【SQLServer】整理10種分布式id生成方案
當(dāng)前位置:點晴教程→知識管理交流
→『 技術(shù)文檔交流 』
在復(fù)雜分布式系統(tǒng)中,如金融、支付、訂單等業(yè)務(wù)數(shù)據(jù)日漸增長而必須要采用對數(shù)據(jù)分庫分表操作,此時就需要有一個唯一ID來標(biāo)識一條數(shù)據(jù)或消息。下面介紹幾種常見的分布式id生成方案。 1、UUID 代碼實現(xiàn)如下所示:
2、數(shù)據(jù)自增主鍵
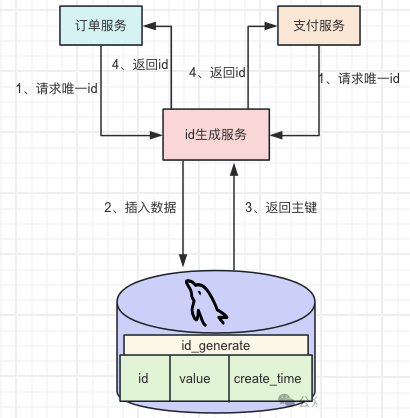
當(dāng)需要唯一的id的時候,向數(shù)據(jù)庫中添加一條數(shù)據(jù)并返回主鍵id,可以保證在當(dāng)前的系統(tǒng)的中id的唯一性。
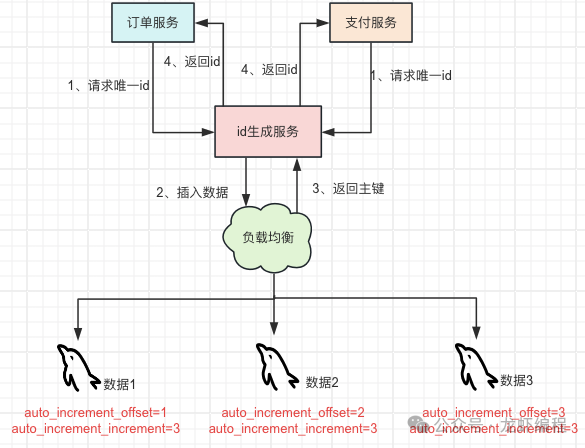
數(shù)據(jù)自增主鍵方案適用于小規(guī)模的、無高并發(fā)場景業(yè)務(wù)場景。 3、數(shù)據(jù)庫集群模式 基于數(shù)據(jù)自增id主鍵方案存在單點問題,那么對其做高可用的優(yōu)化,即就是使用數(shù)據(jù)庫的集群模式來生成唯一id。
通過增加多臺數(shù)據(jù)庫服務(wù)并且給每個數(shù)據(jù)庫都設(shè)置起始值,然后通過設(shè)置步長來讓數(shù)據(jù)生成的ID趨勢遞增且不重復(fù)。
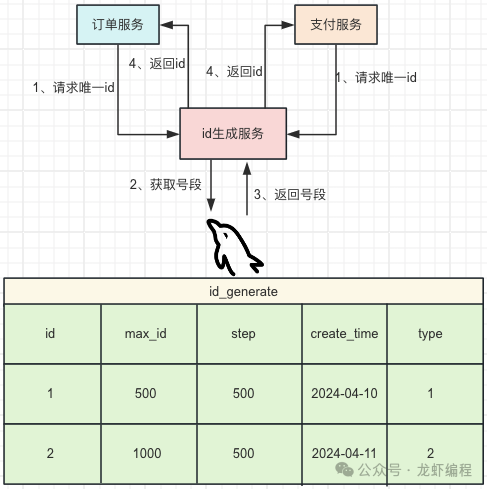
此方案適用于數(shù)據(jù)量不大,數(shù)據(jù)庫不需要擴(kuò)容的場景。 4、數(shù)據(jù)庫號段模式 此方案實質(zhì)就是批量從數(shù)據(jù)庫獲取自增的id,即就是每次從數(shù)據(jù)庫取出一個號段范圍,如(1-3000]表示從數(shù)據(jù)庫中生成3000個自增id。數(shù)據(jù)表的設(shè)計如下:
業(yè)務(wù)申請?zhí)柖蔚牧鞒倘缦拢?/p>
當(dāng)一批號段用完之后,再次向數(shù)據(jù)庫申請新的號段,此方案的的優(yōu)缺點如下表所示:
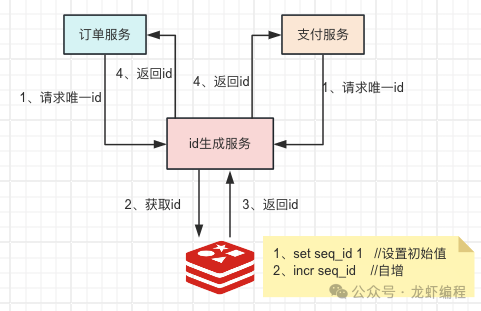
5、Redis實現(xiàn)分布式id
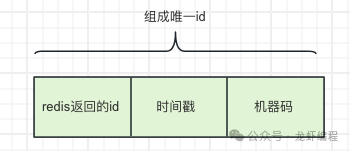
Redis提供的incr自增命令是單線程的操作,可以保證生成的id的唯一并有序的,我們聯(lián)合如時間戳值、機(jī)器標(biāo)識組成一個具有特殊含義的唯一id,如下圖所示:
Redis生成唯一id的優(yōu)缺點如下所示:
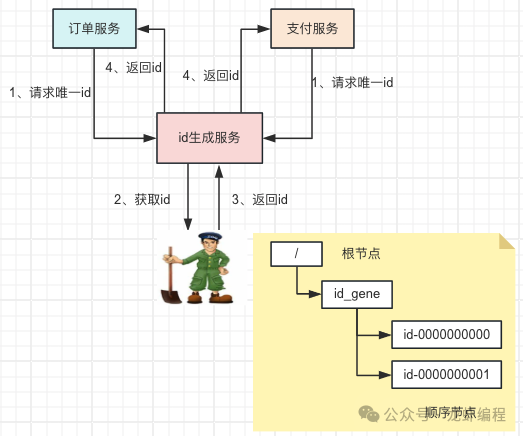
6、Zookeeper實現(xiàn)分布式id Zookeeper客戶端創(chuàng)建順序節(jié)點時會根據(jù)創(chuàng)建的時間順序,在節(jié)點名稱后添加 10 位的順序編號,利用Zookeeper的這個特性實現(xiàn)id的唯一性。
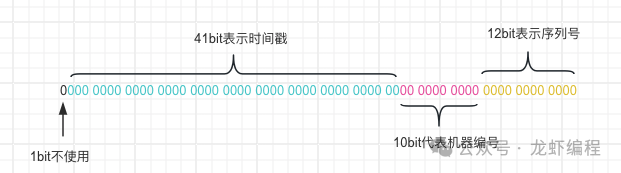
由于依賴Zookeeper并且存在多步的異步調(diào)用,如果競爭較大的的情況下還需要考慮使用分布式鎖,因為很少會使用Zookeeper來生成唯一id。 7、雪花算法 雪花算法是使用一個64bit的long類型數(shù)字作為全局唯一id,下圖是展示了雪花算法生成唯一id時候各個bit位的作用:
假設(shè)當(dāng)前時間是2024-06-10 10:00:00,生成id的機(jī)器編號是7,序列號為1,據(jù)此雪花算法生成的id如下所示:
轉(zhuǎn)為十進(jìn)制如下:
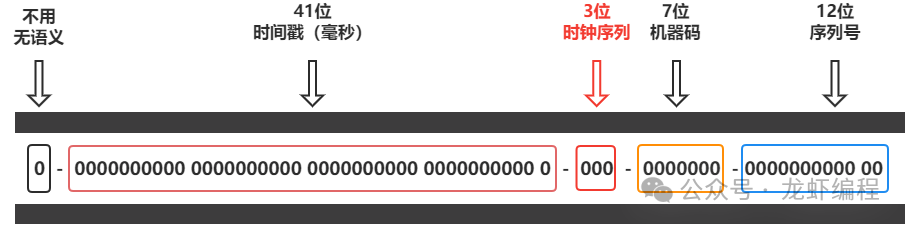
雖然這樣就可以生成一個唯一的id,但是雪花算法有如下的問題: (1)雪花算法嚴(yán)重的依賴時鐘,如果出現(xiàn)時鐘回?fù)芫蜁?dǎo)致重復(fù)生成id;解決時鐘回?fù)艿囊环N方式就是將代表機(jī)器碼的十位拆出三位出來表示時鐘序列,如下圖:
當(dāng)發(fā)生時鐘回?fù)艿臅r候,此時時間已經(jīng)發(fā)生了變化,那么這時將時鐘序列新增1位,重新定義整個雪花Id;為了避免實例重啟引起時間序列丟失,時鐘序列最好通過數(shù)據(jù)庫或者緩存等方式存儲起來。 (2)41bit最大的時間跨度是69年,后面會發(fā)生41比特位不夠使用;解決方案是生成時間戳之后減去系統(tǒng)上線時候的時間。 8、百度uid-generator uid-generator是基于雪花算法實現(xiàn)的,uid-generator不同點在于它支持自定義時間戳、機(jī)器id和序列號等個部分的信息,其組成部分如下所示:
uid-generator的項目地址:
uid-generator具有高性能、去中心化、強(qiáng)一致性和易用性等特點而廣泛的應(yīng)用與生成數(shù)據(jù)庫主鍵、訂單編號和消息追蹤等場合下。 9、美團(tuán)的Leaf 美團(tuán)的Leaf同時兼具了數(shù)據(jù)庫號段模式和雪花算法,它可以試下可以根據(jù)不同業(yè)務(wù)場景靈活切換。 Leaf項目Github地址:
美團(tuán)的Leaf詳細(xì)兩種模式介紹文檔:
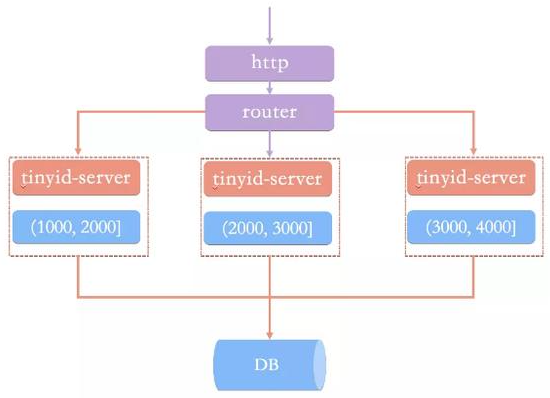
我們根據(jù)實際的業(yè)務(wù)特性來選擇合適的ID生成方式。 10、滴滴的Tinyid Tinyid是在美團(tuán)的ID生成算法Leaf的基礎(chǔ)上擴(kuò)展而來,是基于數(shù)據(jù)庫的號段模式實現(xiàn)的,支持?jǐn)?shù)據(jù)庫多主節(jié)點模式。如下圖如下所示:
項目的地址:
Tinyid提供了REST API和Java客戶端兩種獲取方式,相對來說使用更方便,目前在滴滴客服部門使用,且通過tinyid-client方式接入,每天生成的是億級別的id。性能上還是很高的。 總結(jié): (1)分布式id生成方式有很多種方案,我們需要依據(jù)實際的業(yè)務(wù)場景來選擇合適的方案。 該文章在 2024/7/22 9:00:26 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
")