在日常業(yè)務(wù)中經(jīng)常會遇到上傳大文件的需求(如上傳一部3G大小的高清電影資源),如果大文件資源上傳不做特殊處理而直接使用小文件上傳的方式上傳到服務(wù),可能會出現(xiàn)如網(wǎng)絡(luò)不好導(dǎo)致上傳一半就失敗了,服務(wù)內(nèi)存不夠?qū)е聼o法上傳等等一些問題。那么這個特殊處理是什么處理呢?其實(shí)就是大文件的分片上傳。
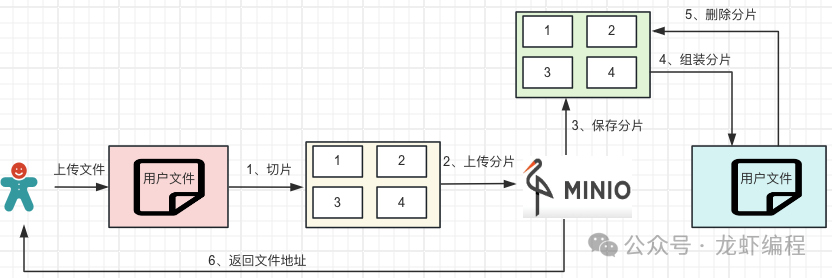
大文件分片上傳需要前后端協(xié)作來完成,前端的工作是切片和生成文件的唯一標(biāo)識;后端的工作是接收文件的唯一標(biāo)識,記錄文件上傳的分片信息和整合分片成完整文件。下面設(shè)計一套前后端協(xié)作方式將大文件分片上傳到MinIO上的方案。
1、生成文件的MD5值
前端需要唯一的標(biāo)識一個文件,然后將唯一的標(biāo)識傳給后端做文件識別,那么用什么來唯一的標(biāo)識一個文件呢?目前比較成熟的方案是將文件的二進(jìn)制數(shù)據(jù)采用MD5映射成一個唯一標(biāo)識。

MD5的一個很大特點(diǎn)是文件內(nèi)容有變動(即使在文件內(nèi)容中加了一個空格)就會生成一個新的唯一標(biāo)識。因此采用MD5的方式給文件生成一個唯一的標(biāo)識。
假設(shè)現(xiàn)在的文件有3G大小,那么計算其MD5值的時候直接將文件的內(nèi)容的讀取到內(nèi)存中然后計算,此時內(nèi)存可能會承受不了,所以采用分片的方式來計算MD5值。
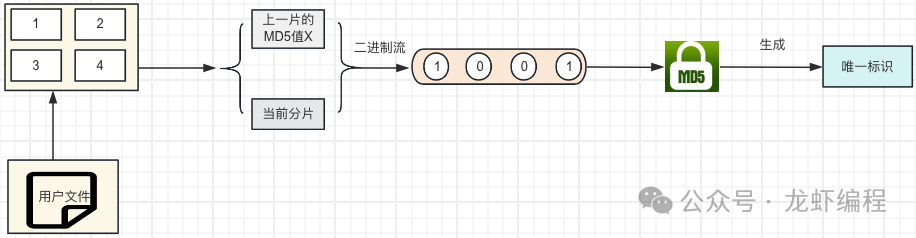
核心代碼:
<template> <div> <input type="file" @change="onFileChange" /> <button @click="uploadFile">上傳</button> </div></template><script> import SparkMD5 from 'spark-md5'; export default { data() { return { selectedFile: null, chunks: [], bytes: [], MD5Value: '', }; }, methods: { onFileChange(e) { this.selectedFile = e.target.files[0]; this.chunks = this.createChunks(this.selectedFile, 100 * 1024); //計算文件的hash this.calculateHash(this.chunks);
}, createChunks(file, chunkSize) { //文件切片 const result = []; for (let i = 0; i < file.size; i += chunkSize) { result.push(file.slice(i, i + chunkSize)) } return result; }, calculateHash(chunks) { //計算MD5值 const spark = new SparkMD5(); function readChunk(i) { if (i >= chunks.length) { this.MD5Value = spark.end(); console.info(this.MD5Value); return; } let blob = chunks[i]; const fileReader = new FileReader(); //異步獲取文件的字節(jié)信息 fileReader.onload = e => { //獲取到讀取的字節(jié)數(shù)組 spark.append(e.target.result); readChunk(i + 1); }; //讀文件的字節(jié) fileReader.readAsArrayBuffer(blob) } readChunk(0); } } };</script>
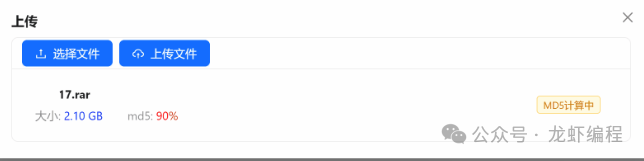
如果文件過大的話,即使采用分片的方式計算文件的MD5值也是非常慢的,所以設(shè)計的時候可以使用一個進(jìn)度條的方式讓用戶知道當(dāng)前正在解析文件并且當(dāng)前的解析進(jìn)度是多少,如下設(shè)計的解析文件的進(jìn)度圖:
2、判斷當(dāng)前的文件上傳信息
前端計算文件的MD5值后可以唯一標(biāo)識這個文件,然后前端將MD5值傳給后端,后端告訴前端當(dāng)前的文件是否上傳過
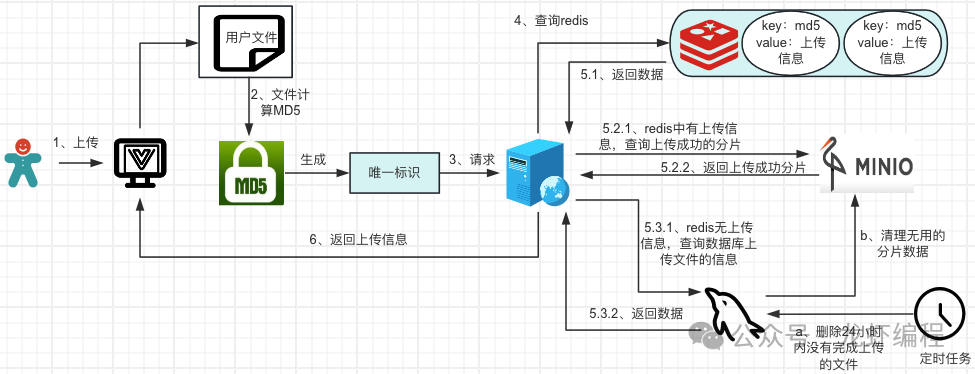
后端拿到MD5的值后到Redis中查詢是否存在上傳的記錄信息:
(1)如果Redis中存在文件上傳的信息,那么需要查詢MinIO上已經(jīng)上傳成功的分片,計算未上傳成功的分片信息,封裝成對象返回給前端。
(2)如果Redis中沒有數(shù)據(jù)的,查詢數(shù)據(jù)庫是否有文件的上傳信息,數(shù)據(jù)庫中要么文件已經(jīng)完成上傳并有文件在MinIO上的地址信息,要么就是沒有上傳(文件首次上傳),結(jié)果封裝成對象返回給前端。
核心代碼:
/** * 檢查當(dāng)前文件的上傳情況 * * @param md5 文件的md5標(biāo)識 */public FileUploadInfo checkFileUploadByMd5(String md5) { //查詢redis是否存在文件的上傳信息 FileUploadInfo fileUploadInfo = RedisUtils.get(md5); //Redis中存在上傳信息 if (Objects.nonNull(fileUploadInfo)) { //獲取已經(jīng)上傳成功的分片信息 List<Integer> listParts = minioUtil.getListParts(fileUploadInfo.getObject(), fileUploadInfo.getUploadId()); fileUploadInfo.setListParts(listParts); return fileUploadInfo; } //查詢數(shù)據(jù)庫是否有上傳記錄 File file = filesMapper.selectUpdaLoadByMd5(md5); if (file != null) { //標(biāo)識文件之前已經(jīng)上傳成功了,直接返回其在MinIO上的地址 FileUploadInfo dbFileInfo = BeanUtils.copyProperties(file, FileUploadInfo.class); return dbFileInfo; } return null; }
3、每個分片生成臨時的憑證

如果當(dāng)前的文件是沒有上傳過或者斷點(diǎn)上傳的時候,需要攜帶md5和分片信息請求后端,后端根據(jù)MD5查詢Redis中上傳文件的信息來申請憑證,如果是斷點(diǎn)續(xù)傳情況,需要過濾已經(jīng)上傳成功的分片再去申請憑證;憑證通過后保存數(shù)據(jù)和更新Redis,然后返回憑證信息、uploadId給前端。
核心的代碼:
//文件分片申請憑證信息 public UploadUrlsVO multipartFileUpload(FileUploadInfo fileUploadInfo) { UploadUrlsVO uploadUrlsVO; String filePath; //查詢Redis是否存在上傳信息 FileUploadInfo redisFileUploadInfo = RedisUtils.get(fileUploadInfo.getMd5()); //redis存在上傳信息 if (Objects.nonNull(redisFileUploadInfo)) { fileUploadInfo = redisFileUploadInfo; filePath = redisFileUploadInfo.getObject(); } else { //redis中無上傳信息 //文件原始名稱 String originName = fileUploadInfo.getOriginFileName(); filePath = DateUtil.format(LocalDateTime.now(), "yyyy/MM/dd") + "/" + FileUtil.mainName(originName) + "_" + fileUploadInfo.getMd5() + "." + FileUtil.extName(originName); fileUploadInfo.setObject(filePath).setType(suffix); } //未分片的文件上傳 if (fileUploadInfo.getChunkCount() == 1) { uploadUrlsVO = minioUtil.uploadSingleFile(fileUploadInfo.getContentType(), filePath); } else { // 分片上傳 uploadUrlsVO = minioUtil.multiPartFileUpload(fileUploadInfo, filePath); } fileUploadInfo.setUploadId(urlsVO.getUploadId()); //最新的分片信息存到redis RedisUtils.set(fileUploadInfo.getMd5(), fileUploadInfo, minioConfigInfo.getBreakpointTime(), TimeUnit.DAYS); return uploadUrlsVO; }
4、前端上傳分片和請求后端合并文件
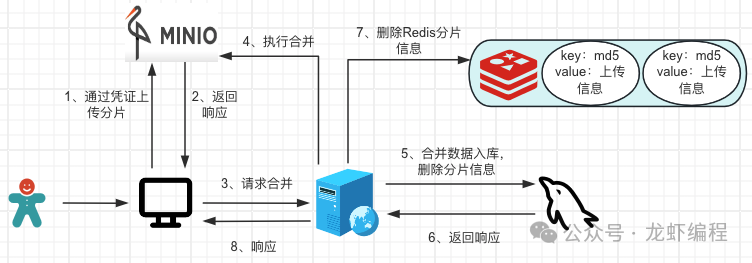
前端通過后端的憑證開始上傳分片信息,分片上傳完成之后請求后端將分片的合并成一個完整的文件,然后獲取到完成的文件地址保存到數(shù)據(jù)庫。
核心代碼:
@Overridepublic String mergeMultipartUpload(String md5) { //獲取Redis中上傳文件的信息 FileUploadInfo redisFileUploadInfo = RedisUtils.get(md5); String fileUrl = StrUtil.format("{}/{}/{}", minioConfigInfo.getEndpoint(), minioConfigInfo.getBucket(), redisFileUploadInfo.getObject()); //組裝數(shù)據(jù)庫實(shí)體 Files file = BeanUtils.copyProperties(redisFileUploadInfo, Files.class); file.setUrl(fileUrl); file.setBucket(minioConfigInfo.getBucket()); //分片為1時不需要合并,否則合并 if (redisFileUploadInfo.getChunkCount() == 1 || minioUtil.mergeMultipartFile(redisFileUploadInfo.getObject(), redisFileUploadInfo.getUploadId())) { filesMapper.insertFile(file); //刪除Redis中分片的信息 redisUtil.del(md5); return fileUrl; } //拋出異常提示 throw new BussinessException(); }
總結(jié):
(1)文件分片上傳需要前端生成文件的唯一標(biāo)識和分片。
(2)后端根據(jù)唯一標(biāo)識判斷是否存在上傳信息,如果存在就判斷是上傳完成還是斷點(diǎn)上傳,如果上傳完整直接返回Minio上文件的地址,如果是斷點(diǎn)上傳就返回哪些分片已經(jīng)上傳成功的信息給前端。
(3)前端過濾上傳成功的分片,將未上傳成功的分片請求后端申請憑證,申請成功之后上傳分片,上傳完成就請求后端合并分片成完成的文件并保存文件的地址到數(shù)據(jù)庫,刪除分片記錄。
(4)秒傳是因?yàn)橹斑@個文件已經(jīng)上傳過,數(shù)據(jù)庫中已經(jīng)存儲了文件在MinIO上完整的地址。
(5)斷點(diǎn)續(xù)傳的原理是記錄已經(jīng)完成上傳的分片,再次上傳的時候這些分片無需再次上傳,只上傳未完成上傳的分片。
該文章在 2024/6/8 22:51:46 編輯過
晴ERP是一款針對中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場、車隊、財務(wù)費(fèi)用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

