前端是怎么解析Excel、PDF、Word、PPT等文件的?
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
一、寫在前面作為一名開發者,大家在開發過程中是不是經常遇到各種各樣的文件,比如xlsx、word、ppt等辦公類型的文件格式,還有pdf這種便攜式的打印格式文件等。 但是通常情況下我們都是使用一個相關的第三方庫,比如用 sheet.js 來解析xlsx,mammoth.js 來解析wrod,pptxjs 來解析ppt,如果這些庫你不知道的話,你可以好好研究一下他們的文檔,照著文檔滿足你的業務需求是肯定沒問題的。 但是本文并不嘗試跟大家過一遍這些庫是如何使用的,因為筆者認為做一個API調用工程師意義并不大,本文的目的是跟大家分享這些文件的本質,從而能夠在平常的開發中即便遇到棘手的問題,大家也能夠從容的解決,而不會被第三方庫所綁架。 如果你對以下問題有興趣,那么仔細閱讀本篇文章,你一定會有收獲!
準備好我們開始發車! let`s get start it! 二、辦公文件的本質歷史中國的 蔡倫 在公元105年發明了造紙術,它讓人們進入了一個嶄新的時代。從此紙張如一頭猛獸闖入千家萬戶,人們可以在紙張上記錄、編寫、傳播信息。 技術的突破往往會催生出新的需求,這種在紙張上記錄、編寫、和傳播信息的需要漸漸成為人們生活不可或缺的一部分,歷史、文學、科學、藝術、日常事物都需要依賴于這種技術,因為承載了信息,紙張慢慢被人們稱為文件,無論從哪個角度來看,文件的出現都是人類文明史上濃墨重彩的一筆。 紙張統治了世界將近2000年,或許未來在相當長的時間內它還將一直存在,但是20世紀末,互聯網的出現讓紙質的文件地位出現了動搖,甚至大有退出歷史舞臺的趨勢。人們發現將一切的紙張文件電子化會有令人意想不到的收益。電子文件傳播更迅速、編寫更方便、記錄更便捷。尤其是個人PC和移動終端的出現讓人們隨時隨地可以記錄、編寫、傳播信息。 最早推動這一過程的是王安電腦公司在1971年推出WPS文字處理機-Wang 1200打印機,之后王安WPS成為美國每間辦公室的必備。
后續又有諸多的公司參與這場世紀之戰,這個過程誕生了許許多多的辦公設備,他們有軟件也有硬件,它們的出現加速了這場文件數字化的革命。微軟辦公軟件是這場戰役的勝利者,在全球市場上一直占據主導地位。Microsoft Office套件是業界最受歡迎和廣泛使用的辦公軟件套裝之一。該套件包括諸如Word、Excel、PowerPoint等應用程序,它們在文檔處理、電子表格和演示方面提供了強大的功能。 遺憾的是歷史只記錄勝利者,如果你希望了解更多辦公軟件歷史,可以讀讀這篇文章 標準大家是否思考過一個問題,為什么你創建了一個Word文檔之后,既可以使用微軟在Windows電腦中預裝的Office軟件打開,也可以使用金山軟件的WPS打開。實際上市面上的辦公軟件其實非常的多,比如:Google Workspace (以前稱為 G Suite):、 LibreOffice:、 Apache OpenOffice:、 Apple iWork:、 Zoho Office Suite 。 不知道你是否好奇,為什么對于同一份word文檔,這些不同廠商的軟件無一例外的都可以打開進行閱讀和編輯。 這是為什么呢? 原來他們都遵循同一套標準,這套標準叫做
這套標準定義了各種各樣的組件例如:段落、表格、圖片、布局等如何使用xml語言來進行描述,因此各個辦公軟件廠商只要遵循這套規范就可以解析對應的Word文件,當用戶保存文件時它們也都會遵循這套規范去生成一份Word文件以便用戶使用其他軟件可以正常使用,就這樣大家遵紀守法,其樂融融。
壓縮包如果是經常使用辦公軟件的同學有這樣的體會,當我使用LibreOffice創建一個Word文檔時會生成一個.odt的文件,如下圖所示:
當我使用Microsoft Office創建一個Word文檔時,會生成一個.doc或者.docx的文件。
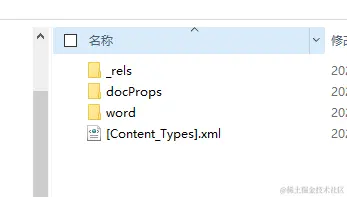
或許其他的軟件還有其他的名字,如果你有興趣可以試一下,不管這個后綴是什么名字,甚至你自己隨便改個后綴,只要它是遵循上面我們提到的標準生成的,它都可以被所有主流的辦公軟件識別和正常使用。 想必計算機專業的同學或許都知道后綴名其實就是一個標識而已,幫助不同的軟件去匹配對應的logo標識而已。而這個文件的本質其實就是個壓縮包。而當你把這個壓縮包解析之后,你就會得到一個文件夾里面全部都是xml和相關的配置文件。 你可以選擇把你的word文檔后綴改成
每個文件夾下面幾乎都是清一色的.xml文件和少數的配置文件。不止word文檔是如此、excel文件、ppt文件都可以按照上面的操作如法炮制,都可以得到一個文件夾,但遺憾的是pdf不是,我們后面再揭曉pdf的本質。
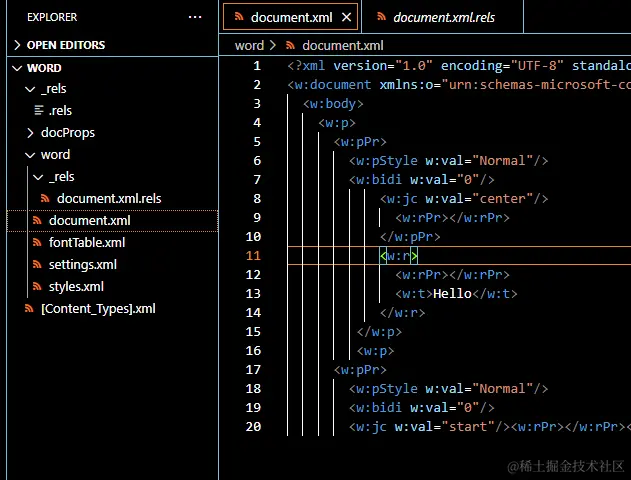
XML如果是計算機專業的同學,對xml或許應該比較熟悉,但是我依然嘴碎一下,照顧下非計同學。 xml本質上就是一個文本文件,只不過文件后綴是 <w:jc w:val="center"/> <w:rPr></w:rPr></w:pPr><w:r> <w:rPr></w:rPr> <w:t>Hello</w:t></w:r>解壓后的word就有類似下面的xml文件
實際上前端同學所熟悉的html就是一種特殊的xml,同屬于標記語言,所以前端同學看到xml會有一種奇怪的熟悉感,更重要的是,在瀏覽器中是可以直接解析xml的,所以在瀏覽器端我們就不用通過字符串的方式自己實現解析的算法。解析的例子如下: <html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>XML 解析示例</title></head><body><h1>XML 解析示例</h1><script>
// 假設有以下 XML 數據
var xmlData = `
<employees>
<employee>
<id>1</id>
<name>John Doe</name>
<position>Developer</position>
</employee>
<employee>
<id>2</id>
<name>Jane Smith</name>
<position>Designer</position>
</employee>
</employees>
`;
// 創建 DOMParser 對象
var parser = new DOMParser();
// 使用 DOMParser 解析 XML 字符串
var xmlDoc = parser.parseFromString(xmlData, "text/xml");
// 獲取 XML 中的元素
var employees = xmlDoc.getElementsByTagName("employee");
// 遍歷元素并輸出內容
for (var i = 0; i < employees.length; i++) {
var id = employees[i].getElementsByTagName("id")[0].textContent;
var name = employees[i].getElementsByTagName("name")[0].textContent;
var position = employees[i].getElementsByTagName("position")[0].textContent;
console.log("Employee ID: " + id);
console.log("Name: " + name);
console.log("Position: " + position);
console.log("--------------------");
}</script></body></html> 可以看到只要給前端一份xml文件我們就可以通過DOM相關的API拿到任何我們想要的東西。 解析那么為什么前端可以解析excel、word、ppt等文件呢? 原因其實很簡單,因為解析需要滿足的條件前端都具備。首先瀏覽器可以讀取磁盤的文件,如果想要了解瀏覽器如何讀取磁盤的細節,我之前寫過這篇文章歡迎你的閱讀。 此外瀏覽器其實原生也提供了如何解壓和壓縮文件的API,但是瀏覽器提供的這個API可能使用上并不是非常的友好,需要對流有一定的理解才能得心應手。因此我推薦大家使用JSZip,它可以很方便的壓縮和解壓縮一個文件,并且在瀏覽器和Nodejs這兩個運行時中都支持。接下來我們來看一下它的使用方法,以下是一個壓縮和解壓縮的還原字符串的案例。 <html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>JSZip Demo</title>
<script src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.1.5/jszip.min.js"></script>
</head>
<body>
<script>
// 壓縮字符串
function compressString(originalString) {
return new Promise((resolve, reject) => {
const zip = new JSZip();
zip.file("compressed.txt", originalString);
zip
.generateAsync({ type: "blob" })
.then((compressedBlob) => {
const reader = new FileReader();
reader.onload = () => resolve(reader.result);
reader.readAsText(compressedBlob);
})
.catch(reject);
});
}
// 解壓縮字符串
function decompressString(compressedString) {
return new Promise((resolve, reject) => {
const zip = new JSZip();
zip
.loadAsync(compressedString)
.then((zipFile) => {
const compressedData = zipFile.file("compressed.txt");
// debugger;
if (compressedData) {
return compressedData.async("string");
} else {
reject(
new Error("Unable to find compressed data in the zip file.")
);
}
})
.then(resolve)
.catch(reject);
});
}
// 示例
const originalText =
"Hello, this is a sample text for compression and decompression with JSZip.";
console.log("Original Text:", originalText);
// 壓縮字符串
compressString(originalText)
.then((compressedData) => {
console.log("Compressed Data:", compressedData);
// 解壓字符串
decompressString(compressedData)
.then((decompressedText) => {
console.log("Decompressed Text:", decompressedText);
})
.catch((error) => {
console.error("Error during decompression:", error);
});
})
.catch((error) => {
console.error("Error during compression:", error);
});
</script>
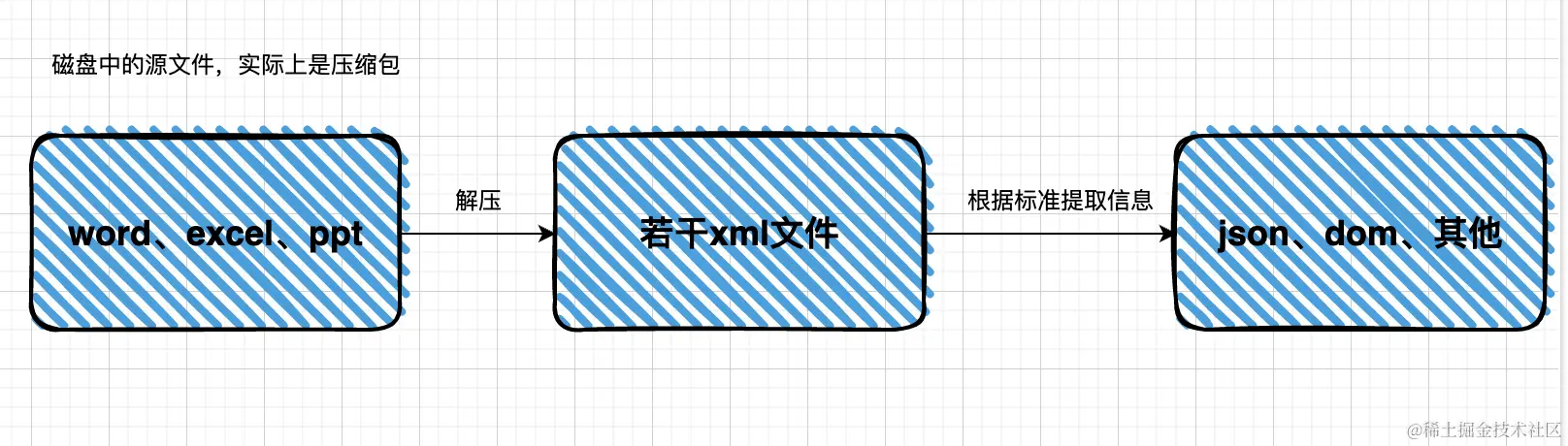
</body></html> 當我們的辦公文件(excel、word、ppt)解壓縮之后就變成一堆xml文件了,然后在瀏覽器端可以通過前面小節提到的解析過程進行解析,可以把數據提取出來生成json,也可以創建為DOM,這個就由開發者自己選擇了。 因此主流的第三方庫解析路徑如下圖所示:
當然這個解析過程其實并不難,關鍵在于這些第三方庫將依據
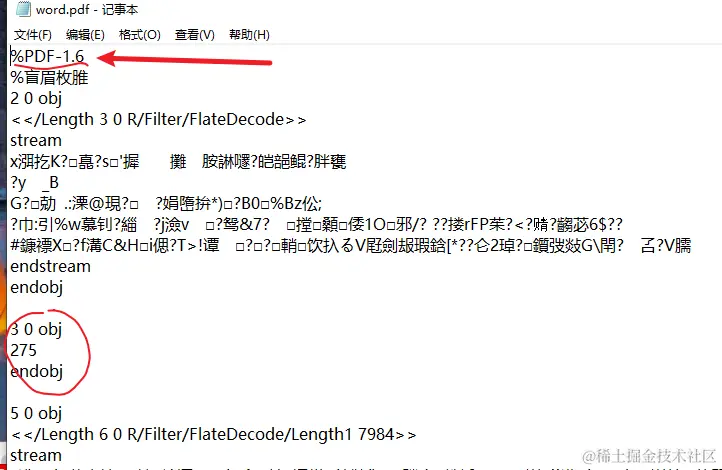
三、PDF前面的文章都是提到的辦公文件,也就是excel、word、ppt這些文件,但我們一字未提PDF。 那么PDF和這些文件有何不同呢?我們先從它為什么被大家使用談起,大家可能有這樣的體會,當你使用word文檔軟件寫好了一篇論文之后,就會拿到打印店去打印,結果用打印店的軟件一打開,發現辛辛苦苦排版好的內容全都亂了,雖然也沒有特別丑,但是和你之前排版的完全不一樣。 這個時候你的好室友就會建議你先將這份word文檔轉換為PDF格式,然后再去打印,結果會發現PDF無論在哪里打開,它幾乎都是一模一樣的,排版和導出時候的樣子都是一樣的。 本質PDF對應的就是電子世界的打印紙張,它擁有不可編輯、占用空間小、穩定性強、可加密等特點,它由Adobe于1993年首次提出,旨在實現跨平臺和可靠性的文檔顯示。PDF文件可以包含文本、圖形、圖像和其他多媒體元素,并以一種獨立于操作系統和硬件的方式呈現。 我們前面說到辦公軟件的本質其實是壓縮包,那么PDF是壓縮包么? 雖然PDF存儲空間小,感覺很像個壓縮包,但其實還真不是,PDF的文件可以直接使用文本編輯器強行打開,打開之后可以看到一些似乎有意義的數據。
可以看到第一行有一個PDF-1.6,它其實表明了應該使用pdf1.6版本的規范去解析這份文檔,下面還有一些數字信息描述的其實是坐標相關的信息。 你也可以新建一個文本,把下面這段字符串粘貼其中,把后綴名改成**.pdf**,就會驚奇的發現你居然手寫了一個PDF出來。 %PDF-1.1
%¥±?
1 0 obj
<< /Type /Catalog
/Pages 2 0 R
>>
endobj
2 0 obj
<< /Type /Pages
/Kids [3 0 R]
/Count 1
/MediaBox [0 0 300 144]
>>
endobj
3 0 obj
<< /Type /Page
/Parent 2 0 R
/Resources
<< /Font
<< /F1
<< /Type /Font
/Subtype /Type1
/BaseFont /Times-Roman
>>
>>
>>
/Contents 4 0 R
>>
endobj
4 0 obj
<< /Length 55 >>
stream
BT
/F1 18 Tf
0 0 Td
(Hello World) Tj
ET
endstream
endobj
xref
0 5
0000000000 65535 f
0000000018 00000 n
0000000077 00000 n
0000000178 00000 n
0000000457 00000 n
trailer
<< /Root 1 0 R
/Size 5
>>
startxref
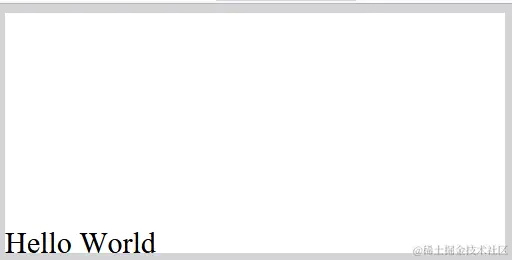
565
%%EOF 打開預覽如圖所示:
如果把PDF的語言翻譯成人話大概是下面這個樣子。 【文字開始】
縮放比例1倍 坐標(1036,572) 【文字定位】
/TT1 12磅 【選擇字體】
[ (He) 間距24 (l) 間距-48 (l) 間距-48 (o) ] 【繪制文字】
【文字結束】
【文字開始】
縮放比例1倍 坐標(1147,572) 【文字定位】
/TT1 12磅 【選擇字體】
(空格) 【繪制文字】
【文字結束】
【文字開始】
縮放比例1倍 坐標(1060,572) 【文字定位】
/TT1 12磅 【選擇字體】
[ (w) 間距24 (or) 間距-84 (l) 間距-24 (d) ] 【繪制文字】
【文字結束】 可以看到,PDF有一套自己的語法規則,這套規則描述了一張固定大小的紙張上哪個文字應該放在哪個位置,這個信息是絕對的。如果對比上面的word文檔,他們描述信息的方式采用的是xml,xml只是存儲了信息,但是這些信息的具體排布方式是由各自的軟件決定的,我們舉個簡單的例子方便大家理解。 假設有一個段落存儲了 在word里xml的描述很可能是這樣的 這段信息在微軟里面可能占1行,在WPS中很可能占2行,因為這個xml并沒有描述應該占幾行這樣的信息,所以留給各家軟件在排版上的自由度還是比較高的。 但是在pdf中,可能就有以下的描述: 【文字開始】
顏色#000 坐標(0,0)
字號14【大家好,我是一串文字】
【文字結束】
翻譯以下就是:引擎你在畫板0,0位置給我畫個"大",在0,1位置給我畫個"家"... PDF中是描述了文字的布局信息,相當于一個指針告訴解析器應該在哪個位置畫一個怎樣的符號。 這樣絕對的信息讓得到這份文件的人可以在一個指定大小的空間每次都畫出一模一樣的內容來,因此是絕對穩定的。 如果需要實現一個PDF解析器,則需要對PDF使用的這套規則語法有深入的了解,因為這套規則就是一門語言,并且是圖靈完備的,所以要實現能夠解析它的引擎,并不比實現一個V8簡單多少,幸好幾乎現代瀏覽器都支持解析PDF。并且提供了強大的功能。 我們可以選擇使用embed標簽或者iframe標簽來解析PDF。 <embed src="example.pdf" width="800px" height="600px" type="application/pdf"> <!-- 或 --> <iframe src="example.pdf" width="800px" height="600px"></iframe> 或者如果希望將PDF完全由DOM來渲染,則可以使用mozilla開源的pdf.js。
參考資料www.ruanyifeng.com/blog/2007/1… 維護維護于2023.12.19,有小伙伴建議把延伸閱讀的文章總結一下,這就給各位整理一下: IT歷史連載30-office辦公軟件的歷史 轉自https://juejin.cn/post/7313048171797544997 該文章在 2024/11/2 10:31:38 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886