面試官:分庫分表有什么好的方案?
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
前言大家應該都知道一些哈希算法,比如MD5、SHA-1、SHA-256等,通常被用于唯一標識、安全加密、數據校驗等場景。除此之外,還有一個哈希算法是用于快速定位、分庫分表數據分配等場景。本文將以分庫分表為主題,介紹另外一種哈希算法,并詳細說明其在分庫分表中的應用與優勢。 分庫分表方法在對數據進行分庫分表時,通常有兩個策略(這里主要說的是水平分庫分表):
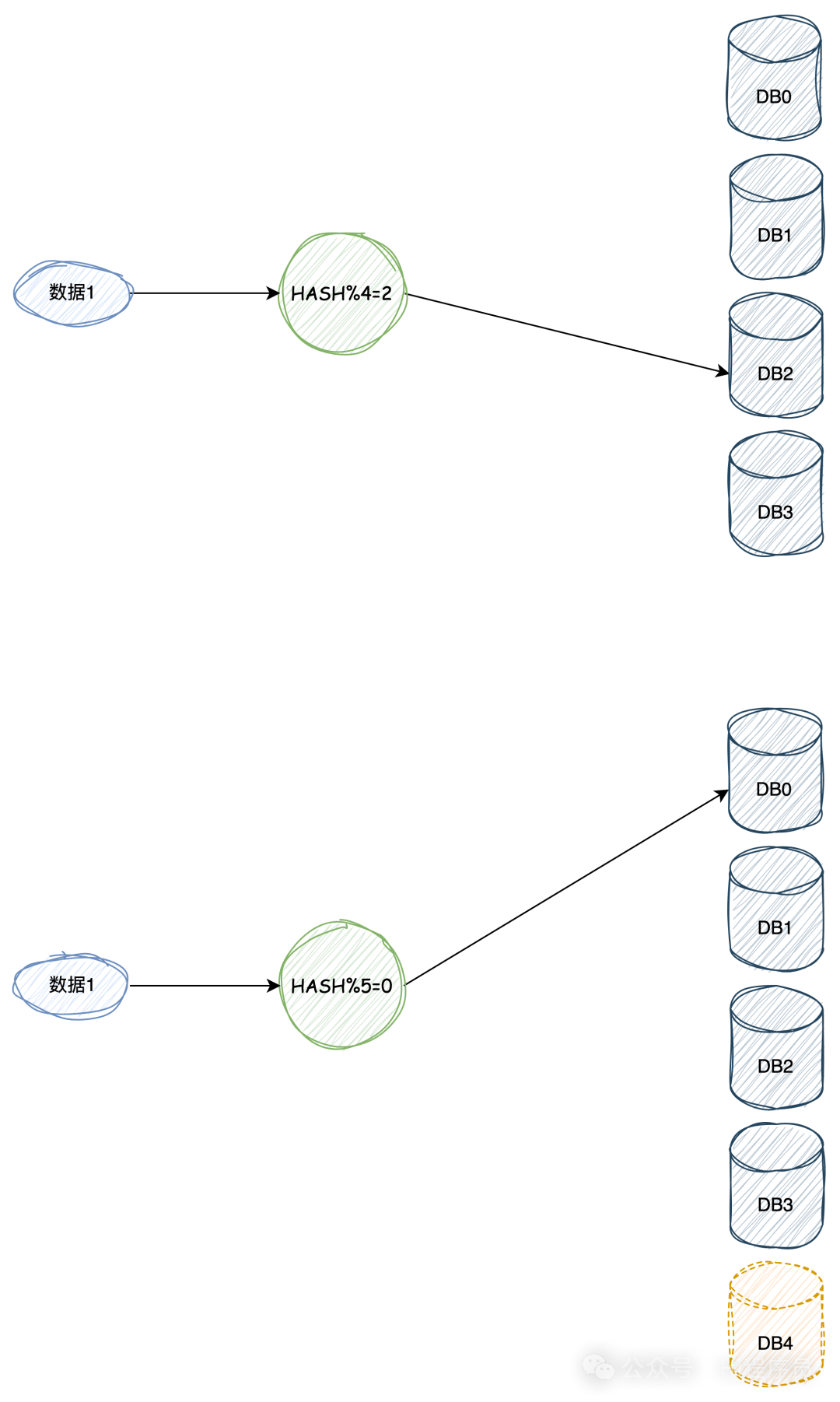
如下圖,在添加“DB4“后,數據再次進行hash后會映射到“DB0“上,如果不遷移數據就會出現問題。
很顯然,以上兩種方法都存在問題,但是哈希這種方法更能體現分庫分表的作用,但是帶來的代價是全量數據的遷移,需要考慮遷移帶來的風險,比如,遷移之后的數據一致性、完整性等各種因素。 那有沒有方法可以避免遷移,答案是沒有的,只要是使用哈希這種方式,在改變模個數后一定是要遷移數據的。 但是有一種方法可以降低遷移量以及帶來的風險,那就是一致性哈希。 一致性哈希介紹一致性哈希算法是一種特殊的哈希算法,通常用于分布式系統中,比如分布式緩存、分布式數據庫等解決數據的分配和負載均衡的場景。 與其他哈希算法一樣,具有單向性、離散性、平衡性。不同的是,一致性哈希算法在取模時這個模足夠大,比如 Fowler–Noll–Vo (FNV) 哈希函數,就是是一種高效、分布均勻的哈希函數,其模數也就是輸出域在0~2^32^-1區間。 原理 其原理是將輸出域構成一個環,數據和節點通過一致性哈希算法后映射到環中的某個點。 當需數據插入某個節點或查找數據在某個節點時,這個數據對應的哈希值只需在這個環上順時針找到第一個節點進行操作即可。當節點數量改變時,只需要重新分配一小部分數據即可,從而降低數據遷移風險。 分庫分表的應用以分庫分表為例子。 如下圖,共有3個節點(也可以理解成3個數據庫實例),經過一致性哈希算法后映射到輸出域中的某個點。 圖中的“數據1”經過相同的一致性哈希算法后也會映射到環中的某個點,這個時候如果要存儲或者查找該數據就需要順時針找到第一個節點,也就是“節點2”。 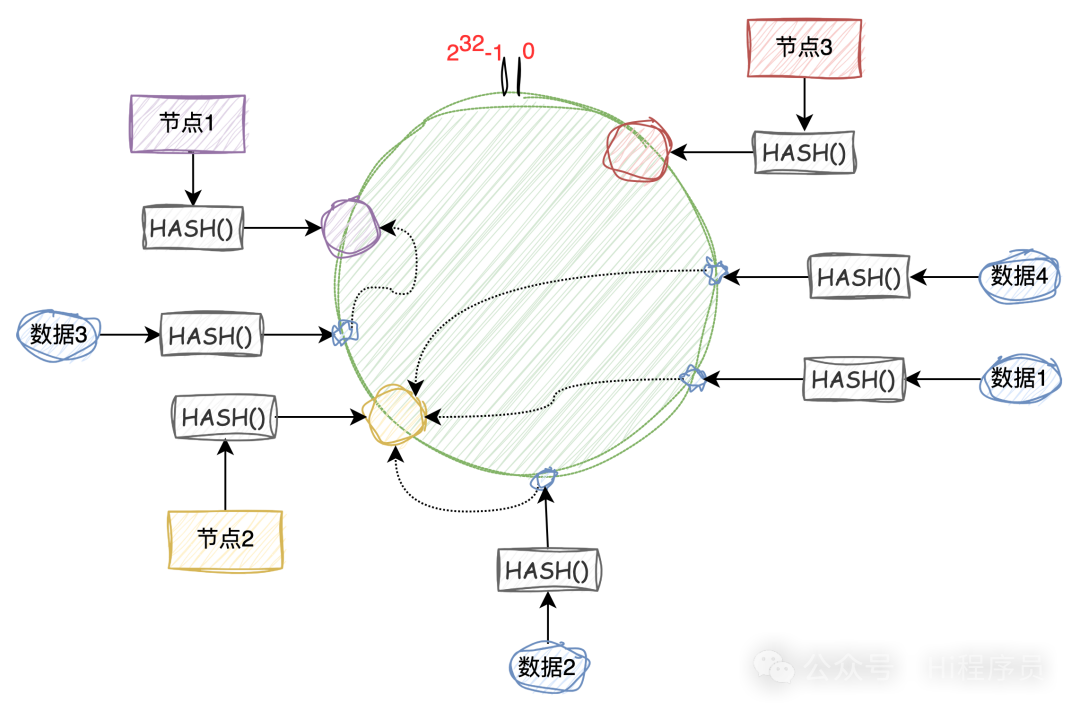
如下圖,當添加“節點4“后,只需要將“節點2“中的部分數據遷移到“節點4“中。 就是將“節點2“中的哈希值大于“節點3“小于等于“節點4“的數據遷移到“節點4“中,其它節點數據則不用遷移。 這樣在分庫分表中就最大程度減少的數據的遷移,也降低了遷移數據的風險。 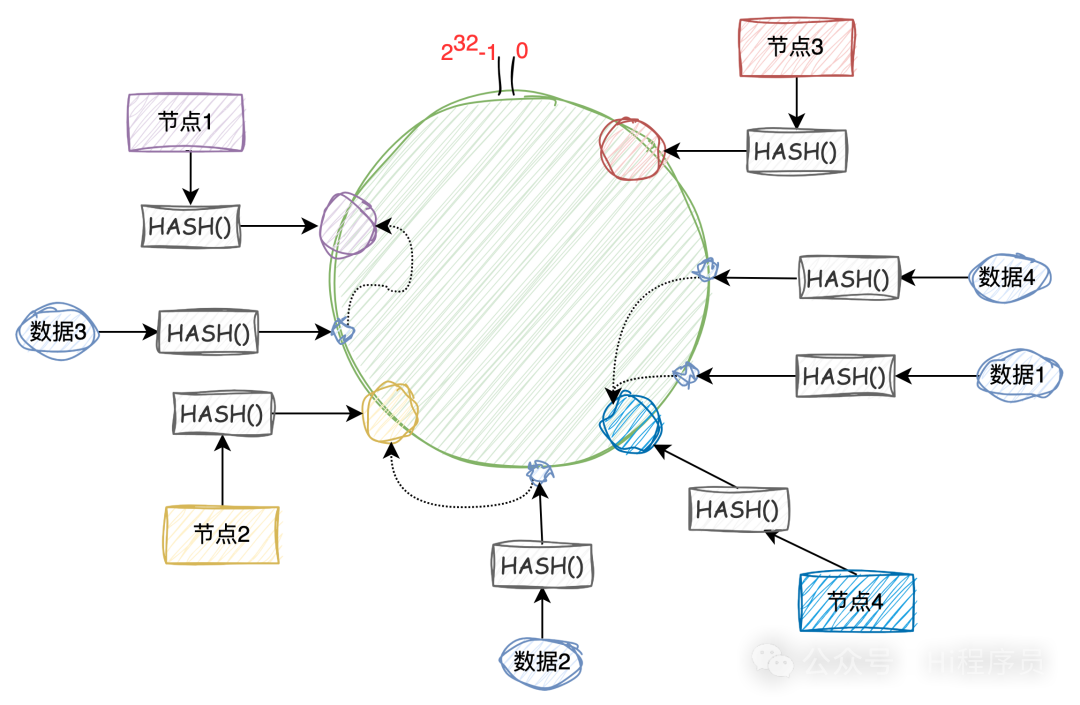 虛擬節點 通常在進行分庫分表時我們的節點個數時有限的,前期可能如圖1的分布一樣,由于節點在環中分配不均勻,數據映射到環中也不均勻,就會有大量的數據會分布到“節點2”中,同樣會造成數據傾斜問題。 怎么辦?那就讓節點分布均勻,這時候就要引入虛擬節點了。 就是說真實的節點雖然只有三個,但是我們可以讓每個節點作為大節點管理1000、10000、100000個虛擬的節點,使得每個大節點在環中分布均勻,如下圖。 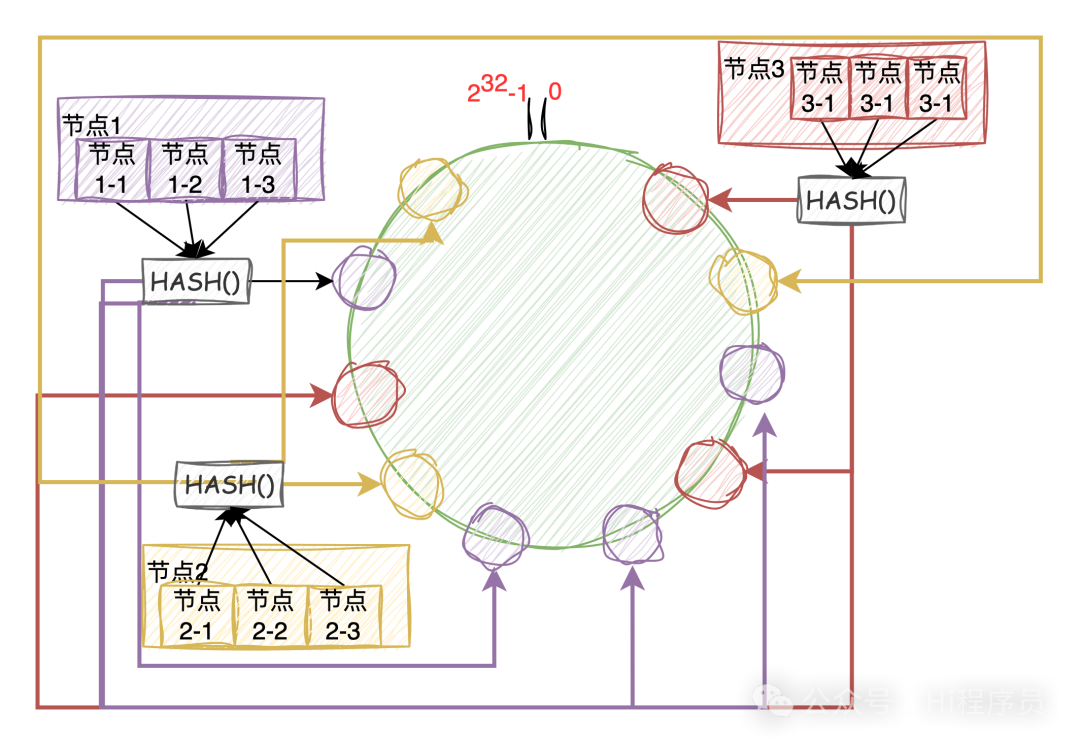 這樣,根據哈希的平衡性,數據會均勻的分布到3個大節點中,如果需要添加一個大節點,同樣是分發給虛擬節點到環上,然后根據遷移規則進行部分數據的遷移。 總結一致性哈希算法在分庫分表的應用中提供了一種高效、均勻且易于擴展的數據分布方式,同時在節點增減時最小化數據遷移成本,是一種還不錯的分庫分表方案。 該文章在 2024/4/28 20:56:03 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886