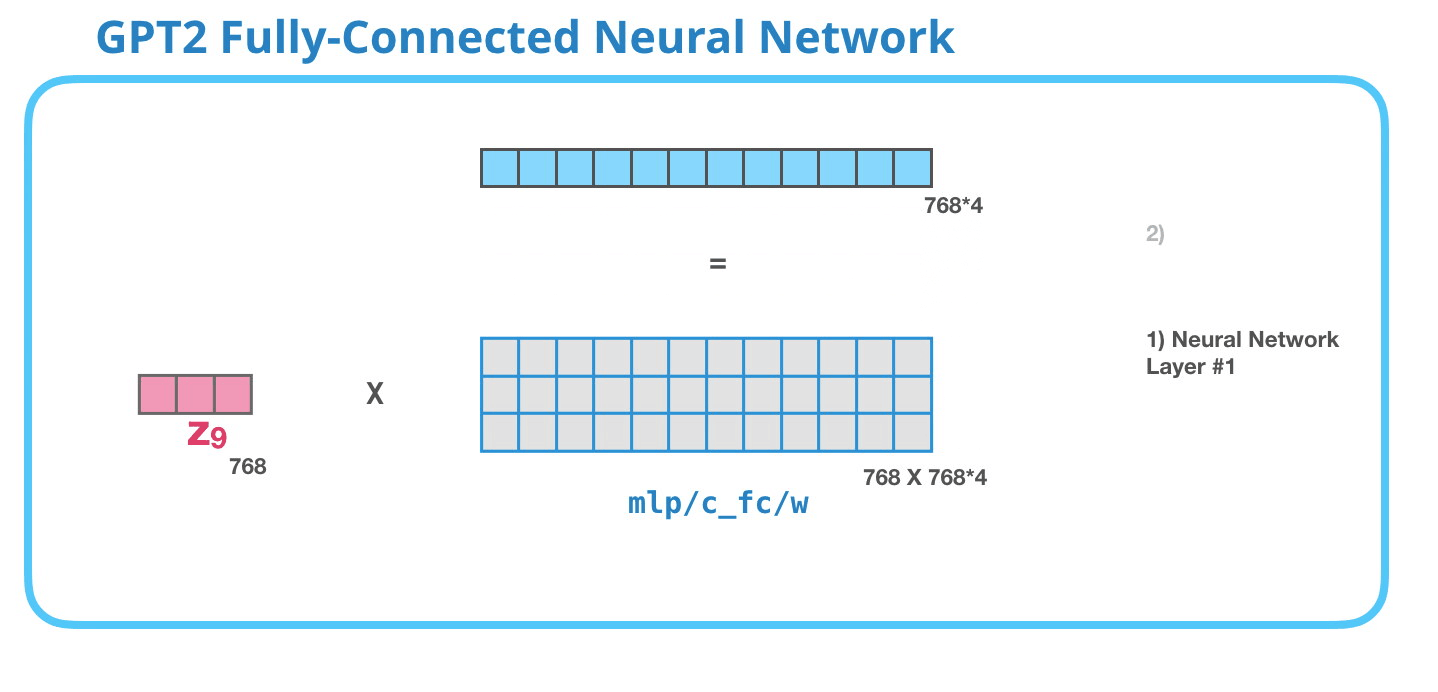
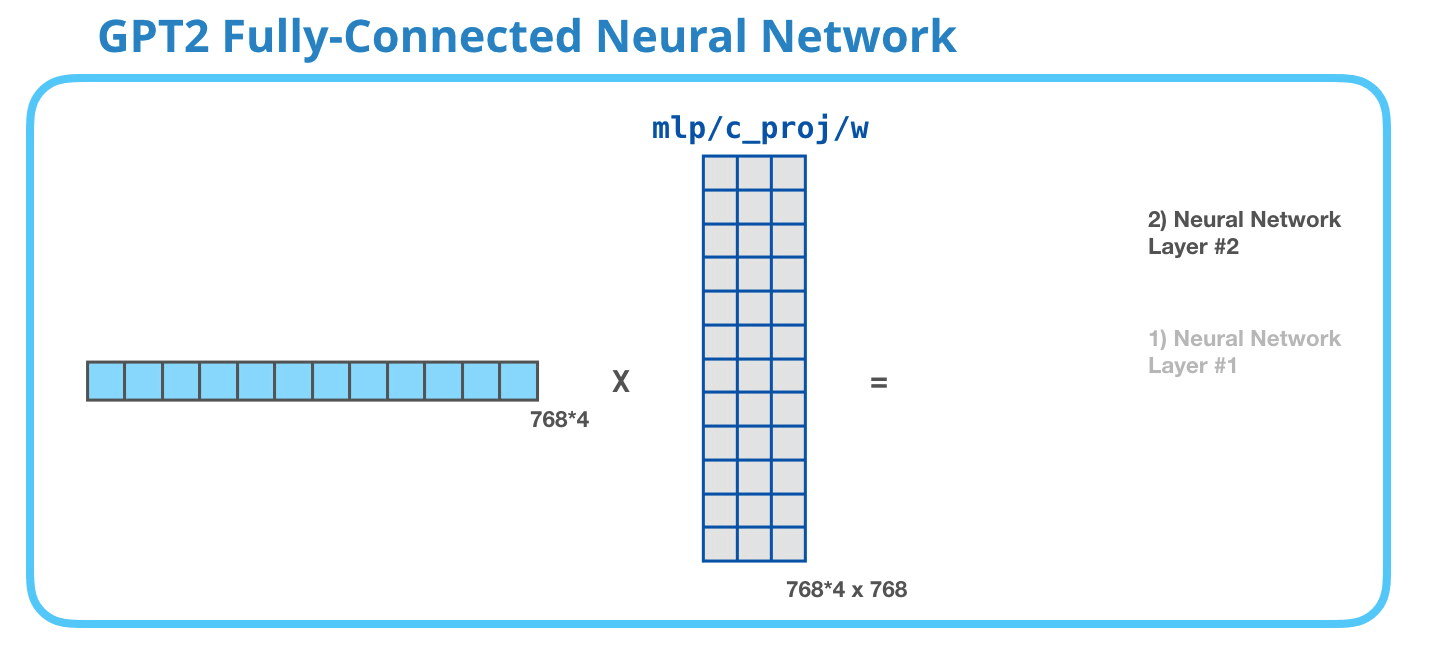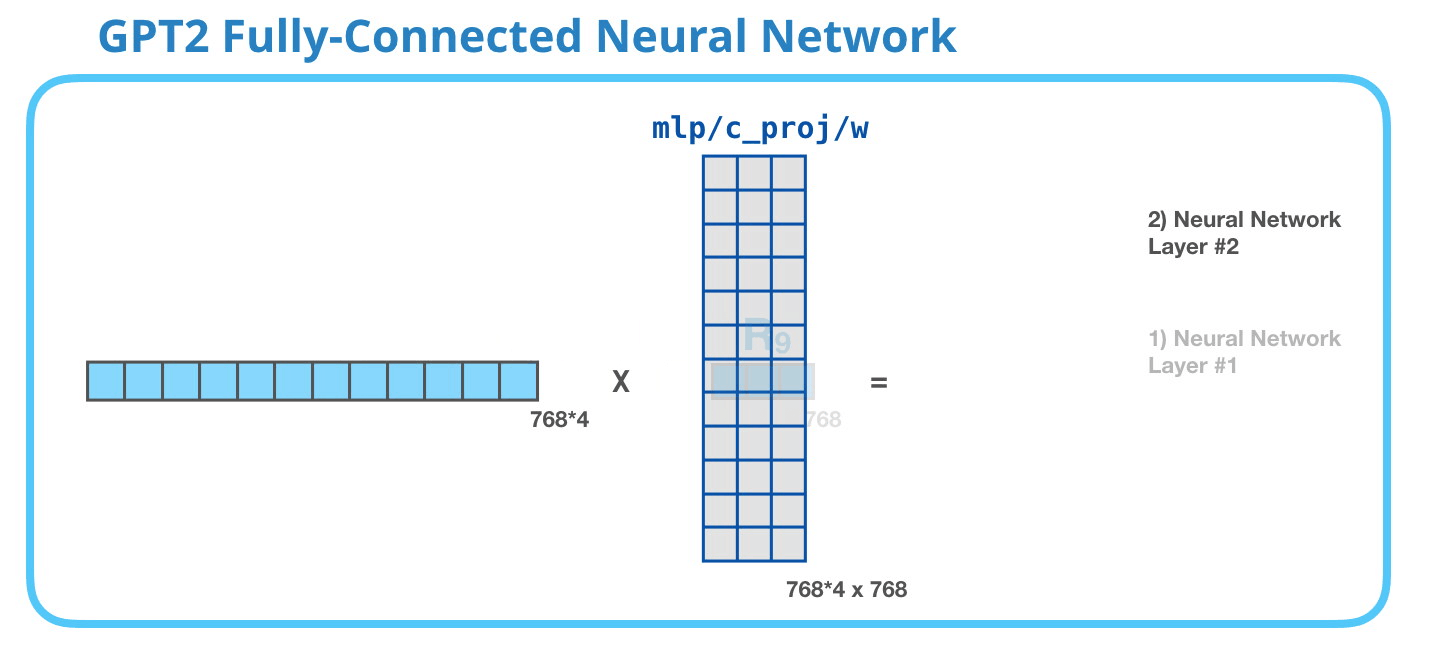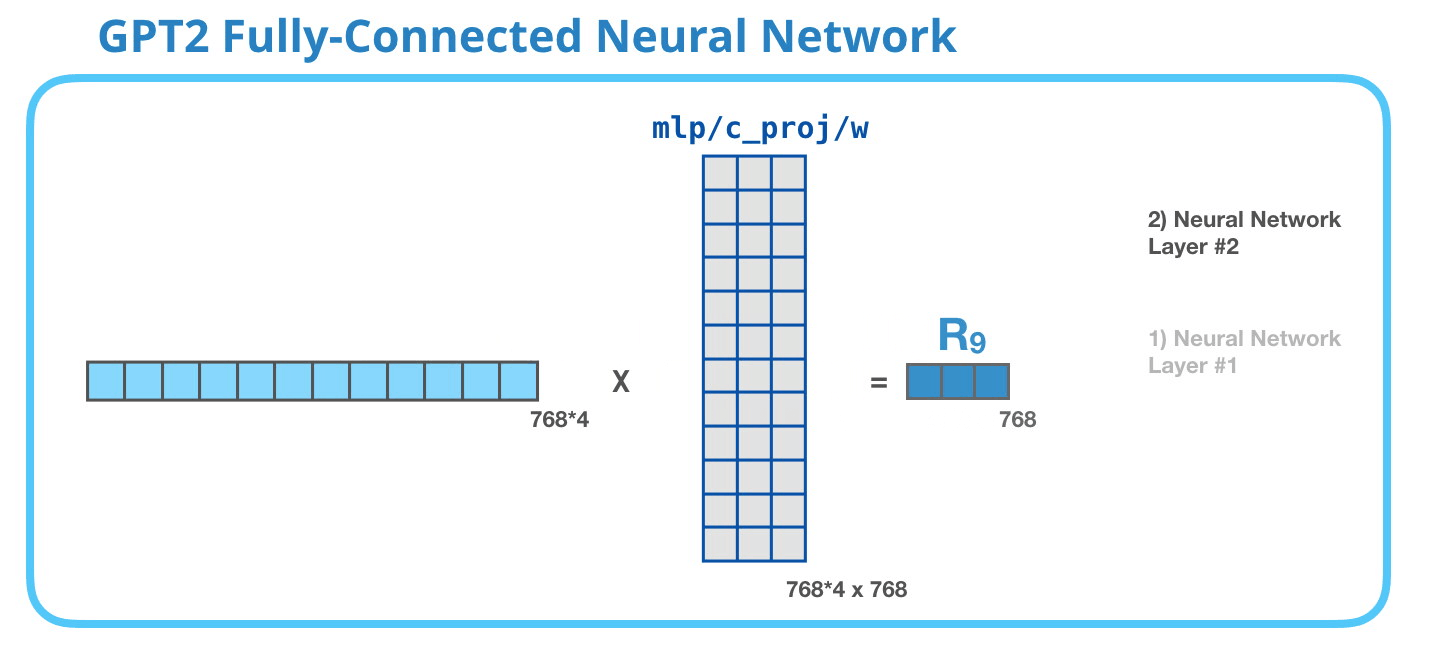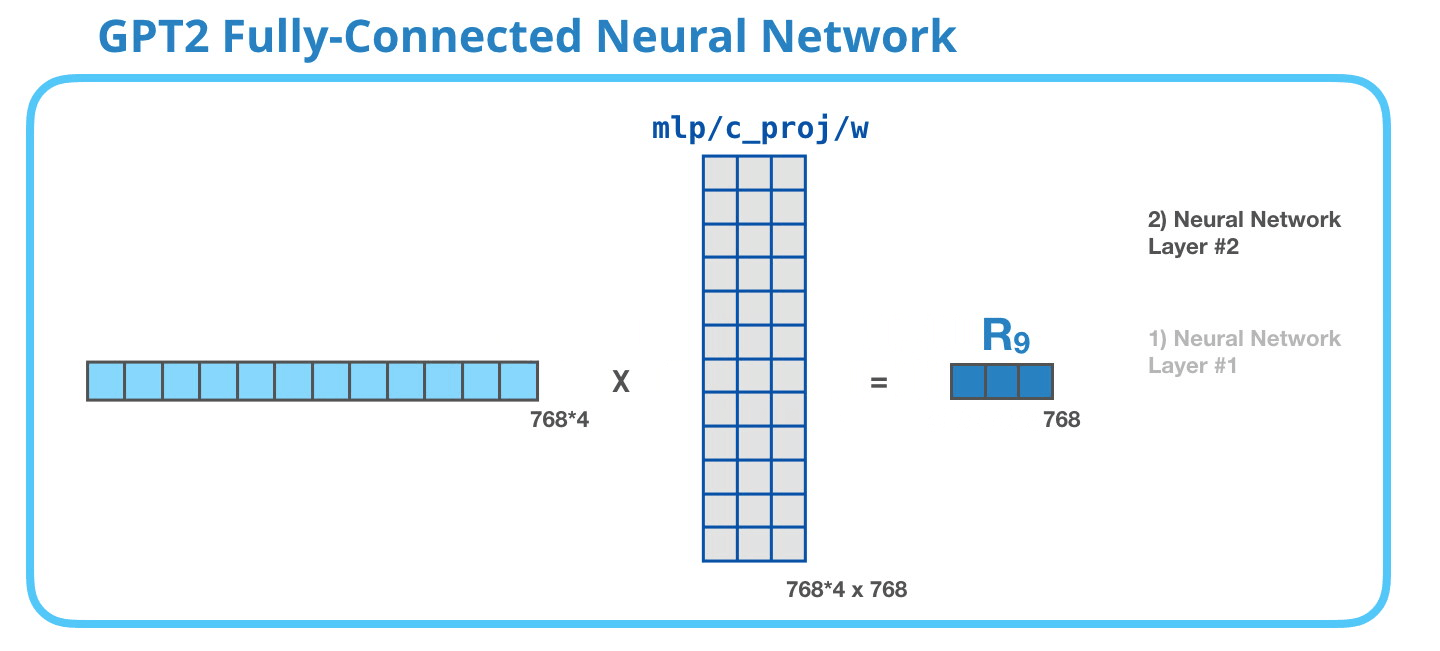
GPT-2 全連神經網絡:第一層在全連接神經網絡中,當自注意力機制已經將合適的上下文包含在其表征中之后,模塊會處理它的輸入詞。它由兩層組成:第一層的大小是模型的 4 倍(因為小型 GPT-2 的大小為 768 個單元,而這個網絡將有 768*4=3072 個單元)。為什么是 4 倍呢?這只是原始 transformer 的運行大小(模型維度為 512 而模型的第一層為 2048)。這似乎給 transformer 模型足夠的表征容量來處理目前面對的任務。
GPT-2 全連神經網絡:第二層-投影到模型的維度第二層將第一層的結果投影回模型的維度大小(小型 GPT-2 的大小為 768)。這個乘法結果是該詞經過 transformer 模塊處理的結果。
你成功處理完單詞「it」了! 我們盡可能詳細地介紹了 transformer 模塊。現在,你已經基本掌握了 transformer 語言模型內部發生的絕大部分情況了。回顧一下,一個新的輸入向量會遇到如下所示的權重矩陣:
而且每個模塊都有自己的一組權重。另一方面,這個模型只有一個詞嵌入矩陣和一個位置編碼矩陣:
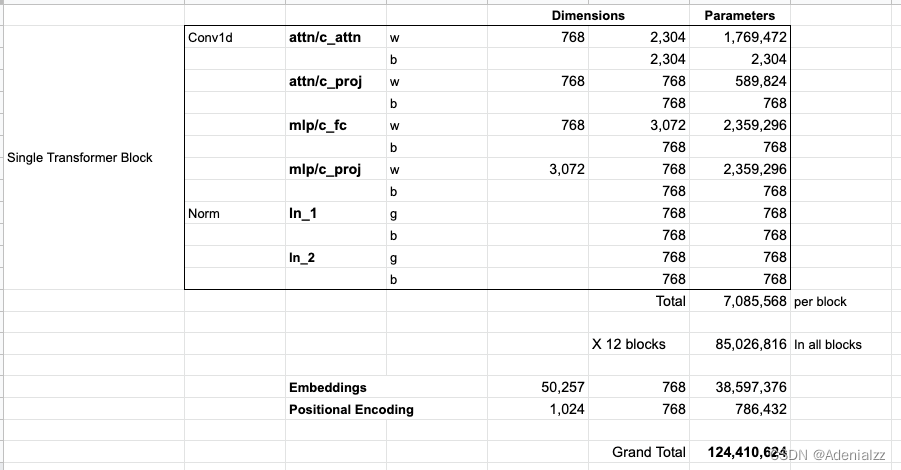
如果你想了解模型中的所有參數,下面是對它們的詳細統計結果:
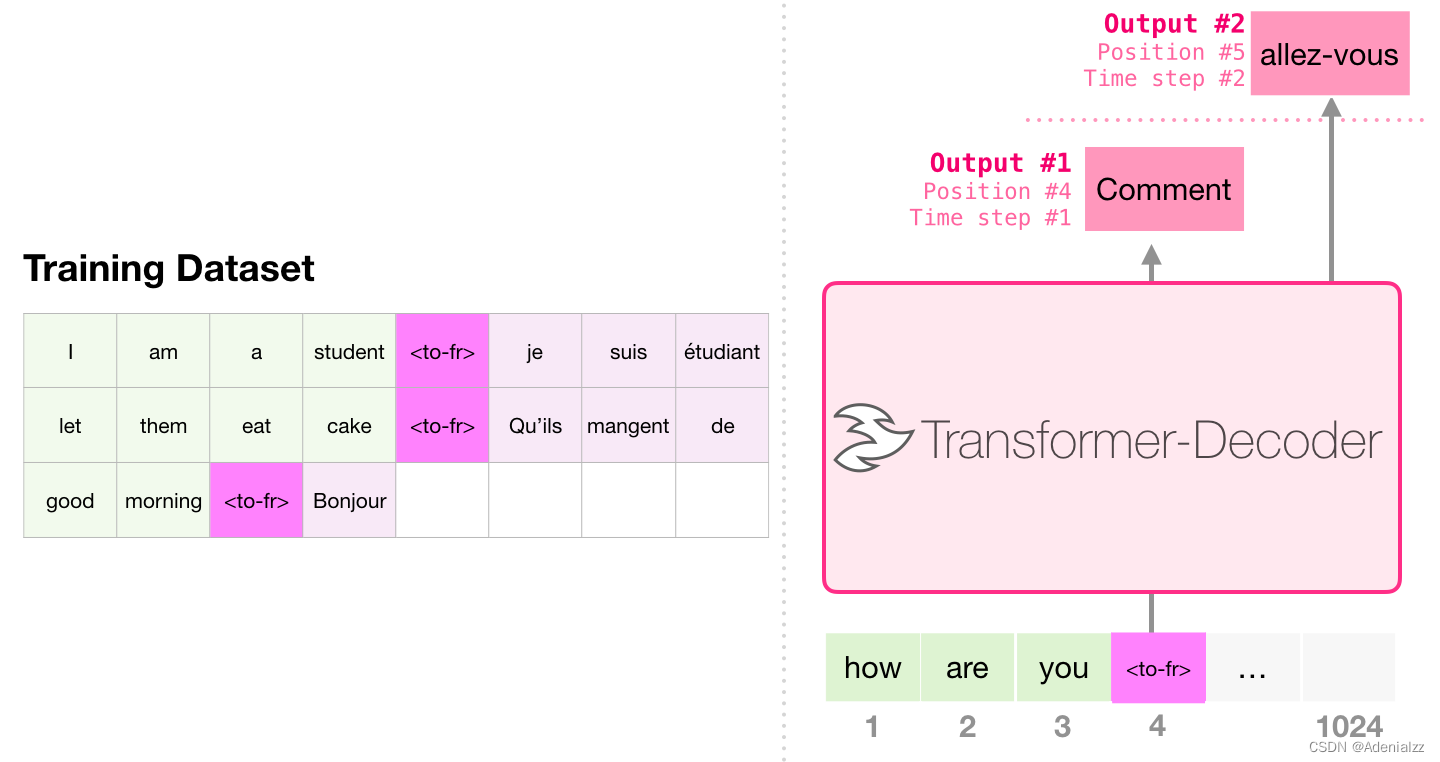
出于某些原因,該模型共計有 1 億 2,400 萬個參數而不是 1 億 1,700 萬個。我不確定這是為什么,但是這似乎就是發布的代碼中的數目(如果本文統計有誤,請讀者指正)。 第三部分:語言建模之外只包含解碼器的 transformer 不斷地表現出在語言建模之外的應用前景。在許多應用程序中,這類模型已經取得了成功,它可以用與上面類似的可視化圖表來描述。在文章的最后,讓我們一起來回顧一下其中的一些應用。 機器翻譯進行翻譯時,模型不需要編碼器。同樣的任務可以通過一個只有解碼器的 transformer 來解決:
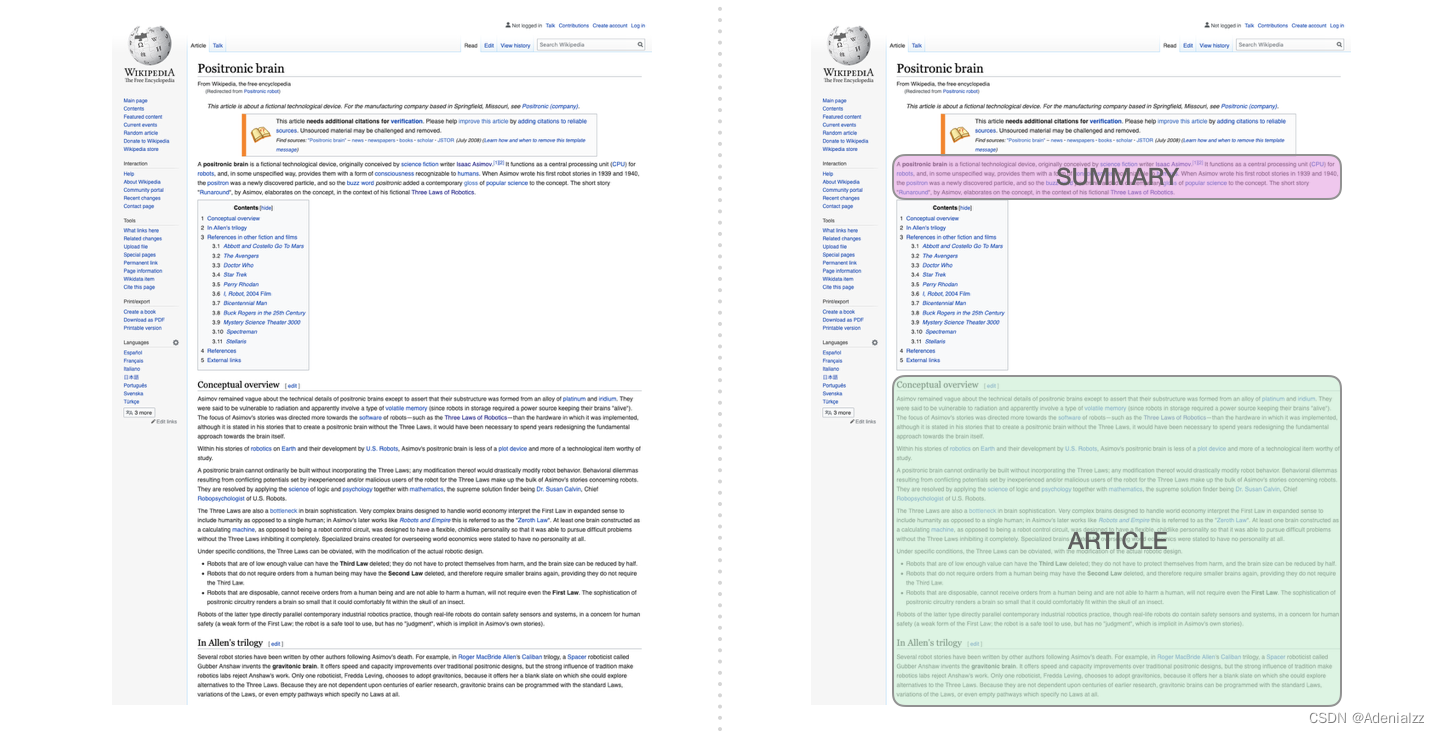
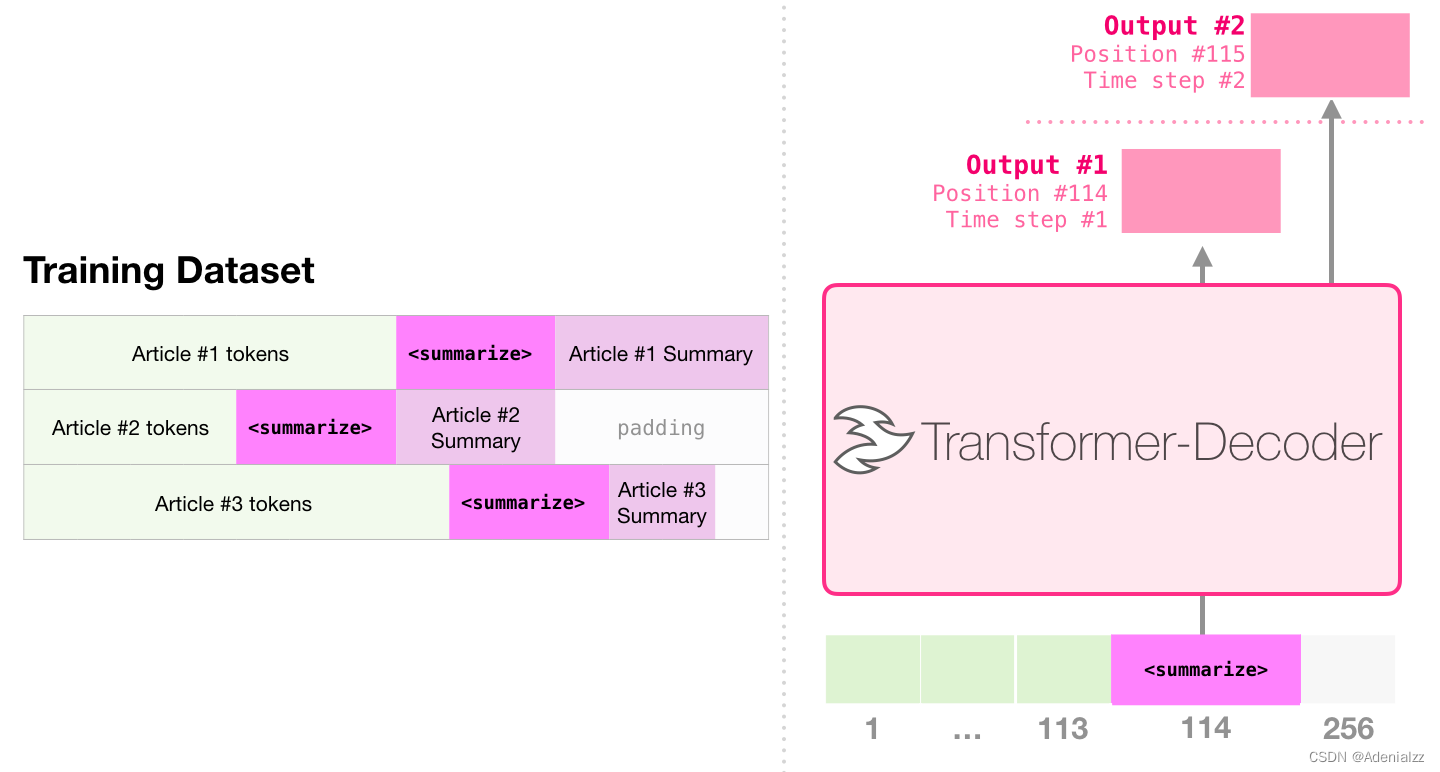
自動摘要生成這是第一個訓練只包含解碼器的 transformer 的任務。也就是說,該模型被訓練來閱讀維基百科的文章(沒有目錄前的開頭部分),然后生成摘要。文章實際的開頭部分被用作訓練數據集的標簽:
論文使用維基百科的文章對模型進行了訓練,訓練好的模型能夠生成文章的摘要:
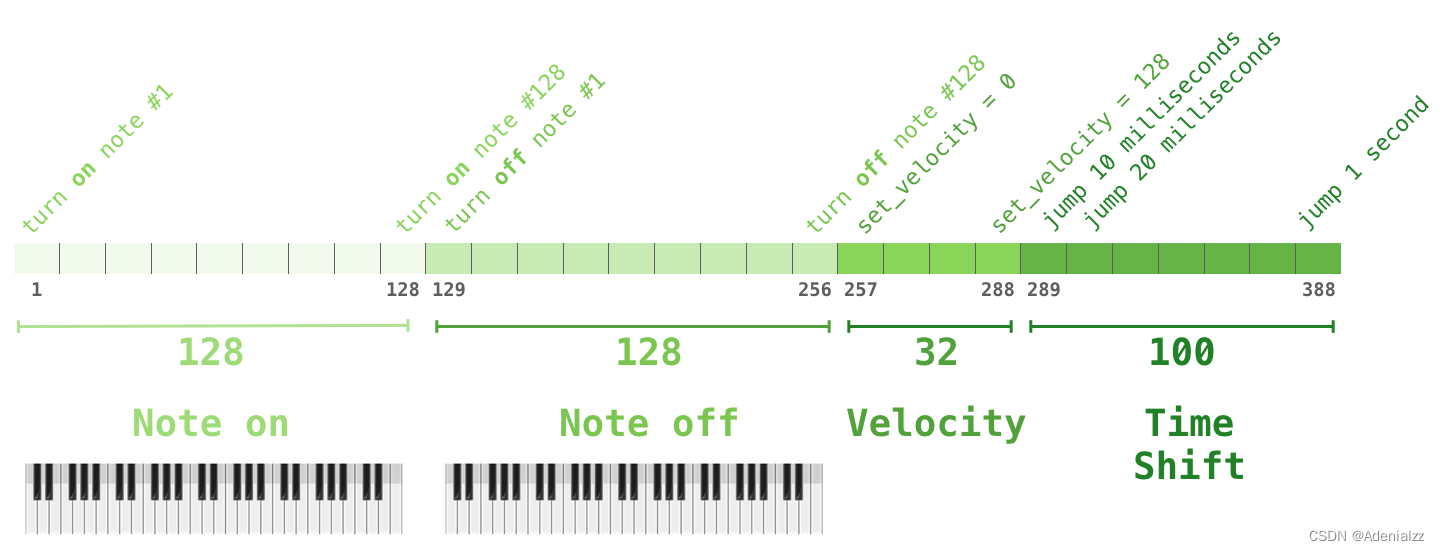
遷移學習在論文 Sample Efficient Text Summarization Using a Single Pre-Trained Transformer 中,首先使用只包含解碼器的 transformer 在語言建模任務中進行預訓練,然后通過調優來完成摘要生成任務。結果表明,在數據有限的情況下,該方案比預訓練好的編碼器-解碼器 transformer 得到了更好的效果。 GPT2 的論文也展示了對語言建模模型進行預訓練后取得的摘要生成效果。 音樂生成音樂 transformer 采用了只包含解碼器的 transformer 來生成具有豐富節奏和動感的音樂。和語言建模相似,「音樂建模」就是讓模型以一種無監督的方式學習音樂,然后讓它輸出樣本(我們此前稱之為「隨機工作」)。 你可能會好奇,在這種情境下是如何表征音樂的?請記住,語言建模可以通過對字符、單詞(word)、或單詞(word)某個部分的詞(token)的向量表征來實現。面對一段音樂演奏(暫時以鋼琴為例),我們不僅要表征這些音符,還要表征速度——衡量鋼琴按鍵力度的指標。
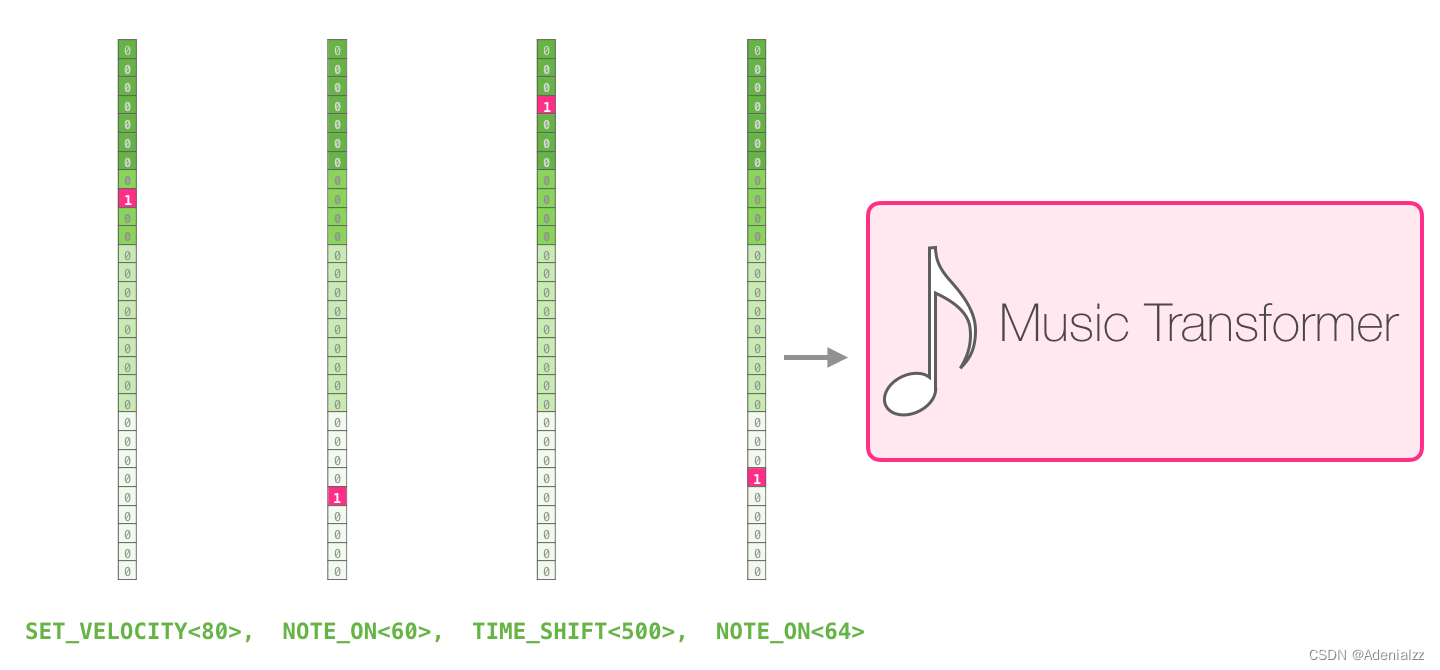
一段演奏可以被表征為一系列的 one-hot 向量。一個 MIDI 文件可以被轉換成這樣的格式。論文中展示了如下所示的輸入序列的示例。
這個輸入序列的 one-hot 向量表征如下:
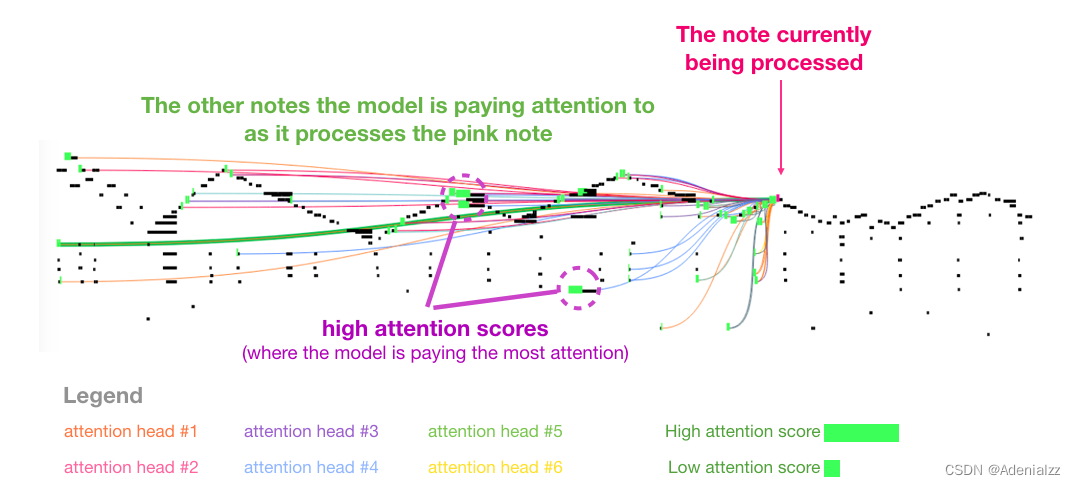
我喜歡論文中用來展示音樂 transformer 中自注意力機制的可視化圖表。我在這里加了一些注釋:
這段作品中出現了反復出現的三角輪廓。當前的查詢向量位于后面一個「高峰」,它關注前面所有高峰上的高音,一直到樂曲的開頭。圖中顯示了一個查詢向量(所有的注意力線來源)和正要處理的以前的記憶(突出了有更高 softmax 概率的音符)。注意力線的顏色對應于不同的注意力頭,而寬度對應于 softmax 概率的權重。 如果你想進一步了解這種音符的表征,請觀看視頻。 結語至此,我們的 GPT-2 的完全解讀,以及對父類模型(只包含解碼器的 transformer)的分析就到此結束了。希望讀者能通過這篇文章對自注意力機制有更好的理解。在了解了 transformer 內部的工作原理之后,下次再遇到它,你將更加得心應手。 該文章在 2024/1/16 8:48:34 編輯過 |
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886