大模型長上下文運行的關鍵問題
上下文長度的增加是 LLM 的一個顯著發展趨勢。過去一年,幾種長上下文語言模型陸續問世,包括 GPT-4(32k上下文)、MosaicML 的 MPT(65k上下文)、Anthropic 的 Claude(100k上下文)等。然而,擴大 Transformer 的上下文長度是一個挑戰,因為其核心的注意力層在時間復雜度和空間復雜度與輸入序列長度的平方成正比。
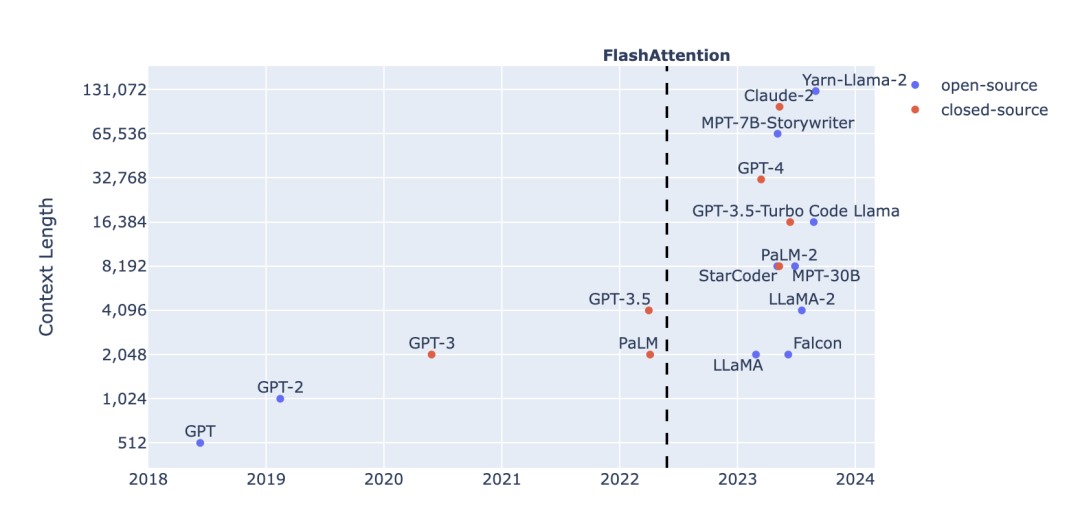
本文作者 Harm de Vries 是 ServiceNow 的研究員,也是其 LLM 實驗室的負責人。他認為,長上下文運行的問題在于缺少長預訓練數據,而非二次注意力。 本文將深入探討隨上下文長度的增加,注意力層的計算開銷情況,并指出常見預訓練數據集中序列長度的分布情況。由此,作者針對長上下文運行分析了幾個重要問題:是否在固有短序列數據上浪費了注意力計算開銷?如何創建有意義的長文本預訓練數據?是否可以在訓練過程中使用可變的序列長度?以及如何評估長上下文能力? (以下內容在遵循 CC BY-NC-SA 4.0 協議的基礎上由 OneFlow 編譯發布,譯文轉載請聯系授權。原文:https://www.harmdevries.com/post/context-length/) 作者 | Harm de Vries OneFlow編譯 翻譯|楊婷、宛子琳 長上下文運行的問題在于缺少長預訓練數據,而不是二次注意力。 上下文長度增加是語言大模型的一個顯著趨勢。上下文長度是指在 Transformer 預測下一個詞元之前,我們可以喂入到模型中的詞元數量。過去一年,長上下文 LLM(Long-context LLM)的數量顯著增加,如下圖所示。
FlashAttention 的發明是一個重要的轉折點,它以一種巧妙的方式適應了現代 GPU 對注意力計算的需求,提高了計算和內存效率。本文不會詳細介紹 FlashAttention 的技術細節,但它消除了 GPU 的內存瓶頸,使 LLM 開發者能夠將上下文長度從傳統的 2K 詞元增加至 8-65K。 有趣的是,如果你仔細觀察長上下文 LLM,就會發現其中許多都是由較小上下文窗口的基礎 LLM 微調而來的。例如:
為什么會有這兩個訓練階段呢?共有兩種可能:(1)由于注意力層的二次復雜性,使用長上下文進行訓練在計算上太過昂貴;(2)預訓練階段缺乏長序列數據。 本文將深入探討以上兩點:
綜合上述觀察結果,可以得出結論:雖然使用 16-32K 上下文窗口進行預訓練是可行的,但個別文檔的詞元分布并不適合這種方法。主要問題在于,傳統的預訓練方法將來自隨機文件的詞元打包到了上下文窗口中,這導致 16-32K 的詞元窗口中包含了許多不相關的文檔。假設在預訓練期間,LLM 能受益于更具意義的長上下文,本文認為可利用元數據創建更長的預訓練數據,例如通過超鏈接連接網頁文檔,以及通過代碼庫結構連接代碼文件。 1上下文長度對 Transformer 浮點運算(FLOP)的影響讓我們從注意力層的計算開銷開始。我們將估算訓練 Transformer 模型所需的計算量。具體來說,我們將計算模型在前向傳播和反向傳播過程中的矩陣乘法所需的浮點運算(FLOPs)。為更好地進行研究,我們將 FLOPs 分為三組:前饋層(FFN)中的稠密層,查詢、鍵、值、輸出的投影(QKVO),以及計算查詢-鍵(query-key)得分和值嵌入(value embeddings)的加權求和(Att)。 對于具有
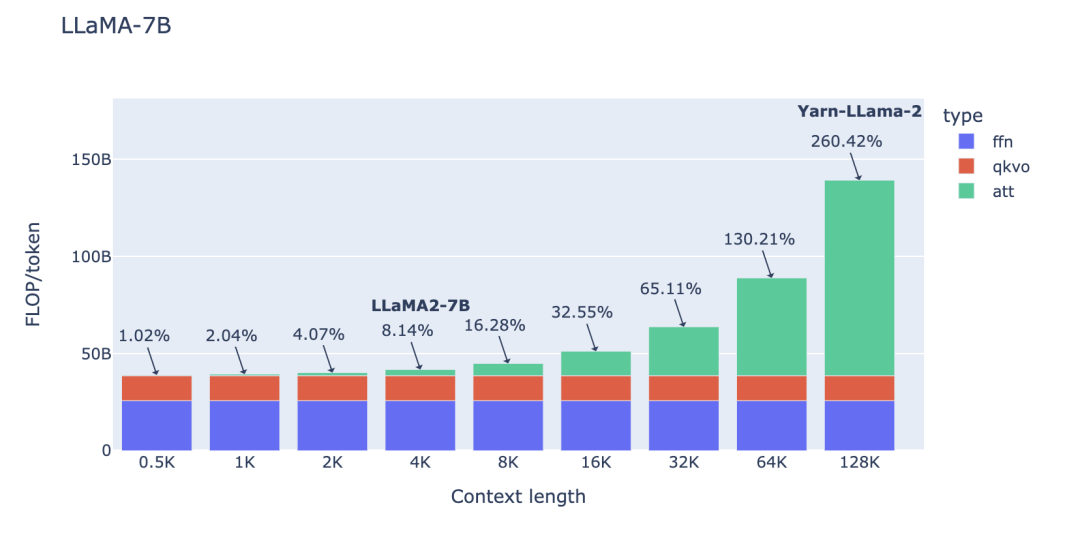
可參閱附錄以獲取詳細推導過程https://www.harmdevries.com/post/contextlength/#appendix)。值得強調的是,我們研究 FLOPs/token 以便在不同上下文長度之間進行有意義的比較。同時請注意, 現在讓我們研究一下上述三項在增加上下文長度時對總 FLOPs/token 的貢獻。下面,我們展示了 LLaMA-7B 模型的細分情況,其中
如圖所示,對于 4K 的上下文窗口,注意力 FLOPs 的貢獻相對較小(8%)。這是 LLaMA-2 和其他幾個基礎 LLM 模型的預訓練階段,其中注意力 FLOPs 對計算的影響可以忽略不計。然而,當使用 128K 的超大上下文窗口(如 Yarn-Llama-2)時,注意力 FLOPs 就成了主導因素,造成了 260% 的計算開銷。 這意味著,如果使用 2K 上下文窗口進行完整的預訓練需要 1 周時間,那么使用 128K 的上下文長度則預計需要 3.5 周的時間。當然,這是在訓練過程中使用的詞元數相同(例如通過減小批量大小)的情況下。考慮到計算時間的大幅增加,許多研究和開發人員只愿意在微調階段承擔這樣的開銷。在這兩個極端之間存在這一個有吸引力的折中方案,例如,使用 8-16K 的上下文窗口只會增加 16-33% 的計算開銷,這是可以接受的。這就是我們為 StarCoder 選擇的折中方案,它使用 8K 的上下文長度,用超過 1 萬億個詞元進行了預訓練。 許多人往往低估了模型大小對注意力計算開銷的影響程度。無論是 FFN FLOPs、QKVO FLOPs(以及模型參數)都與隱藏狀態維度
對于 GPT3-170B( 總的來說,我認為在當前的模型規模下,使用 16-32K 范圍內的基礎模型進行訓練是非常合理的。正如我將在接下來的部分中解釋的,目前的主要瓶頸是數據集不適合使用如此長的上下文進行預訓練。 2預訓練數據的序列長度接下來,我們將研究常見的預訓練數據集中的序列長度分布,首先來觀察下表中 LLaMA 模型的訓練數據。
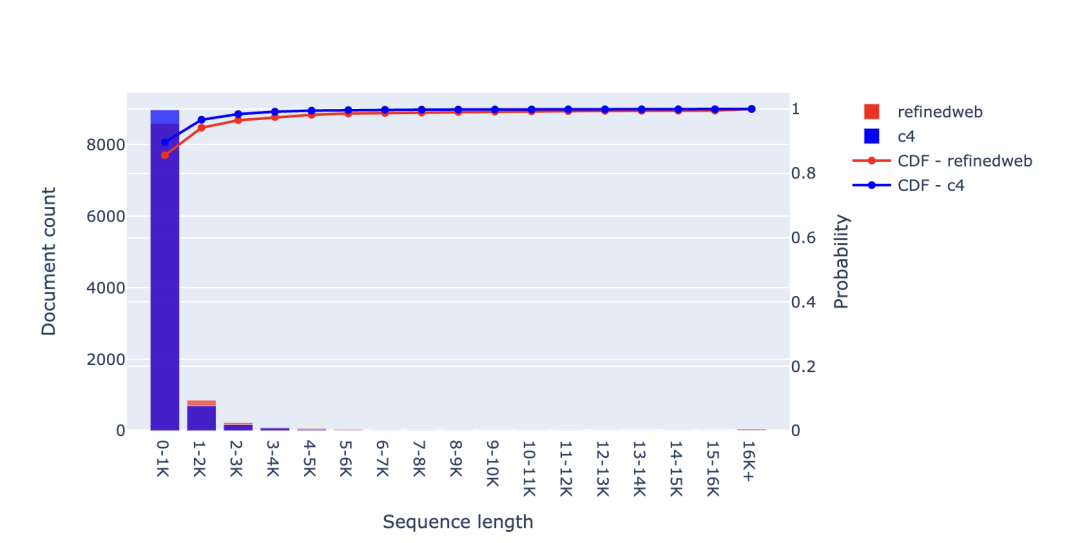
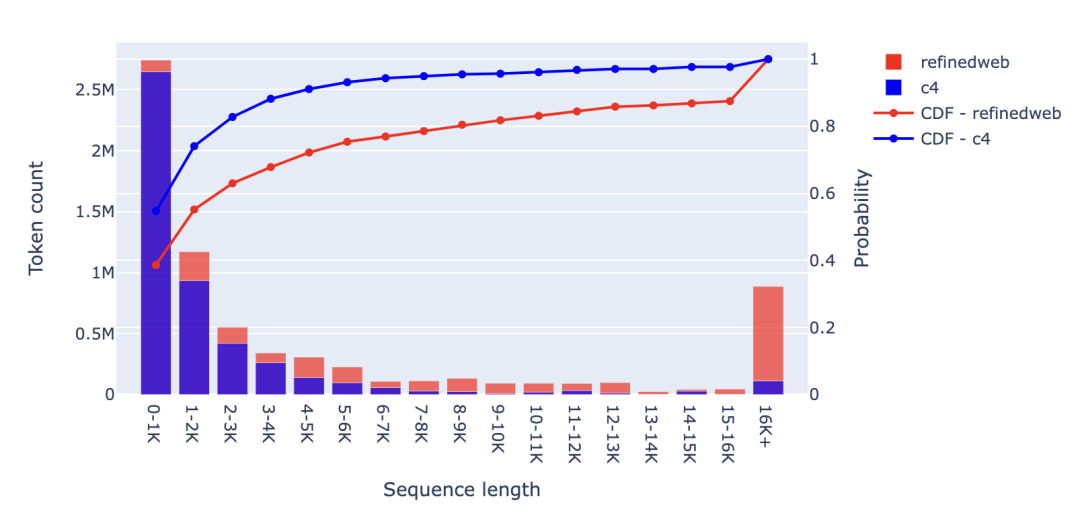
可以看到,CommonCrawl 是 LLaMA 訓練數據集的主要數據來源,CommonCrawl 是一個公開可用的互聯網抓取數據集。實際上,C4 的數據也是從 CommonCrawl 中獲取的,因此這個數據源占據了 LLaMA 訓練數據的 80% 以上。其他數據來源(如Github、ArXiv、Wikipedia和書籍)只貢獻了一小部分訓練數據。值得注意的是,MPT-30B 和 OpenLLaMA-7B 基本遵循了相同的數據分布,而 Falcon-40B 甚至僅使用了 CommonCrawl 數據進行訓練(參見 RefinedWeb 數據集)。 相反,用于代碼的 LLM 通常是在 Github 的源代碼上進行訓練的。StarCoder、Replit-3B、CodeGen2.5 和 StableCode 都使用了 The Stack,這是一個包含了 Github 上許可放寬的代碼庫構成的預訓練數據集。 我們將分析這些預訓練數據集的序列長度分布,其中主要分析 CommonCrawl 和 Github,此外,我們還會分析一些較小的數據集(如 Wikipedia 和 Gutenberg 圖書),以供參考。對于每個數據源,我們將隨機選擇 10000 個樣本,對樣本進行詞元化,并保存序列長度。隨后,我們會創建柱狀圖以可視化序列長度的分布情況,并查看每個區間(即文檔計數)有多少文檔或文件。此外,我們還將評估每個區間內的詞元數量,因為我們注意到一些較長的文件可能會對統計數據產生較大的影響。需要注意的是,對于純文本數據源(CommonCrawl、Wikipedia、Gutenberg),我們使用的是 Falcon 分詞器,而處理源代碼(The Stack)時,我們使用的是 StarCoder 分詞器。 2.1 CommonCrawl 首先,我們分析的是 CommonCrawl 數據集,并查看了 RefinedWeb 和 C4 數據集。從圖中可以看出,C4 和 RefinedWeb 中有相當大一部分的文件都相對較短,其中超 95% 的文件包含的詞元不足 2K。因此,將上下文窗口擴展到 2K 以上,只能為其中 5% 的文件捕獲更長的上下文!
然而,你可能會認為,我們關心的是每個區間內的詞元數量而不是文件數量。確實,當我們觀察下圖中的詞元數量時,情況略有不同。在 RefinedWeb 中,將近 45% 的詞元來自超 2K 個詞元的文件。因此,將上下文長度增加到 2K 以上,對于 45% 的詞元來說可能仍然是有益的。至于剩余的 55%,我們會將來自隨機文件的詞元連接到上下文窗口中。我認為,這對模型的幫助不大,甚至可能影響模型性能。 如果我們將上下文窗口擴展到 8K,那么幾乎有 80% 的詞元可以完全適應上下文窗口,換言之,只有 20% 的詞元可能會從超 8K 的更長上下文中受益。
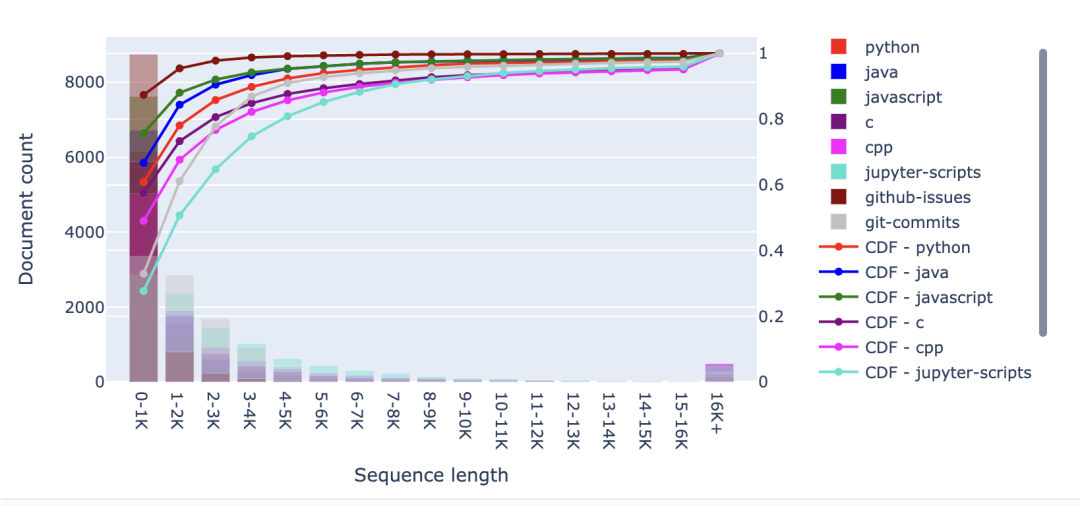
該圖表中還可以看出另一個明顯差異——即 RefinedWeb 數據集比 C4 數據集具有更多的長文件。可以看到,RefinedWeb 中超過 16K 個詞元的文件占比超 12.5%,而 C4 則不到 2.5%。有趣的是,盡管這兩個數據集都來自同一來源,但其序列長度分布的差異卻如此之大。 2.2 Github 接下來,我們來看看 starcoderdata 中的不同編程語言、Github issues 和 Jupyter Notebook, starcoderdata 是用于訓練 StarCoder 的 The Stack 子集。對于所有編程語言,我們可以觀察到大多數文件都很短:80% 以上的文件詞元量不超過 3K,Github issues 往往也比較短,只有 Jupyter Notebook 的上下文稍長,盡管超過 80% 的文件仍然少于 5K 詞元。
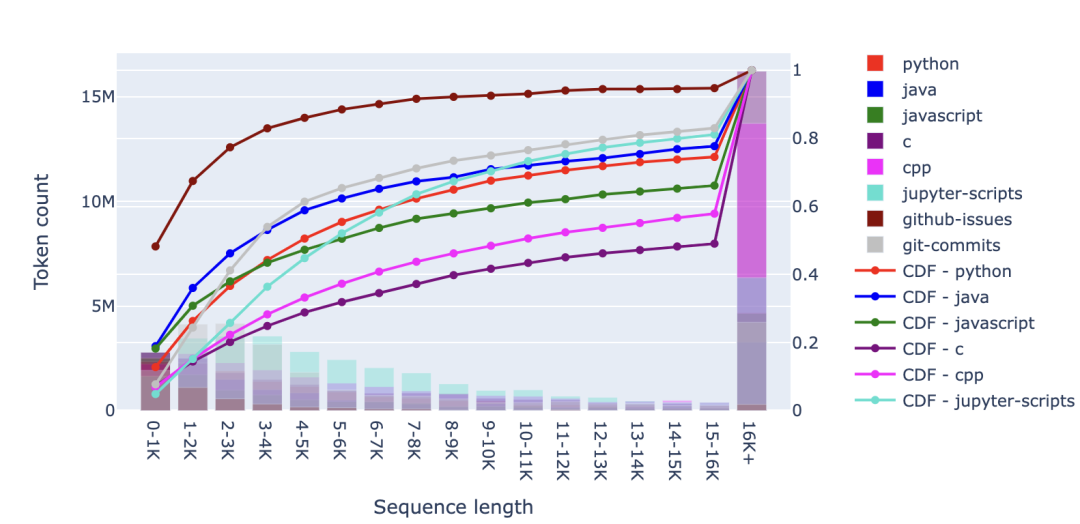
從文檔柱狀圖中,我們還可以看到 Github 中的長文件比 CommonCrawl 多。當我們觀察下面的詞元柱狀圖時,這種長尾效應更加明顯。具體而言,在 C 編程語言的情況下,超 50% 的詞元來自于超 16K 個詞元的文件——盡管這些文件的比例不到 5%!在對這些長文件進行人工檢查時,我發現有些文件的詞元超過了 300K。許多這樣的長文件似乎是大型的宏和函數集合。當然,你可能會質疑這些文件中有多少是有意義的長上下文結構。
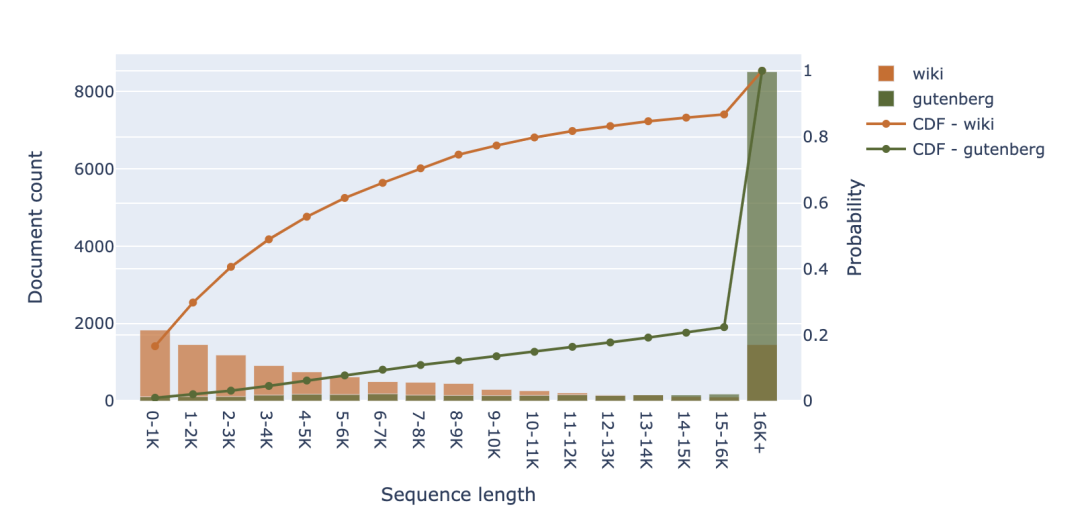
從更廣泛的視角來看,考慮到其他編程語言,可以明顯看到較長的代碼文件比 Web 文檔更多。如果排除 C 語言和 Javascript,我們會發現大約 50-70% 的詞元來自少于 8,000 個詞元的文件,而對于 RefinedWeb 數據集,這一比例接近 80%。 2.3 其他資源 正如預期的那樣,我們可以在其他預訓練數據來源(如 Wikipedia 和圖書)中可以找到更多的長文檔。在下面的柱狀圖中,我們觀察到,超 50% 的 Wikipedia 文章的詞元數超過了 4000。就圖書而言(比如 LLaMA 數據集中包含的 Gutenberg 圖書集),我們甚至發現超 75% 的圖書含有超 16000個詞元。
盡管以上圖表證實這些數據源比 CommonCrawl 和 Github 具有更多的長上下文結構,但它們在訓練數據中所占的比例通常較小。原因如下:首先這些數據源能夠提供的數據量有限,不適合大規模預訓練,例如 Wikipedia 只包含約 80GB 數據,而 CommonCrawl 則可以提供幾 TB 的數據;其次,這些數據(例如圖書)的網絡覆蓋率不足,所以模型訓練數據中的圖書比例也很少(LLaMA 為4.5%,MBT-30B 為3%)。 3 討論 3.1 是否在固有短序列數據上浪費了注意力計算開銷? 經前文分析,可以看出 CommonCrawl 和 Github 是訓練 SOTA 開源語言模型的主要數據來源,其中相當一部分(約 80-90%)示例的長度都不超過 2K 個詞元。這一結果表明,僅將上下文窗口擴展到 8-32K 可能不會帶來顯著的性能提升。在預訓練期間,我們通常將多個輸入示例組合成一個序列,直至達到最大的上下文長度。如果兩個拼接訓練示例之間沒有關聯,我們就在那些不需要彼此通信的詞元上浪費了注意力機制的計算開銷。 換句話說,盡管我們看到使用 16-32K 上下文窗口進行訓練的計算開銷對于當前模型大小來說是可行的,但在預訓練期間,我們尚未找到可有效利用這個更大的上下文窗口的方法。 3.2 如何創建有意義的長文本預訓練數據? 雖然其他來源(如書籍和科學文章)能夠提供比 CommonCrawl 和 Github 更長的上下文,但這些數據是否包含足夠的廣度和多樣性來訓練高性能的 LLM 仍然存疑。在這種情況下,一種選擇是,尋找更多樣化的長上下文數據來源,例如通過出版社獲得其他教科書或教程的許可。此外,我認為利用數據源的元數據(結構)可能是另一個可行途徑:
3.3 是否可以在訓練過程中使用可變的序列長度? 不同于將訓練分為兩個階段(即短序列的預訓練階段和長序列的微調階段),我們也可以使用多個序列長度進行訓練。具體而言,我們可以將預訓練數據劃分為不同的 bucket(如小于2K,小于 16K 等),并根據每批(或每 X 批)數據調整上下文長度。這樣,我們只需在具有長上下文的文件上承擔注意力計算開銷。當然,目前尚不清楚這種方法是否比兩階段訓練過程更加有效。 3.4 如何評估長上下文能力? 缺乏合適的基準測試也許是評估長上下文能力的一個主要障礙。雖然可以通過一些用例來進行測試,如倉庫級代碼補全或對長篇財務報告或法律合同進行問答和摘要,但我們尚未建立針對這些應用程序的良好基準測試。此外,正如 CodeLLaMA 論文所指出的,研究人員采用了一些代理任務(proxy task)來測量長代碼文件的困惑度(perplexity)或合成的上下文檢索任務(synthetic in-context retrieval task)的性能。 雖然在缺乏適當評估基準的情況下,我們無法準確評估新的長上下文語言模型的有效性。但我相信,隨著時間的推移,研究界和開源社區將解決此評估問題。目前,我所提出的擴展上下文長度的建議是否有效尚不確定,但我希望通過以上分析,能幫助讀者更好地理解上下文長度、計算開銷和(預)訓練數據之間的權衡。 4局限性
附錄:推導 Transformer 的 FLOPs Transformer 在我們開始計算 FLOPs 之前,需要定義 Transformer 模型中的運算。此處我們只關注Transformer 層,排除了詞元嵌入、位置編碼和輸出層,對于大型模型來說,這些部分的影響很小。因此,我們從嵌入
MatMul FLOPs 了解模型執行前向和后向傳播所需的浮點運算數量(FLOPs)是非常重要的背景信息。下文詳細介紹了最耗費 FLOPs 的操作:矩陣乘法。 參照矩陣乘法的數學公式
Transformer 的 FLOPs 數量 下面是 Transformer 層中不同部分所需的 FLOPs 數量。只考慮矩陣乘法,不包括層歸一化、GeLU 激活和殘差連接等逐元素操作,也不考慮執行優化 step 所需的 FLOPs 數。 FFN FLOPs
QKVO FLOPs
注意力 FLOPs
單個詞元的 FLOPs
正如下面將要討論的,因為我們沒有考慮語言模型的自回歸特性,所以這實際上高估了注意力 FLOPs。 注意力 FLOPs 被高估了 請注意,對于自回歸解碼器模型而言,詞元只會關注先前的詞元序列。這意味著注意力分數矩陣S是一個下三角矩陣,不需要計算上三角部分。因此,方程10中的計算僅需要
與 6ND FLOP 的近似關系 我們很容易就能得到 6ND 這個近似 Transformer 訓練 FLOPs 的公式 。首先,
用于訓練的詞元數 D 由 轉自:https://blog.csdn.net/OneFlow_Official/article/details/133110112 該文章在 2024/1/27 15:54:24 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886




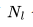 個Transformer 層、一個隱藏狀態維度
個Transformer 層、一個隱藏狀態維度 和上下文長度
和上下文長度 的模型來說,每個詞元的 FLOPs(FLOPs/token)細分如下:
的模型來說,每個詞元的 FLOPs(FLOPs/token)細分如下: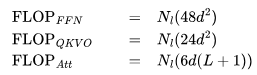
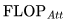 是唯一與上下文長度
是唯一與上下文長度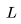 有關的項。
有關的項。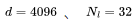 。在每個柱狀圖頂部,展示了注意力 FLOPs 的相對貢獻:
。在每個柱狀圖頂部,展示了注意力 FLOPs 的相對貢獻: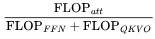 。
。
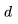 的平方成正比。對于 LLaMA-65B(
的平方成正比。對于 LLaMA-65B(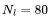 ),維度
),維度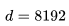 是 LLaMA-7B 大小的兩倍;這意味著,我們可以將上下文長度增加一倍,而計算開銷保持不變!換句話說,與使用 16-32K 的上下文窗口產生的開銷相同,都在 16-33% 范圍內。
是 LLaMA-7B 大小的兩倍;這意味著,我們可以將上下文長度增加一倍,而計算開銷保持不變!換句話說,與使用 16-32K 的上下文窗口產生的開銷相同,都在 16-33% 范圍內。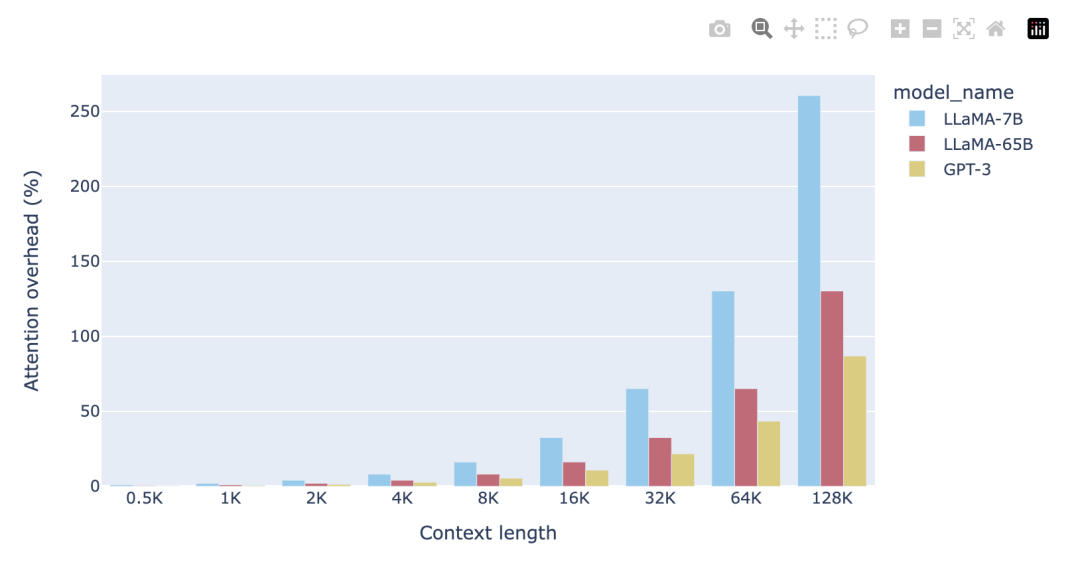
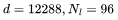 )等更大的模型,可以將上下文窗口增加到 64K,并產生幾乎相同的計算開銷(40%)。盡管我們不確定是否需要如此大的模型,詳情請參見之前的文章。
)等更大的模型,可以將上下文窗口增加到 64K,并產生幾乎相同的計算開銷(40%)。盡管我們不確定是否需要如此大的模型,詳情請參見之前的文章。
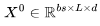 開始,然后通過 J 個 Transformer 層進行傳遞——參見下圖中的定義。需要注意的是,許多運算都是批量矩陣乘法,其中權重矩陣在第一個維度(bs)被廣播。
開始,然后通過 J 個 Transformer 層進行傳遞——參見下圖中的定義。需要注意的是,許多運算都是批量矩陣乘法,其中權重矩陣在第一個維度(bs)被廣播。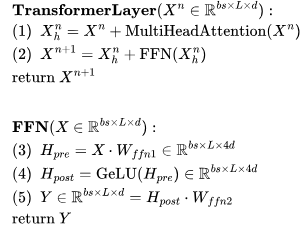

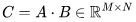 ,其中有輸入矩陣
,其中有輸入矩陣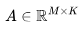 和
和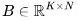 。得到的矩陣
。得到的矩陣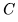 包含
包含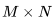 個元素, 每個元素通過對 K 個元素(element)進行點積而得到。因此,我們需要
個元素, 每個元素通過對 K 個元素(element)進行點積而得到。因此,我們需要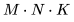 個運算來計算矩陣乘法,其中每個運算都涉及乘法和加法,因此總的 FLOPs 數量是
個運算來計算矩陣乘法,其中每個運算都涉及乘法和加法,因此總的 FLOPs 數量是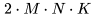 ,詳情可參考 Nvidia 的文檔(https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html)。
,詳情可參考 Nvidia 的文檔(https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html)。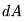 和
和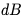 。根據 CS231n 的講座筆記,它們的計算公式如下:
。根據 CS231n 的講座筆記,它們的計算公式如下: . 因為
. 因為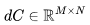 和
和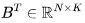 ,有
,有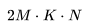 FLOPs。
FLOPs。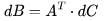 . 因為
. 因為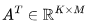 和
和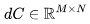 ,有
,有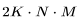 FLOPs。
FLOPs。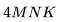 ,
,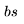 乘以
乘以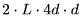 。
。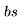 乘以
乘以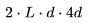 。
。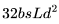 。
。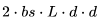 個 FLOPs。
個 FLOPs。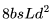 ,后向傳播的 FLOPs 數為
,后向傳播的 FLOPs 數為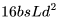
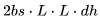 FLOPs。
FLOPs。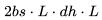 FLOPs。
FLOPs。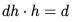 , 所以總的 FLOPs 簡化為
, 所以總的 FLOPs 簡化為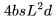 ,用于前向傳播,而后向傳播需要的 FLOPs 為
,用于前向傳播,而后向傳播需要的 FLOPs 為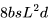 。
。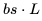 。此外,我們已經計算了單個 Transformer 層的 FLOPs,并且需要乘以
。此外,我們已經計算了單個 Transformer 層的 FLOPs,并且需要乘以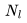 來得到總的 FLOPs。這得出以下三項:
來得到總的 FLOPs。這得出以下三項: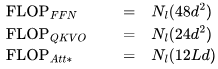
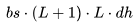 個 FLOPs。類似地,在注意力輸出計算中(方程12),矩陣P是一個下三角矩陣,因此 FLOPs 減少至
個 FLOPs。類似地,在注意力輸出計算中(方程12),矩陣P是一個下三角矩陣,因此 FLOPs 減少至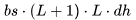 。每個詞元總的注意力 FLOPs 為:
。每個詞元總的注意力 FLOPs 為: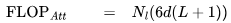
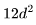 給出了Transformer 層的參數數量。因此,總的參數數量N與 FLOPs/token 之間的關系如下:
給出了Transformer 層的參數數量。因此,總的參數數量N與 FLOPs/token 之間的關系如下: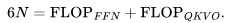
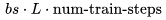 得到。值得注意的是,這個近似忽略了
得到。值得注意的是,這個近似忽略了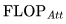 。正如我們所見,對于 2K 上下文窗口,該項很小,但對于更長的上下文窗口,它開始占主導地位。
。正如我們所見,對于 2K 上下文窗口,該項很小,但對于更長的上下文窗口,它開始占主導地位。