SQL數據庫分庫分表設計及常見問題
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
文章導讀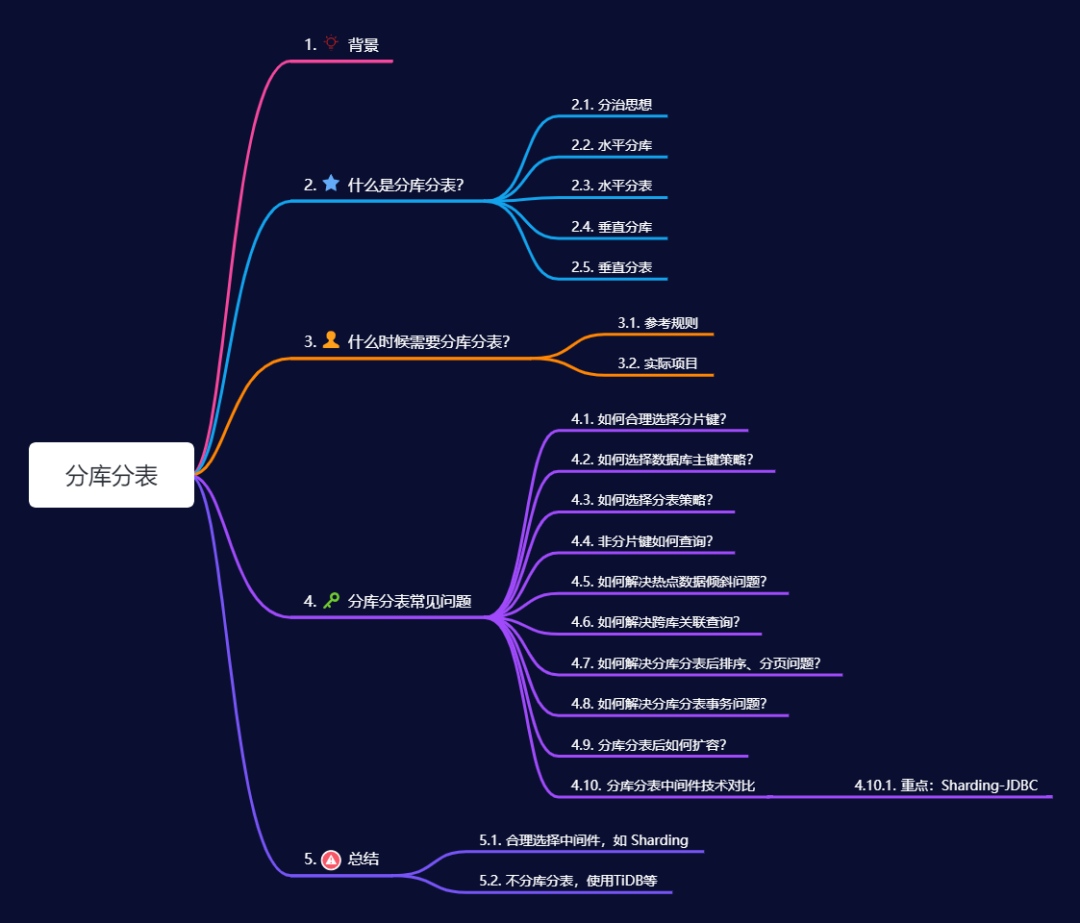 背景介紹 隨著互聯網技術的發展,數據量呈爆炸性增長。大數據量的業務場景中,數據庫成為系統性能瓶頸的一個主要因素。當單個數據庫包含了太多數據或過高的訪問量時,會出現查詢緩慢、響應時間長等問題,嚴重影響用戶體驗。為了解決這一問題, 場景分析例如:在交易系統核心數據庫設計大致包括: 產品數據庫(Product/Asset Database):存儲系統可交易的產品或資產的詳細信息,比如在股票交易系統中,這里會包含股票代碼、股票名稱、當前價格等信息。 訂單數據庫(Order Database):存儲用戶提交的訂單信息,包括訂單ID、訂單狀態(如待處理、完成、取消)、訂單創建時間等。 用戶數據庫(User Database):存儲用戶的基本信息,如用戶ID、用戶名、密碼(通常進行加密存儲)、聯系信息等,以及用戶的權限和角色定義。 交易數據庫(Transaction Database):記錄所有交易的詳細信息,如交易ID、交易類型(買入、賣出等)、交易金額、交易時間、交易雙方等。這個數據庫是交易系統的核心,需要高效且可靠。 配置數據庫(Configuration Database):存儲系統配置信息,如交易規則、費用設置、系統參數等。 歷史數據庫(Historical Data Database):保存交易、訂單和價格的歷史記錄。這對于數據分析、報告生成及監控非常重要。 賬戶數據庫(Account Database):存儲用戶的賬戶信息,包括賬戶余額、賬戶類型、賬戶狀態等。在交易系統中,賬戶信息是核心數據之一。 安全和審計數據庫(Security and Audit Database):用于記錄安全相關的事件,如登錄嘗試、權限變更等,以及審計記錄,確保系統的安全性和可追蹤性。 ...... 從上邊的分析看,對應數據庫表大致歸納為以下幾種類型:
...... 思考一般哪些表可能存在數據激增、性能問題?日志表、流水表、用戶表等都可能。而系統配置則可能相對較少。 分庫分表
分庫分表是一種數據庫架構優化技術,說白了就是一種 以訂單庫 db_order 和 訂單表 tb_order 為例(db為庫,tb為表): 水平分庫:根據某些規則(例如訂單ID的范圍)將db_order數據庫分成多個數據庫(分片),如db_order_1, db_order_2, db_order_3等。每個數據庫的表結構相同,但存儲的訂單數據不同。 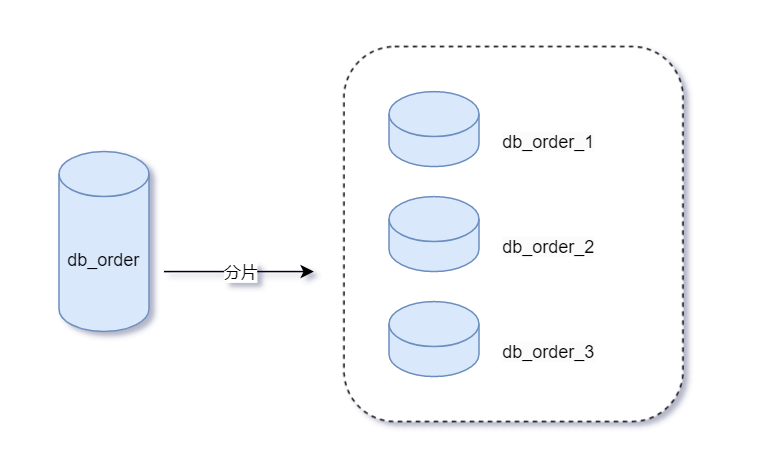 水平分表:根據訂單的創建時間,將tb_order分成tb_order_2022, tb_order_2023, tb_order_2024等多個表,每個表存儲各自時間段的訂單數據。表結構保持一致,但每個表只存儲一部分數據。  垂直分庫:根據業務功能將數據垂直分割到不同的數據庫中。例如,將訂單相關的表保留在db_order中,將用戶相關的表遷移到新的數據庫db_user中,商品相關的表遷移到db_product中。 垂直分表:若tb_order表中的字段非常多,包含了訂單的基本信息、訂單屬性信息、訂單資費信息等多個方面。此時,可以將tb_order表垂直拆分為多個表,如tb_order_base存儲訂單的基本信息,tb_order_chars存儲訂單屬性信息、tb_order_charges存儲訂單資費信息。 小結 有了以上這些了解,基本對分庫分表概念有了大致了解。對于分庫一般按照 分庫分表常見問題
參考規則根據《阿里巴巴Java開發手冊》,給出如下建議:  工程經驗事實上,通常在實戰中,一般按經驗數據達到千萬級,就需要分庫分表。原因如下: 我們知道:InnoDB管理磁盤的最小單元:頁,頁大小16KB. 在日常開發中,對于數據庫性能優化,我們首先想到的是 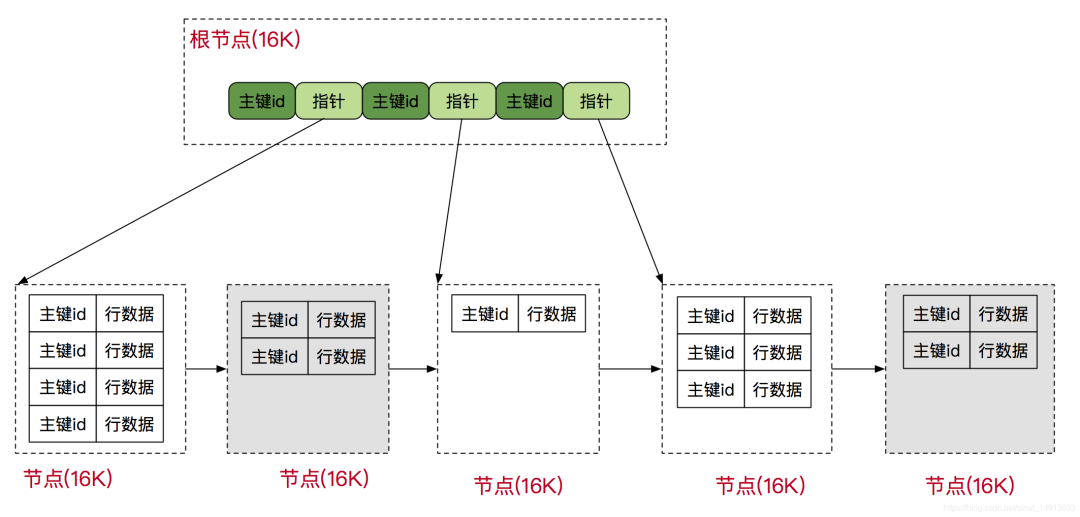 圖片來源于網絡,侵權刪 樹高為3的B+樹數據存儲計算規則: 根節點計算: 假設數據類型是bigint,大小為8b。數據本身也需要一小塊空間,用來存儲下一層索引數據頁的地址,大小為6b, 那么根節點是可以存儲16*1024/(8+6) = 1170 個數據。 其它層節點計算: 第二層:因為每個節點數據結構和跟節點一樣,而且在跟節點每個元素都會延伸出來一個節點,所以第二層的數據量是1170*1170=1368900 第三層:因為innodb的葉子節點,是直接包含整條mysql數據的,假設每條數據以1kb計算,那么第三層每個節點為16kb,那么每個節點是可以放16個數據的,所以最終mysql可以存儲的總數據為 1170 * 1170 * 16 = 21902400 (千萬級) 其實計算結果與我們平時的工作經驗也是相符的,一般mysql一張表的數據超過了千萬也是得進行分表操作了。 參考文章: MySQL一張表到底能存多少數據?[1]
例如,本節我們以訂單表的分表為例,一般訂單表中含有訂單編號:order_id, 用戶編號:user_id, 訂單創建時間:order_date等。 對于訂單表,通常我們可以考慮以下分片鍵選項: 訂單編號 優點:訂單編號通常是唯一的,可以確保每個訂單都分散到不同的分片上。這對于保證數據均勻分布和避免熱點數據非常有幫助。 用戶編號 優點:用戶編號通常也是唯一的,并且如果用戶的訂單量分布均勻,那么使用用戶編號作為分片鍵可以確保每個用戶的訂單都在同一個分片上,這對于查詢某個用戶的所有訂單非常高效。 缺點:如果用戶的訂單量差異很大,那么某些分片可能會存儲大量的訂單數據,而其他分片可能只有少量的數據。這會導致數據分布不均勻,進而影響查詢性能。 訂單創建時間 優點:適用于:按時間范圍查詢訂單的場景。 缺點:可能出現熱點數據傾斜問題(即在某個時段產生訂單峰值)
在選擇主鍵策略時,需要注意以下幾點:
在 MySQL 中進行分庫分表時,自增主鍵策略確實需要特別處理,因為傳統的自增主鍵策略在分布式環境下會導致主鍵沖突。每個數據庫實例或分片都會從相同的起始點開始自增,這會導致在不同的分片上生成相同的 ID,進而引發數據沖突。 幾種常見的主鍵策略方案:
UUID 是一個 128 位的值,具有全局唯一性,可以很好地解決分布式環境下的主鍵沖突問題。但是,UUID 字符串較長,存儲和索引效率較低,而且是無序的,可能會影響查詢性能。
通過這種結構,雪花算法可以保證生成的ID按時間遞增,并且整個分布式系統中不會有重復的ID。
總之,在分庫分表時,自增主鍵策略需要進行特殊處理,以確保全局唯一性,并根據實際情況選擇合適的方案。
選擇分庫分表的策略時,確實需要根據具體的業務場景和數據特性來決定。例如訂單表,以訂單ID ( 基于范圍的策略適用場景:當訂單ID有明確的增長趨勢,例如連續的自增ID,并且你知道未來可能的訂單數量時,范圍分表是一個好選擇。 策略實現:可以將訂單ID按照范圍劃分到不同的表中。例如,訂單ID【1-1000萬】 在表 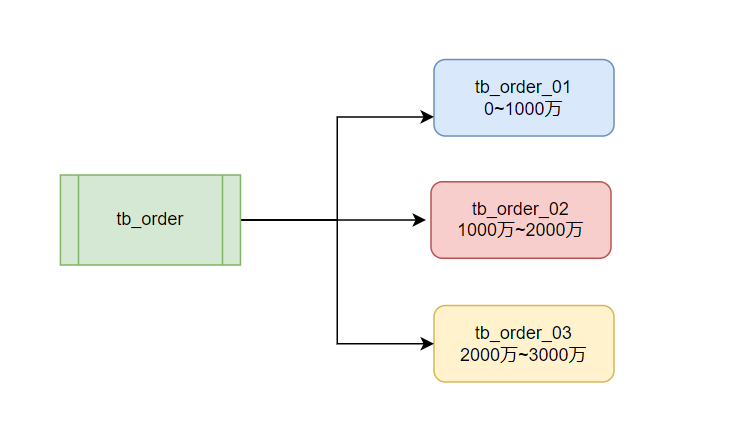 優點:
缺點:
基于哈希的策略適用場景:當訂單ID沒有明確的增長趨勢,哈希分表是一個好選擇。 策略實現:使用哈希函數對訂單ID進行哈希運算,然后根據哈希值的結果決定存儲在哪個表中。 優點:
缺點:
映射表策略適用場景:當訂單ID的分布不均,或者需要靈活控制數據分布時,映射表分表可能是一個好選擇。 策略實現:使用一個映射表來記錄每個訂單ID應該存儲在哪個表中。這個映射表可以是內存中的數據結構,也可以是數據庫中的一個表。 優點:
缺點:
一致性哈希策略適用場景:當系統需要高可用性,并且希望在添加或刪除節點時盡量減少數據遷移時,一致性哈希可能是一個好選擇。 策略實現:使用一致性哈希算法將訂單ID映射到哈希環上,然后根據哈希環上的節點(或表)來存儲數據。 一致性哈希算法的核心思想是將哈希值空間表示為一個閉合的圓環(哈希環),每個節點負責維護圓環上一段連續的哈希值范圍。 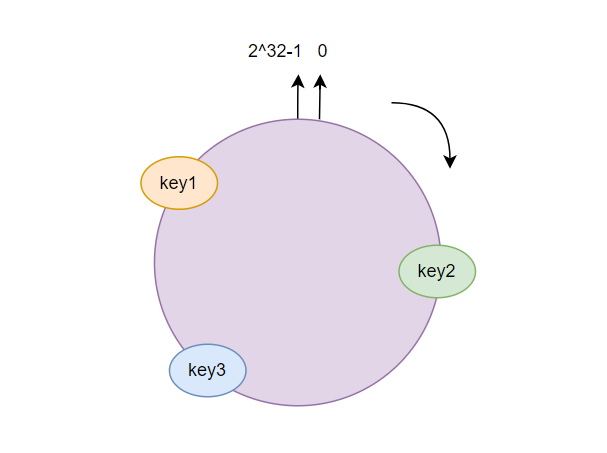 在分庫分表的場景中,可以將每個數據庫或表看作是一個節點,將這些節點均勻地分布在哈希環上。當插入或查詢數據時,根據數據的哈希值將其映射到哈希環上,然后順時針查找最近的節點(即負責該哈希值范圍的數據庫或表),將數據插入或查詢該節點。 優點:
缺點:
曾幾何時,面試過程中遇到過這樣一個問題:假設有一個用戶表,你用ID做的分片鍵,那么有一個類似于name這樣的字段如何查詢? 這里提供幾種常見的思路: 1.全局索引全局索引是一個跨所有分片的索引,它包含了非分片鍵字段和對應的分片鍵信息。查詢時,先通過全局索引找到相關的分片鍵,然后在相應的分片中查詢詳細數據。 適用場景:適用于查詢頻率高、數據量大的非分片鍵字段。 優點:查詢效率高,可以快速定位到數據所在的分片。 缺點:全局索引維護成本較高,需要定期更新以保持與分片數據的一致性。 2. 數據冗余在每個分片中存儲部分非分片鍵字段的數據。這樣,即使不直接查詢分片鍵,也可以在分片內快速找到相關數據。 適用場景:適用于查詢性能要求極高,且可以接受一定數據冗余的場景。 優點:查詢性能高,無需跨分片查詢。 缺點:數據冗余增加了存儲成本和維護復雜性。 3. 應用層處理在應用層實現復雜的查詢邏輯,將多個分片中的查詢結果匯總后進行處理。 適用場景:適用于查詢頻率不高,或者可以接受一定延遲的場景。 優點:靈活性高,可以根據業務需求定制查詢邏輯。 缺點:查詢性能可能受到網絡延遲和分片數量的影響。 4. 使用Elasticsearch(ES)將非分片鍵字段的數據同步到Elasticsearch中,利用Elasticsearch強大的搜索和查詢能力進行查詢。 適用場景:適用于非結構化數據、全文搜索、復雜查詢等場景。 優點:支持復雜的查詢操作,如全文搜索、模糊匹配等;查詢性能高,支持分布式部署。 缺點:需要維護Elasticsearch集群,增加了系統的復雜性;數據同步可能引入一定的延遲。 5. 數據庫中間件使用數據庫中間件(如ShardingSphere、MyCAT等)來管理分庫分表,中間件可以自動處理非分片鍵字段的查詢,將請求路由到正確的分片。 適用場景:適用于希望減少應用層復雜性的場景。 優點:簡化了應用層的查詢邏輯,減少了開發和維護的工作量。 缺點:需要配置和維護數據庫中間件。 總結在實際應用中,可能需要根據實際情況結合多種策略來滿足不同的查詢需求。同時,隨著業務的發展和數據量的增長,可能需要不斷調整和優化分庫分表策略。
熱點數據傾斜通常發生在某些特定的數據項(例如,用戶激增、促銷訂單峰值等)等,導致這些數據的查詢和更新操作集中在些某特定的數據庫或表上,從而造成性能瓶頸。 解決方案:采用 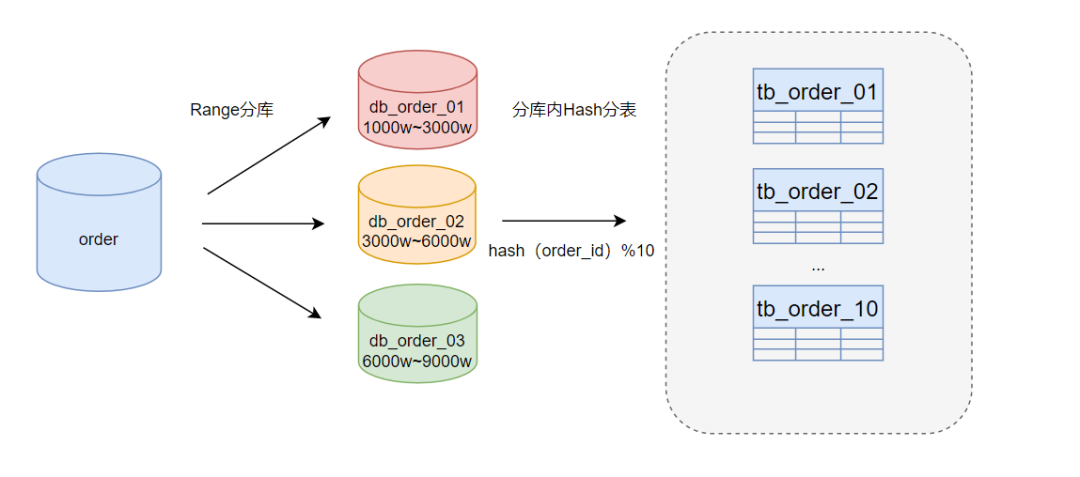
分庫分表后,數據被分散到了不同的數據庫或表中。跨庫關聯查詢成為新的問題。為了解決這個問題,可以采取以下幾種策略:
需要注意的是,雖然上述方法可以解決跨庫關聯查詢的問題,但它們也會帶來一些額外的復雜性。在設計分庫分表方案時,需要綜合考慮業務需求、數據量、查詢頻率等因素,選擇合適的策略來平衡性能和可維護性。同時,隨著業務的發展和數據量的增長,可能需要對分庫分表方案進行調整和優化。
分庫分表后,排序和分頁問題變得相對復雜,因為數據不再集中在一個單一的數據庫或表中。解決這些問題需要綜合考慮多種因素,包括數據量、查詢頻率、業務需求等。以下是一些解決分庫分表后排序和分頁問題的策略: 排序問題
分頁問題
當數據量逐漸增加,需要進行分庫分表的擴容時,可以從以下幾個方面來考慮和制定策略: 1. 數據增長評估首先,要對數據的增長趨勢進行準確的評估。通過分析歷史數據、業務發展趨勢以及用戶增長情況,可以預測未來的數據量增長情況。一般預估未來3~5年的數據增長。 2. 選擇合適的分片鍵選擇一個合適的分片鍵是分庫分表的關鍵。分片鍵應該能夠均勻分布數據,避免某些數據庫或表過載。同時,分片鍵的選擇也要考慮到查詢性能和數據一致性等因素。 3. 實施擴容基于數據增長趨勢和分片鍵的選擇,制定詳細的擴容計劃。這包括確定擴容的時間點、擴容的目標規模、數據遷移和重新分配的策略等。確保擴容過程能夠順利進行,盡可能減少對業務的影響。 4. 數據遷移與重新分配在擴容過程中,需要進行數據遷移和重新分配。這通常涉及到將現有數據從舊的數據庫或表遷移到新的數據庫或表中。可以使用數據遷移工具或自動化腳本來完成這個過程,確保數據的完整性和一致性。 5. 負載均衡在擴容后,需要確保數據在新舊數據庫或表之間均勻分布,以實現負載均衡。可以使用負載均衡器或支持分庫分表的中間件來動態分配請求,確保系統的性能和穩定性。 6. 監控與調優在擴容過程中和擴容后,需要對系統進行持續的監控和調優。通過監控數據庫或表的負載情況、查詢性能等指標,及時發現并解決性能瓶頸和故障。同時,根據實際需求進行調優,如調整索引、優化查詢語句等,以提升系統的整體性能。
業界常用的分庫分表中間有:Sharding和MyCat
ShardingSphere是一套開源的分布式數據庫中間件解決方案組成的生態圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(計劃中)這3款相互獨立的產品組成。ShardingSphere提供 優點:
缺點:
Mycat是一個開源的、跨平臺的、基于MySQL協議的數據庫中間件,支持SQL分析、SQL解析、SQL路由、SQL改寫、SQL執行和結果歸并等功能。Mycat可以實現透明的 優點:
缺點:
分庫分表后,因為數據分布在不同的數據庫和表中,需要確保不同數據庫實例間的事務一致性。解決這類分布式事務問題,可以參考個人的其它歷史文章: 總結分庫分表技術總結 一、分庫分表策略 分庫分表(Sharding)是一種將單一數據庫拆分為多個數據庫實例,以及將單一大表拆分為多個小表的技術策略。其目的是解決單一數據庫在數據量、并發訪問、性能等方面的瓶頸,提升系統的整體性能和可靠性。 常見的分庫分表策略包括:
二、分庫分表常見問題
此外,對于某些不適用分庫分表的場景,或者希望簡化分布式數據庫管理的復雜性,可以考慮使用TiDB。 參考文章鏈接: https://mp.weixin.qq.com/s/SuJ-XCaVegVunOIf69-9AQ 結尾共享即共贏。如有幫助,幫忙點贊和在看。關注公眾號【碼易有道】,定期更新一些工程實踐的總結和個人心得。歡迎你的加入,一起學習、交流、做長期且正確的事情!!! MySQL一張表到底能存多少數據?: https://www.php.cn/faq/500130.html 該文章在 2024/3/30 16:46:28 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886


