1.避免使用select *
在實際業務場景中,可能我們真正需要使用的只有其中一兩列。
但我們寫sql語句時,為了方便,喜歡直接使用select *,一次性查出表中所有列的數據。多查出來的數據,通過網絡IO傳輸的過程中,也會增加數據傳輸的時間。
還有一個最重要的問題是:select *不會走覆蓋索引,會出現大量的回表操作,而從導致查詢sql的性能很低。
2.小表驅動大表
小表驅動大表,即用小表的數據集驅動大表的數據集。
假如有order和user兩張表,其中order表有10000條數據,而user表有100條數據。
這時如果想查一下,所有有效的用戶下過的訂單列表。
可以使用in關鍵字實現:
select * from order where user_id in (select id from user where status=1)
sql語句中包含了in關鍵字,則它會優先執行in里面的子查詢語句,然后再執行in外面的語句。如果in里面的數據量很少,作為條件查詢速度更快。
3.避免in中值太多
對于批量查詢接口,我們通常會使用in關鍵字過濾出數據。比如:想通過指定的一些id,批量查詢出用戶信息。
select id,name from category where id in (1,2,3...100000000);
如果我們不做任何限制,該查詢語句一次性可能會查詢出非常多的數據,很容易導致接口超時。
如果ids超過500條記錄,可以分批用多線程去查詢數據。每批只查500條記錄,最后把查詢到的數據匯總到一起返回。
4.高效的分頁
在mysql中分頁一般用的limit關鍵字:
select id,name,age from user limit 10,20;
select id,name,age from user limit 1000000,20;
mysql會查到1000020條數據,然后丟棄前面的1000000條,只查后面的20條數據,這個是非常浪費資源的。
解決方案:先找到上次分頁最大的id,然后利用id上的索引查詢。不過該方案,要求id是連續的,并且有序的。
select id,name,age from user where id > 1000000 limit 20;
5.連接代替子查詢
mysql中如果需要從兩張以上的表中查詢出數據的話,一般有兩種實現方式:子查詢 和 連接查詢。
select * from order where user_id in (select id from user where status=1)
子查詢語句可以通過in關鍵字實現,一個查詢語句的條件落在另一個select語句的查詢結果中。程序先運行在嵌套在最內層的語句,再運行外層的語句。
子查詢語句的優點是簡單,結構化,如果涉及的表數量不多的話。
但缺點是mysql執行子查詢時,需要創建臨時表,查詢完畢后,需要再刪除這些臨時表,有一些額外的性能消耗。
select o.* from order o inner join user u on o.user_id = u.id where u.status=1
6.控制join表的數量
根據阿里巴巴開發者手冊的規定,join表的數量不應該超過3個。如果join太多,mysql在選擇索引的時候會非常復雜,很容易選錯索引。
并且如果沒有命中中,nested loop join 就是分別從兩個表讀一行數據進行兩兩對比,復雜度是 n^2。所以我們應該盡量控制join表的數量。
如果實現業務場景中需要查詢出另外幾張表中的數據,可以在a、b、c表中冗余專門的字段,比如:在表a中冗余d_name字段,保存需要查詢出的數據。
如果兩張表使用left join關聯,mysql會默認用left join關鍵字左邊的表,去驅動它右邊的表。如果左邊的表數據很多時,就會出現性能問題。
7.控制索引的數量
眾所周知,索引能夠顯著的提升查詢sql的性能,但索引數量并非越多越好。因為表中新增數據時,需要同時為它創建索引,而索引是需要額外的存儲空間的,而且還會有一定的性能消耗。
阿里巴巴的開發者手冊中規定,單表的索引數量應該盡量控制在5個以內,并且單個索引中的字段數不超過5個。
mysql使用的B+樹的結構來保存索引的,在insert、update和delete操作時,需要更新B+樹索引。如果索引過多,會消耗很多額外的性能。
8.提升group by的效率
反例:
select user_id,user_name from order
group by user_id
having user_id <= 200;
這種寫法性能不好,它先把所有的訂單根據用戶id分組之后,再去過濾用戶id大于等于200的用戶。
正例:
select user_id,user_name from order
where user_id <= 200
group by user_id
使用where條件在分組前,就把多余的數據過濾掉了,這樣分組時效率就會更高一些。
其實這是一種思路,不僅限于group by的優化。我們的sql語句在做一些耗時的操作之前,應盡可能縮小數據范圍,這樣能提升sql整體的性能。
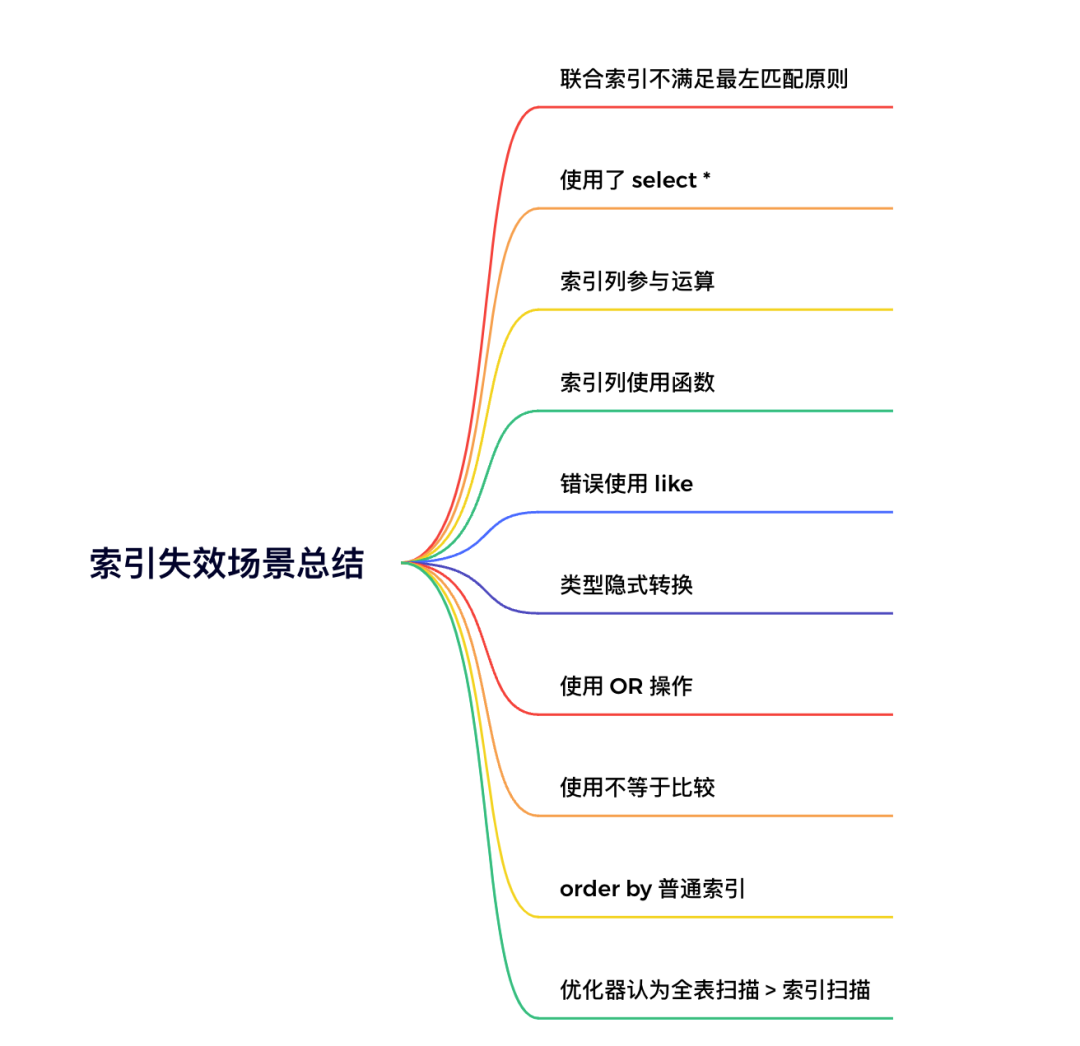
9.索引優化
sql優化當中,有一個非常重要的內容就是:索引優化。很多時候sql語句,走了索引,和沒有走索引,執行效率差別很大。
索引優化的第一步是:檢查sql語句有沒有走索引。可以使用explain命令,查看mysql的執行計劃。進而查看索引是否生效
sql語句沒有走索引,排除沒有建索引之外,最大的可能性就是索引失效。
該文章在 2024/9/10 10:13:09 編輯過






 400 186 1886
400 186 1886


