當面試官詢問你如何在SQL中去除重復的記錄,只保留獨一無二的值時,你是否只能想到使用DISTINCT關鍵字呢?別擔心,今天,我將分享給你6種去重方法,讓你在面試中脫穎而出。畢竟,只有一個DISTINCT也太單調了嘛!
首先,我們創建2個表并插入些數據,用于演示去重方法。
-- 創建員工表
CREATE TABLE `employees` (
`emp_id` INT ( 11 ) NOT NULL AUTO_INCREMENT,-- 員工ID,主鍵,自增
`name` VARCHAR ( 60 ) NOT NULL COMMENT '員工名字',
`position` VARCHAR ( 100 ) DEFAULT NULL COMMENT '員工職位',
`department` VARCHAR ( 100 ) DEFAULT NULL COMMENT '員工所屬部門',
`age` INT(3) COMMENT '員工年齡',
`hire_date` DATE DEFAULT NULL COMMENT '入職日期',
`birth_date` DATE DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR ( 255 ) DEFAULT NULL COMMENT '家庭住址',
`gmt_create` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',
`gmt_modified` DATETIME DEFAULT NULL COMMENT '修改時間',
PRIMARY KEY ( `emp_id` ) -- 主鍵設置為員工ID
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = '員工信息表';-- 使用InnoDB引擎,字符集為utf8mb4,表注釋為“員工信息表”
-- 創建員工工資表
CREATE TABLE `salaries` (
`salary_id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT '工資記錄ID',-- 主鍵,自增
`emp_id` INT ( 11 ) NOT NULL COMMENT '員工ID',-- 外鍵,指向employees表
`name` VARCHAR ( 60 ) NOT NULL COMMENT '員工名字',
`salary_amount` DECIMAL ( 10, 2 ) NOT NULL COMMENT '工資總額',
`payment_date` DATE NOT NULL COMMENT '發放日期',
`deductions` DECIMAL ( 10, 2 ) DEFAULT '0.00' COMMENT '扣款金額',
`net_salary` DECIMAL ( 10, 2 ) DEFAULT '0.00' COMMENT '實發工資',
`gmt_create` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',
PRIMARY KEY ( `salary_id` ),
FOREIGN KEY ( `emp_id` ) REFERENCES `employees` ( `emp_id` ) -- 外鍵約束,確保員工ID在employees表中存在
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = '員工工資信息表';
-- 插入員工數據
INSERT INTO `employees` (`name`, `position`, `department`, `age`, `hire_date`, `birth_date`, `address`, `gmt_create`, `gmt_modified`) VALUES
('員工A', '經理', '銷售部門', '35', '2021-01-01', '1990-01-01', '北京', NOW(), NULL),
('員工B', '員工', '人力資源', '25', '2022-02-02', '1992-02-02', '廣東', NOW(), NULL),
('員工C', '員工', '人力資源', '22', '2022-03-03', '1999-03-03', '上海', NOW(), NULL),
('員工D', '員工', '技術部門', '35', '2022-04-04', '1998-04-04', '山東', NOW(), NULL),
('員工D', '員工', '技術部門', '35', '2022-04-04', '1998-03-04', '上海', NOW(), NULL);
-- 插入工資數據
INSERT INTO `salaries` (`emp_id`, `name`, `salary_amount`, `payment_date`, `deductions`, `net_salary`, `gmt_create`) VALUES
(1, '員工A', 9000.00, '2023-06-30', 500.00, 8500.00, NOW()),
(2, '員工B', 4500.00, '2023-07-01', 450.00, 4050.00, NOW()),
(3, '員工C', 5900.00, '2023-06-30', 100.00, 5800.00, NOW()),
(4, '員工D', 8300.00, '2023-07-01', 200.00, 8100.00, NOW()),
(5, '員工D', 8300.00, '2023-06-30', NULL, NULL, NOW());
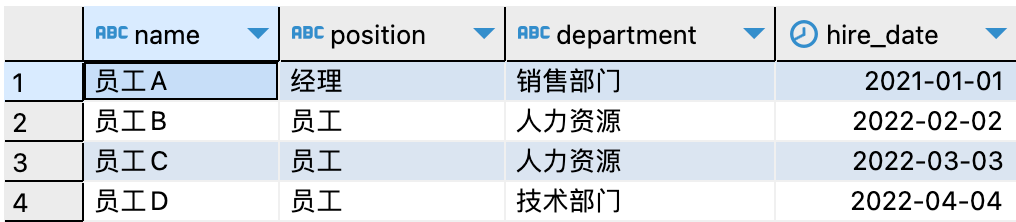
其中,employees表查詢結果如下:
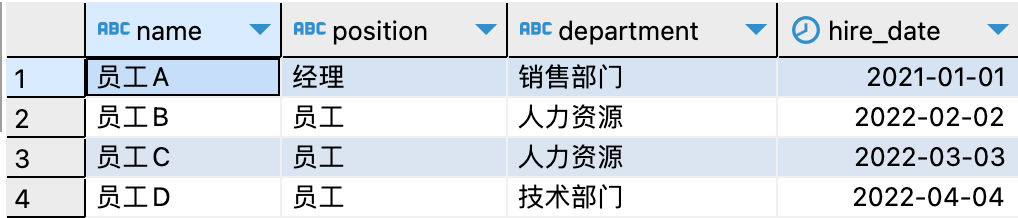
salaries表查詢結果如下:
01.
使用DISTINCT關鍵字去重
DISTINCT關鍵字是SQL中常用的去重工具。當我們使用它時,后面需明確指定要去重的字段。這樣,它將對指定的字段進行去重操作,并返回唯一的值。
1. 對單列數據去重
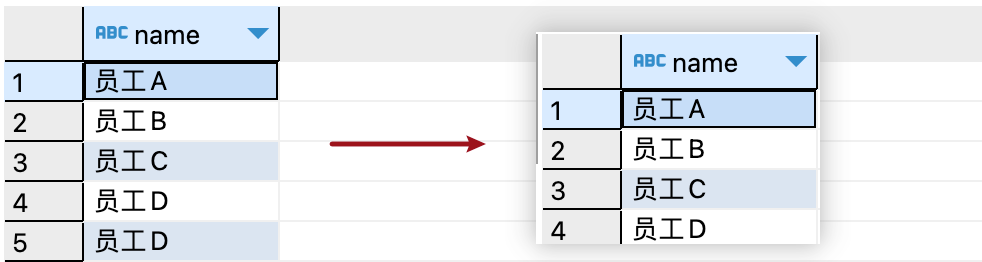
如果我們想要獲取"employees"表中不重復的name字段,可以使用以下SQL語句:
SELECT DISTINCT `name` FROM employees
查詢結果如下:
對單列使用distinct去除重復值時,會過濾掉多余重復相同的值,只返回唯一的值。
2. 對多列數據去重
如果需要對多列數據進行去重處理,只需在DISTINCT關鍵字后依次列出需要去重的字段名,并用英文逗號隔開即可。
例如,我們想要對"employees"表中name、position、department和hire_date字段去重,可以使用以下SQL語句。
SELECT DISTINCT `name`,`position`,department ,hire_date FROM employees
查詢結果如下:
可以看到department的值是有重復的,這是因為DISTINCT其實是對后面所有列名的組合進行去重。也就是name+position+department+hire_date組合成的一行在整張表中都不重復的記錄;在這里,因為name+position+department+hire_date有2個相同的數據,則過濾了一行。
使用DISTINCT關鍵字進行去重是相對簡單的。然而,需要注意的是,DISTINCT關鍵字僅對指定的字段進行去重,如果需要返回其他字段的信息,這種方法可能會受到限制。
02.
使用GROUP BY子句去重
GROUP BY關鍵字是另一種常用的去重方法。它可以將相同的值分組,并只返回每組中的一個值。同時,它還可以返回其他字段信息,實現去重的同時提供更多相關信息。以下是GROUP BY子句的2種常見去重方法:
1. 對單列數據去重
如果我們想要獲取"employees"表中不重復的name字段,可以使用以下SQL語句:
SELECT `name` FROM employees GROUP BY name
查詢結果如下:
2. 對多列數據去重
倘若我們想要對"employees"表中name、position、department和hire_date字段去重,我們嘗試使用GROUP BY子句如下:
SELECT `name`, `position`, `department`, `hire_date`
FROM employees
GROUP BY `name`
-- 執行結果如下
SQL 錯誤 [1055] [42000]: Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'tb_users.employees.position' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with
在SQL 查詢時,若是啟用了only_full_group_by 規則,那么,當在 GROUP BY 子句中沒有列出的字段,又在 SELECT 中出現且沒有使用聚合函數,就會導致錯誤。簡單來說,SELECT 中的字段要么是 GROUP BY 里的,要么就得用聚合函數處理,否則查詢會失敗。
正確語法如下:
SELECT `name`, `position`, `department`, `hire_date`
FROM employees
GROUP BY `name`, `position`, `department`, `hire_date`;
查詢結果如下:
3. 結合聚合函數
如果我們不僅想對name字段去重,還想獲取每個員工的最早出生日期,可以這樣寫:
SELECT name ,MIN(birth_date)
FROM employees e
GROUP BY e.name
查詢結果如下:
這個查詢返回了name字段的唯一值和與之相關的birth_date字段的最小值。
也就是說,我們可以使用GROUP BY返回分組字段或其他字段的聚合信息。
03.
使用NOT EXISTS子查詢去重
NOT EXISTS是一種邏輯運算符,用于判斷一個子查詢是否返回結果。如果子查詢沒有返回結果,則返回TRUE;否則返回FALSE。我們可以利用這個特性來去除重復的記錄。
倘若我們想要獲取"employees"表中重復名字中第一個出現的員工,可以使用以下SQL語句:
SELECT
e.emp_id , e.name, e.birth_date
FROM
employees e
WHERE
NOT EXISTS (
SELECT
1
FROM
employees
WHERE
name = e.name
AND emp_id < e.emp_id
);
這個查詢將返回employees表中emp_id, name和birth_date列,且排除其他員工名與當前員工相同,且他的emp_id小于當前員工的emp_id。換句話說,將返回重復名字中emp_id最小的那個員工信息。
查詢結果如下:
04.
使用LAG和LEAD函數去重
在SQL中,LAG和LEAD函數允許我們訪問結果集中的前一行和后一行的數據,這在處理時間序列數據或比較當前行與相鄰行數據時非常有用。我們可以巧妙地使用這些函數與其他SQL功能(如:GROUP BY、HAVING和DISTINCT) 結合起來實現去重的目的。
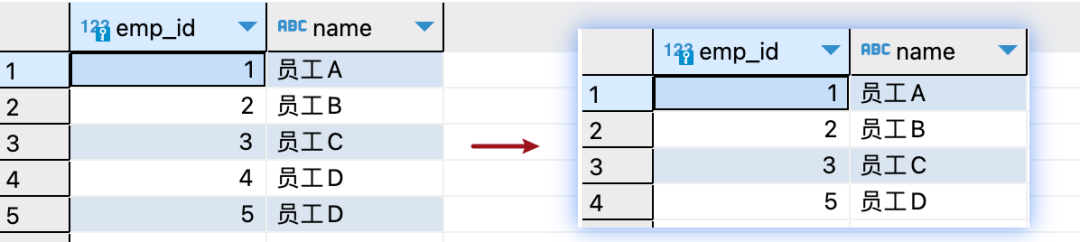
如果我們想要獲取"employees"表中不重復的emp_id、name字段,可以使用以下SQL語句:
SELECT
DISTINCT emp_id,
name
FROM
(
SELECT
emp_id,
name,
LAG(name, 1, '') OVER (
order by emp_id ) AS prev_name
FROM
employees
) AS t
WHERE
prev_name IS NULL
OR prev_name <> name;
這個語句是從employees表中選擇唯一的emp_id和name。內部查詢使用LAG函數來獲取每個emp_id的前一個name(按照emp_id排序),如果前一個name不存在,則默認為''(空字符串)。最后,在外部查詢中,我們篩選出prev_name為NULL或者prev_name與當前name不相等的記錄。這種方式可以找出名字在員工列表中發生變化的員工的emp_id和name。
查詢結果如下:
若將上述SQL語句中的LAG函數替換為LEAD函數后,我們可以訪問結果集中的后一行數據,而不是前一行數據。因此,執行結果將與原始SQL語句相反。
05.
使用IN去重
使用"IN"操作可以找到一組數據中不重復的特征,然后基于這些特征來獲取數據。這樣,我們能夠更精確地篩選出具有特定屬性的數據,確保數據的唯一性。
倘若我們想要獲取"employees"表中具有相同名字的最大"emp_id"的員工信息,可以使用以下SQL語句:
select
e.emp_id ,
e.name,
e.birth_date
from
employees e
where
emp_id in (
select
max(emp_id)
from
employees
group by
name
);
查詢結果如下:
可以看到返回了emp_id值為5的員工信息,而不是emp_id為4的員工信息。
然而,這種方法的可行性取決于表中是否存在一個唯一標識每條記錄的字段,也就是,一個數據不重復的字段,例如employees表中的emp_id字段。若表中不存在此類字段,該方法則無法適用。
06.
使用UNION去重
UNION 是 SQL 中用于合并兩個或多個 SELECT 語句的結果集的操作符。當使用 UNION 時,結果集會自動去重,即重復的行只會出現一次。這與INNER JOIN類似,都是求并集,但INNER JOIN是根據兩個或多個表的共同列來合并數據,只返回匹配的行。
倘如,我們想要獲取"employees"表中不重復的name字段,可以使用以下SQL語句:
SELECT `name` FROM employees
UNION
SELECT `name` FROM salaries;
這條語句會從 "employees" 表和 "salaries" 表中選取 "name" 字段,并通過 UNION 操作符合并結果集,確保結果中的 "name" 值是唯一的。
查詢結果如下:
🌟 使用時需注意:
1、UNION聯接的兩個表必須具有相同的列名和數據類型,否則會報錯。
2、UNION會去重,如需保留重復記錄,可使用UNION ALL。若確定結果無重復或無需去重,建議使用UNION ALL以提高效率。
除了以上提到的方法,還有許多其他的去重技巧,比如:ROW_NUMBER()窗口函數、EXCEPT運算符、SET運算符,以及INNER JOIN結合GROUP BY等。
關于SQL中去重的方法,就分享到這了~
希望這個系列能幫助大家更深入地理解和運用數據庫。
該文章在 2024/1/31 12:35:07 編輯過






 400 186 1886
400 186 1886