純c#運行開源本地大模型Mixtral-8x7B
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
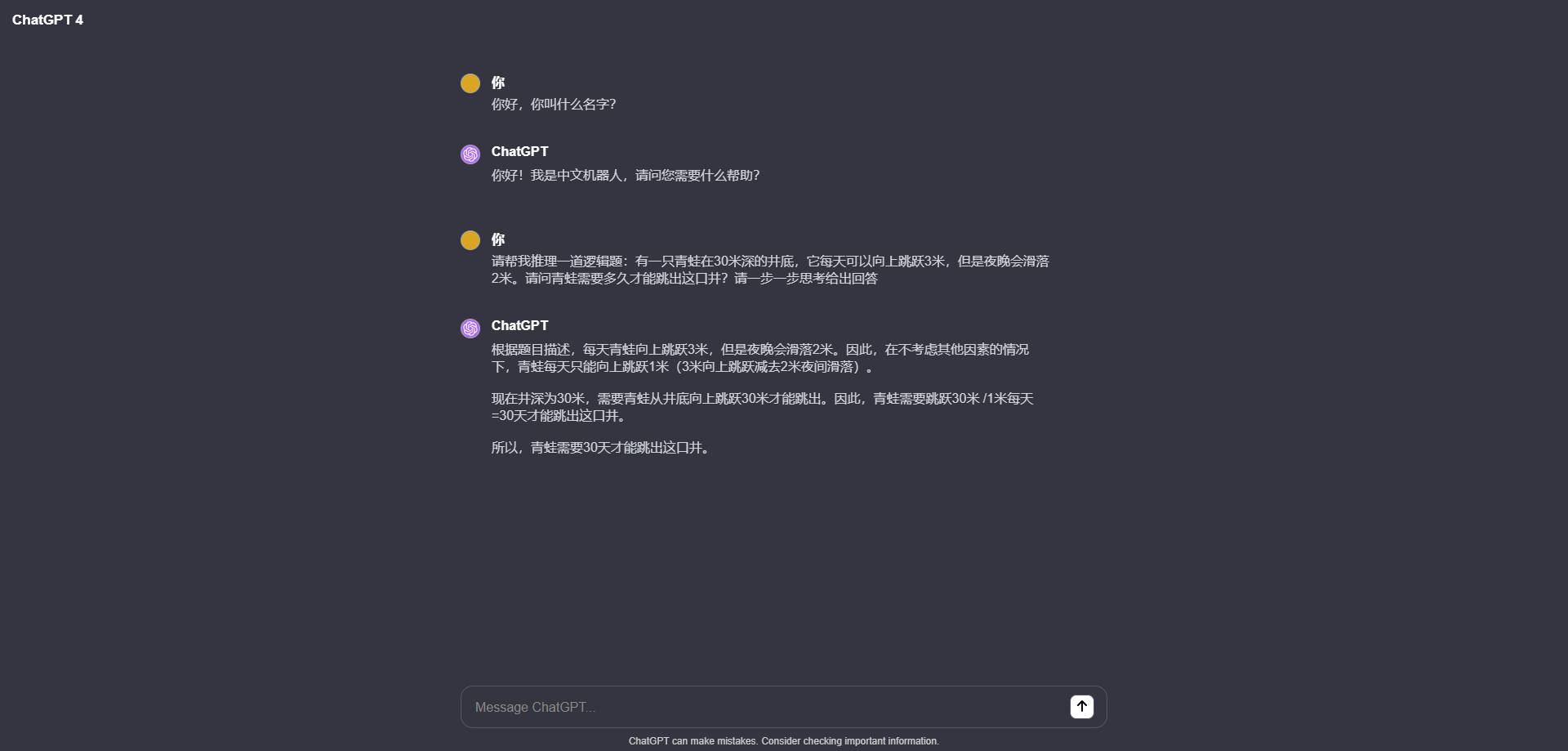
先看效果圖,這是一個比較典型的邏輯推理問題,以下是本地運行的模型和openai gpt3.5的推理對比 本地運行Mixtral-8x7B大模型:
chatgpt3.5的回答:
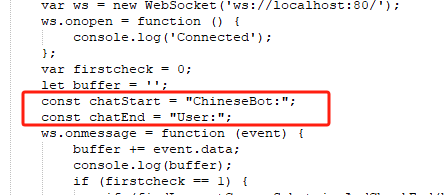
關于Mixtral 8x7B這個就不多介紹了,但凡在關注開源大模型的朋友應該知道這個模型是目前市場上最具競爭力的開源大型模型之一,其能力水平在多項任務中都有可以和gpt3.5打的有來有回,今天主要聊聊使用c#如何本地化部署實踐 整個模型部署其實相對已經比較簡單了,其核心是采用了llama.cpp這個項目,這個項目是用 ggml(一個用 c++ 開發的一個機器學習的張量庫)寫的一個推理 LLaMA 的 demo,隨著項目持續火爆吸引了大量沒有昂貴GPU 的玩家,成為了在消費級硬件上玩大模型的首選。而今天我們要用到的項目就是依賴llama.cpp的c#封裝實現的nuget包LLamaSharp,地址(https://github.com/SciSharp/LLamaSharp)。基于它對llama.cpp的c#封裝從而完成本機純c#部署大模型的實現。通過LLamaSharp既可以使用cpu進行推理,如果你有30系以上的N卡,也可以使用它的LLamaSharp.Backend.Cuda11或者Cuda12進行推理,當然其效果肯定相比純CPU推理速度更快。 整個項目我已經放到github上了,有興趣的同學可以自取:https://github.com/sd797994/LocalChatForLlama 另外關于模型格式說一下,當前使用llama.cpp主要通過gguf格式加載,這是一種專門面向llama.cpp的格式,可以通過huggingface搜索:https://huggingface.co/models?search=gguf。而我目前使用的是Nous-Hermes基于Mixtral-8x7B微調的版本,它的repo如下:https://huggingface.co/TheBloke/Nous-Hermes-2-Mixtral-8x7B-DPO-GGUF/tree/main 據說Nous-Hermes微調版本的性能略好于Mixtral-8x7B。唯一需要注意的是如果不是使用我推薦的模型,index.cshtml這里需要根據模型的實際輸出硬編碼成對應的字段:
最后的Tips:由于模型確實比較大,在純CPU模式下如果內存不太夠(一般16G)的情況下推理很緩慢,一分鐘可能也就能輸出幾個字。建議上較大內存的純CPU推理或者使用NVIDIA的顯卡安裝對應的CUDA環境后基于CUDA推理,整個效果會快很多。 作者:a1010 轉自:https://www.cnblogs.com/gmmy/p/17989497 該文章在 2024/1/27 17:49:29 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886