select count (*) from articleselect * from article order by publish_time desc limit 0 ,20 這個操作是一般我們的常規分頁操作,先進行total然后進行分頁獲取,這種做法的好處是支持任意規則的分頁,缺點就是需要查詢兩次,一次count、一次limit,當然后期數據量實在太大可以只需要第一次count,但是也有一個問題,就是如果數據量一直在變化,會出現下一次分頁中,還會有上一次的部分數據,因為數據在不斷地新增,你的分頁沒跟上發布的速度那么就會有這個情況發生。
瀑布流分頁
除了上述常規分頁操作外,我們針對特定順序的分頁也可以進行特定的分頁方式來實現高性能,因為基于大前提我們是大數量下的瀑布流,我們的文章假設是以雪花id作為主鍵,那么我們的分頁可以這么寫:
select * from article where id <last_id order by publish_time desc limit 0 ,20 首先我們來分析一下,這個語句是利用了插入的數據分布是順序和你需要查詢的排序一致來實現的,又因為id不會重復,并且雪花id的順序和時間是一致的都是同向的,所以可以利用這種方式來進行排序,limit每次不需要跳過任何數目,直接獲取需要的數目即可,只需要傳遞上一次的查詢結果的id即可,這個方式彌補了上述常規分頁帶來的問題,并且擁有非常高的性能,但是缺點也顯而易見,不支持跳頁,不支持任意排序,所以這個方式目前來說非常適合前端app的瀑布流排序。
分片下的實現
首先分片下需要實現這個功能我們需要有id支持分片,并且publish_time按時間分表,兩者缺一不可。
原理
假設文章表article我們是以publish_time作為分片字段,假設按天分表,那么我們會擁有如下的表:
article_20220101、article_20220102、article_20220103、article_20220104、article_20220105、article_20220106......
雪花id輔助分片
因為 雪花id 可以反解析出時間,所以我們對雪花id的 = , >= , > , <= , < , contains 的操作都是可以進行輔助分片進行縮小分片范圍,假設我們的 雪花id 解析出來是2021-01-05 11:11:11,那么針對這個 雪花id 的 < 小于操作我們可以等價于 x < 2021-01-05 11:11:11 ,那么如果我問你這下我們需要查詢的表有哪些,很明顯 [article_20220101、article_20220102、article_20220103、article_20220104、article_20220105],除了20220106外我們都需要查詢。
union all分片模式
如果你使用union all的分片模式,那么通常會將20220101-20220105的所有的表進行union all,然后機械能過濾,那么優點可想而知:簡單,連接數消耗僅1個,sql語句支持的多,缺點也顯而易見,優化起來后期是個很大的問題,并且跨庫下的使用有問題。
select * from select * from article_20220101 union all select * from article_20220102 union all select * from article_20220103....) twhere id <last_id order by publish_time desc limit 0 ,20 流式分片,順序查詢 如果你是流式分片模式進行聚合,通常我們會將20220101-20220105的所有的表進行并行的分別查詢,然后針對每個查詢的結果集進行優先級隊列的排序后獲取,優點:語句簡單便于優化、性能可控、支持分庫,缺點:實現復雜,連接數消耗多。
select * from article_20220101 where id <last_id order by publish_time desc limit 0 ,20 select * from article_20220102where id <last_id order by publish_time desc limit 0 ,20 select * from article_20220103 where id <last_id order by publish_time desc limit 0 ,20 流式分片下的優化 目前 ShardingCore 采用的是流式聚合+union all,當且僅當用戶手動3調用 UseUnionAllMerge 時會將分片sql轉成union all 聚合。
針對上述瀑布流的分頁 ShardingCore 是這么操作的:
確定分片表的順序,也就是因為分片字段是 publish_time ,又因為排序字段是 publish_time 所以分片表其實是有順序的,也就是[article_20220105、article_20220104、article_20220103、article_20220102、article_20220101],因為我們是開啟n個并發線程所以這個排序可能沒有意義,但是如果我們是僅開啟設置單個連接并發的時候,程序將現在通過 id<last_id 進行表篩選,之后依次從大到小進行獲取直到滿足skip+take,也就是0+20=20條數據后,進行直接拋棄剩余查詢返回結果,那么本次查詢基本上就是和單表查詢一樣,因為基本上最多跨兩張表基本可以滿足要求(具體場景不一定)。 說明:假設 last_id 反解析出來的結果是2022-01-04 05:05:05,那么可以基本上排除 article_20220105 ,判斷并發連接數如果是1,那么直接查詢 article_20220104 ,如果不滿足繼續查詢 article_20220103 ,直到查詢結果為20條;如果并發連接數是2,那么查詢 [article_20220104、article_20220103] ,如果不滿足,繼續下面兩張表,直到獲取到結果為20條數據,所以我們可以很清晰的了解其工作原理并且來優化。 說明
通過上述優化可以保證流式聚合查詢在順序查詢下的高性能O(1) 通過上述優化可以保證客戶端分片擁有最小化連接數控制 設置合理的主鍵可以有效的解決我們在大數據分片下的性能優化 實踐 ShardingCore 目前針對分片查詢進行了不斷地優化和盡可能的無業務代碼入侵來實現高性能分片查詢聚合。
接下來我將為大家展示一款dotnet下唯一一款全自動路由、多字段分片、無代碼入侵、高性能順序查詢的框架 在傳統數據庫領域下的分片功能,如果你使用過我相信你一定會愛上他。
第一步 安裝依賴
# ShardingCore核心框架 版本6.4.2.4+ PM> Install-Package ShardingCore # 數據庫驅動這邊選擇的是mysql的社區驅動 efcore6最新版本即可 PM> Install-Package Pomelo.EntityFrameworkCore.MySql 第二步 添加對象和上下文 有很多朋友問我一定需要使用fluentapi來使用 ShardingCore 嗎?只是個人喜好,這邊我才用dbset+attribute來實現:
//文章表 Table(nameof(Article)) ]public class Article MaxLength(128) ]Key ]public string Id { get ; set ; }MaxLength(128) ]Required ]public string Title { get ; set ; }MaxLength(256) ]Required ]public string Content { get ; set ; }public DateTime PublishTime { get ; set ; }public class MyDbContext :AbstractShardingDbContext ,IShardingTableDbContext public MyDbContext (DbContextOptions<MyDbContext> options ) : base (options )public IRouteTail RouteTail { get ; set ; }public DbSet<Article> Articles { get ; set ; }第三步 添加文章路由 public class ArticleRoute :AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute <Article >public override void Configure (EntityMetadataTableBuilder<Article> builder )public override bool AutoCreateTableByTime ()return true ;public override DateTime GetBeginTime ()return new DateTime(2022 , 3 , 1 );到目前為止基本上Article已經支持了按天分表。
第四步 添加查詢配置,讓框架知道我們是順序分表且定義分表的順序
public class TailDayReverseComparer : IComparer <string >public int Compare (string ? x, string ? y//程序默認使用的是正序也就是按時間正序排序我們需要使用倒序所以直接調用原生的比較器然后乘以負一即可 return Comparer<string >.Default.Compare(x, y) * -1 ;//當前查詢滿足的復核條件必須是單個分片對象的查詢,可以join普通非分片表 public class ArticleEntityQueryConfiguration :IEntityQueryConfiguration <Article >public void Configure (EntityQueryBuilder<Article> builder )//設置默認的框架針對Article的排序順序,這邊設置的是倒序 new TailDayReverseComparer());/// /如下設置和上述是一樣的效果讓框架真對Article的后綴排序使用倒序//builder.ShardingTailComparer(Comparer<string>.Default, false); //簡單解釋一下下面這個配置的意思 //第一個參數表名Article的哪個屬性是順序排序和Tail按天排序是一樣的這邊使用了PublishTime //第二個參數表示對屬性PublishTime asc時是否和上述配置的ShardingTailComparer一致,true表示一致,很明顯這邊是相反的因為默認已經設置了tail排序是倒序 //第三個參數表示是否是Article屬性才可以,這邊設置的是名稱一樣也可以,因為考慮到匿名對象的select false ,SeqOrderMatchEnum.Owner|SeqOrderMatchEnum.Named);//這邊為了演示使用的id是簡單的時間格式化所以和時間的配置一樣 false ,SeqOrderMatchEnum.Owner|SeqOrderMatchEnum.Named);//這邊設置如果本次查詢默認沒有帶上述配置的order的時候才用何種排序手段 //第一個參數表示是否和ShardingTailComparer配置的一樣,目前配置的是倒序,也就是從最近時間開始查詢,如果是false就是從最早的時間開始查詢 //后面配置的是熔斷器,也就是復核熔斷條件的比如FirstOrDefault只需要滿足一個就可以熔斷 true , CircuitBreakerMethodNameEnum.Enumerator, CircuitBreakerMethodNameEnum.FirstOrDefault);//這邊配置的是當使用順序查詢配置的時候默認開啟的連接數限制是多少,startup一開始可以設置一個默認是當前cpu的線程數,這邊優化到只需要一個線程即可,當然如果跨表那么就是串行執行 1 , LimitMethodNameEnum.Enumerator, LimitMethodNameEnum.FirstOrDefault);第五步 添加配置到路由 public class ArticleRoute :AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute <Article >//省略..... public override IEntityQueryConfiguration<Article> CreateEntityQueryConfiguration ()return new ArticleEntityQueryConfiguration();第六步 startup配置 var builder = WebApplication.CreateBuilder(args);// Add services to the container. true ;true ;"c1" ;new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);"ds0" , "server=127.0.0.1;port=3306;database=ShardingWaterfallDB;userid=root;password=root;" );new MySqlTableEnsureManager<MyDbContext>());var app = builder.Build();using (var scope = app.Services.CreateScope())var myDbContext = scope.ServiceProvider.GetRequiredService<MyDbContext>();if (!myDbContext.Articles.Any())new List<Article>();var beginTime = new DateTime(2022 , 3 , 1 , 1 , 1 ,1 );for (int i = 0 ; i < 70 ; i++)var article = new Article();"yyyyMMddHHmmss" );"標題" + i;"內容" + i;2 ).AddMinutes(3 ).AddSeconds(4 );第七步 編寫查詢表達式 public async Task<IActionResult> Waterfall ([FromQuery] string lastId,[FromQuery]int take )$"-----------開始查詢,lastId:[{lastId} ],take:[{take} ]-----------" );var list = await _myDbContext.Articles.WhereIf(o => String.Compare(o.Id, lastId) < 0 ,!string .IsNullOrWhiteSpace(lastId)).Take(take)..OrderByDescending(o => o.PublishTime)ToListAsync();return Ok(list);運行程序
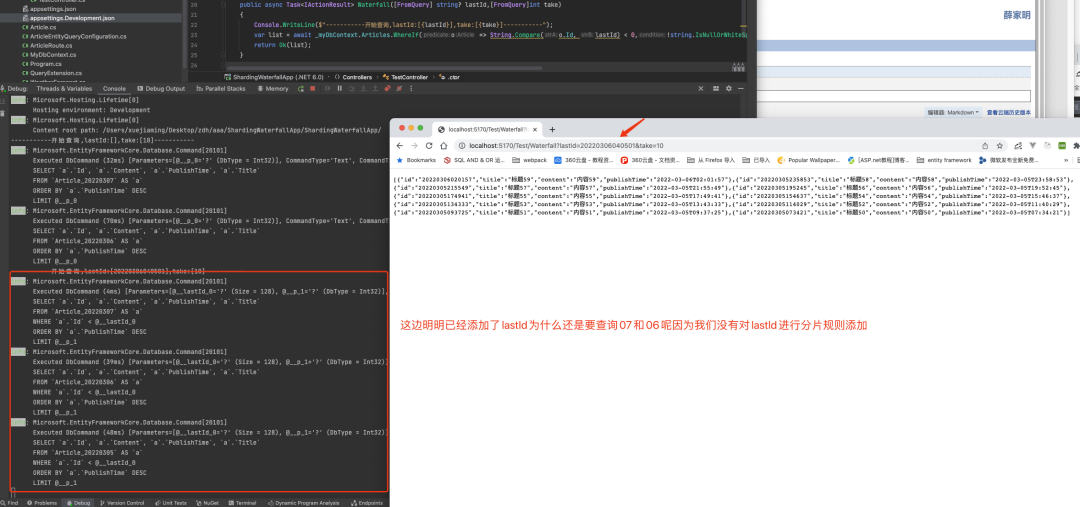
因為07表是沒有的,所以這次查詢會查詢07和06表,之后我們進行下一次分頁傳入上次id:
因為沒有對 Article.Id 進行分片路由的規則編寫,所以沒辦法進行對id的過濾,那么接下來我們配置 Id 的分片規則。
首先針對 ArticleRoute 進行代碼編寫:
public class ArticleRoute :AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute <Article >public override void Configure (EntityMetadataTableBuilder<Article> builder )public override bool AutoCreateTableByTime ()return true ;public override DateTime GetBeginTime ()return new DateTime(2022 , 3 , 1 );public override IEntityQueryConfiguration<Article> CreateEntityQueryConfiguration ()return new ArticleEntityQueryConfiguration();public override Expression<Func<string , bool >> GetExtraRouteFilter(object shardingKey, ShardingOperatorEnum shardingOperator, string shardingPropertyName)switch (shardingPropertyName)case nameof (Article.Id ): return GetArticleIdRouteFilter (shardingKey, shardingOperator )return base .GetExtraRouteFilter(shardingKey, shardingOperator, shardingPropertyName);/// <summary> /// 文章id的路由/// </summary> /// <param name="shardingKey"></param> /// <param name="shardingOperator"></param> /// <returns></returns> private Expression<Func<string , bool >> GetArticleIdRouteFilter(object shardingKey,//將分表字段轉成訂單編號 var id = shardingKey?.ToString() ?? string .Empty;//判斷訂單編號是否是我們符合的格式 if (!CheckArticleId(id, out var orderTime))//如果格式不一樣就直接返回false那么本次查詢因為是and鏈接的所以本次查詢不會經過任何路由,可以有效的防止惡意攻擊 return tail => false ;//當前時間的tail var currentTail = TimeFormatToTail(orderTime);//因為是按月分表所以獲取下個月的時間判斷id是否是在臨界點創建的 //var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(DateTime.Now);//這個是錯誤的 var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(orderTime);if (orderTime.AddSeconds(10 ) > nextMonthFirstDay)var nextTail = TimeFormatToTail(nextMonthFirstDay);return DoArticleIdFilter(shardingOperator, orderTime, currentTail, nextTail);//因為是按月分表所以獲取這個月月初的時間判斷id是否是在臨界點創建的 //if (orderTime.AddSeconds(-10) < ShardingCoreHelper.GetCurrentMonthFirstDay(DateTime.Now))//這個是錯誤的 if (orderTime.AddSeconds(-10 ) < ShardingCoreHelper.GetCurrentMonthFirstDay(orderTime))//上個月tail var previewTail = TimeFormatToTail(orderTime.AddSeconds(-10 ));return DoArticleIdFilter(shardingOperator, orderTime, previewTail, currentTail);return DoArticleIdFilter(shardingOperator, orderTime, currentTail, currentTail);private Expression<Func<string , bool >> DoArticleIdFilter(ShardingOperatorEnum shardingOperator, DateTime shardingKey, string minTail, string maxTail)switch (shardingOperator)case ShardingOperatorEnum.GreaterThan:case ShardingOperatorEnum.GreaterThanOrEqual:return tail => String.Compare(tail, minTail, StringComparison.Ordinal) >= 0 ;case ShardingOperatorEnum.LessThan:var currentMonth = ShardingCoreHelper.GetCurrentMonthFirstDay(shardingKey);//處于臨界值 o=>o.time < [2021-01-01 00:00:00] 尾巴20210101不應該被返回 if (currentMonth == shardingKey)return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) < 0 ;return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) <= 0 ;case ShardingOperatorEnum.LessThanOrEqual:return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) <= 0 ;case ShardingOperatorEnum.Equal:var isSame = minTail == maxTail;if (isSame)return tail => tail == minTail;else return tail => tail == minTail || tail == maxTail;default :return tail => true ;private bool CheckArticleId (string orderNo, out DateTime orderTime//yyyyMMddHHmmss if (orderNo.Length == 14 )if (DateTime.TryParseExact(orderNo, "yyyyMMddHHmmss" , CultureInfo.InvariantCulture,out var parseDateTime))return true ;return false ;完整路由: 針對Id進行多字段分片并且支持大于小于排序。
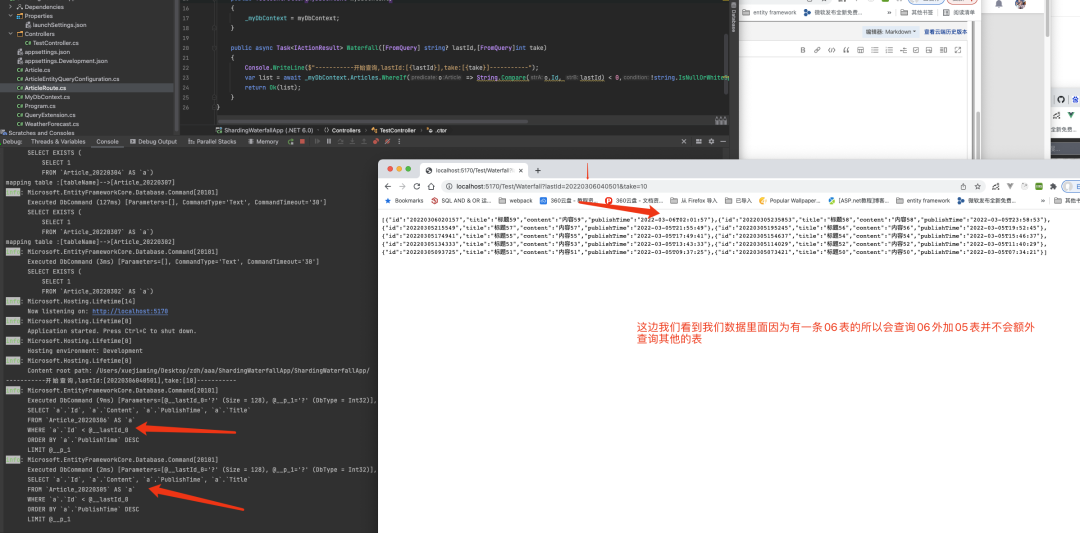
以上是多字段分片的優化, 然后我們繼續查詢看看結果:
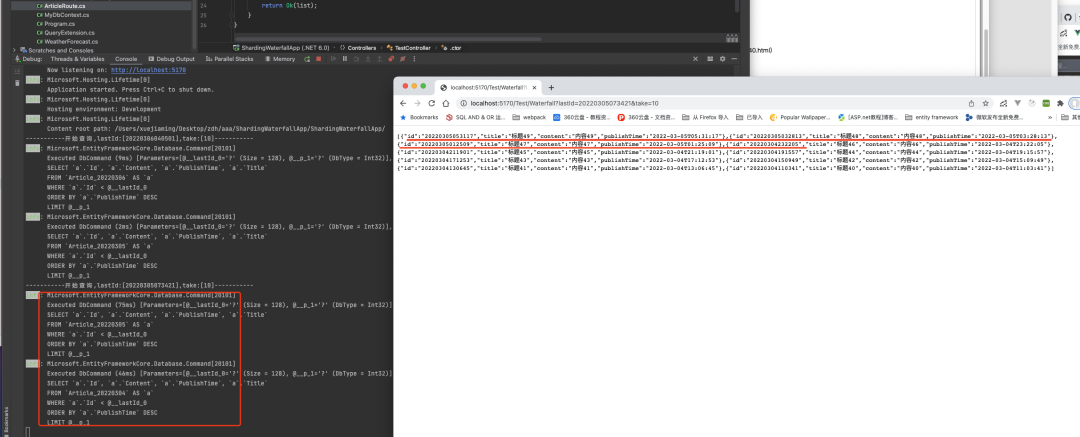
第三頁也是如此
總結 當前框架雖然是一個很年輕的框架,但是相信對其在分片領域的性能優化應該在.net現有的所有框架下找不出第二個,并且框架整個也支持union all聚合,可以滿足列入group+first的特殊語句的查詢,又有很高的性能,一個不但是全自動分片而且還是高性能框架,擁有非常多的特性性能,目標是榨干客戶端分片的最后一點性能。
最后
身位一個dotnet程序員,我相信在之前我們的分片選擇方案除了 mycat 和 shardingsphere-proxy 外,沒有一個很好的分片選擇,但是我相信通過 ShardingCore 的原理解析,你不但可以了解到大數據下分片的知識點,更加可以參與到其中或者自行實現一個,我相信只有了解了分片的原理,dotnet才會有更好的人才和未來,我們不但需要優雅的封裝,更需要的是對原理了解。
我相信未來dotnet的生態會慢慢起來配上這近乎完美的語法。






 400 186 1886
400 186 1886


