研發強烈反對用自增id,堅持用uuid做主鍵,該怎么辦?
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
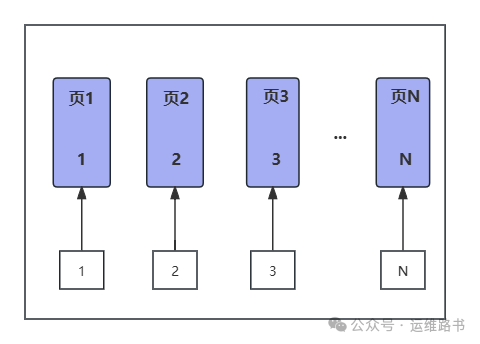
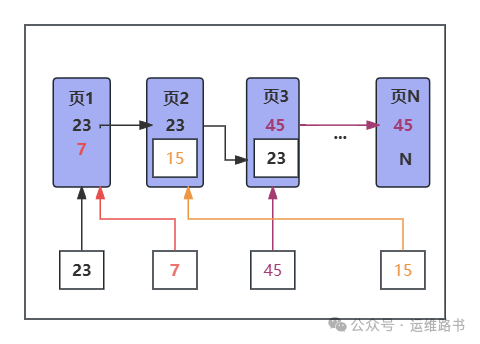
最近,公司剛剛開了一個新項目,研發丟過來的建表語句,一看全都是uuid做主鍵。。。 頭大,想要研發改成自增id,結果研發來一句,自增id不利于數據安全。 對于一個對數據安全要求高的公司來說,這一句秒殺了。 但是,此題還得解。 本期就說說自增id和uuid的優劣,以及最后的解決方案。 核心要點 1. 為什么用自增ID 2. 自增ID的優缺點 3. UUID的優缺點 4. 解決方案 5. 總結 為什么用自增ID 為什么DBA總是強調要用自增id做主鍵? 這也是研發同學一直以來的疑問,一般DBA會說基于性能考慮。具體為什么,可能也沒詳細解釋過。今天,簡單明了地解釋一下。 MySQL數據如何存儲: clustered index The In the Oracle Database product, this type of table is known as an index-organized table. 首先, 官方手冊中關于聚集索引有詳細的說明 InnoDB表存儲基于主鍵列的值進行組織 這類表又稱之為索引組織表 總結一句話就是:MySQL的innodb表的數據是按照主鍵的順序進行存儲的。 其次, MySQL數據庫在磁盤上按數據頁進行存儲的,每個數據頁的默認大小為16k 有序主鍵和無序主鍵的區別: 1. 有序主鍵(例如自增ID)存儲性能:
查詢性能:
2. 無序主鍵(例如UUID)存儲性能:
查詢性能:
自增ID的優缺點 優點:
缺點:
UUID的優缺點 優點: 全局唯一性:UUID能夠在分布式系統中保證唯一性,而無需依賴中心化的ID生成服務。 支持分布式環境:在分布式架構中,UUID特別適合用于跨數據庫實例的記錄合并,不會引起主鍵沖突。 數據遷移靈活性:數據遷移、跨系統整合等操作更簡單,不需要重新生成主鍵或做ID映射。 避免信息泄露:UUID的隨機性避免了可能會暴露插入的順序或數量這一風險,增強了數據的安全性。 插入性能低:UUID是無序的隨機字符串,在B+樹等結構中不能按順序插入,導致頻繁的頁分裂,增加了數據庫索引的維護開銷,影響插入性能。 占用存儲空間大:UUID通常為128位的字符串,存儲時比自增整數(4字節或8字節)更占用空間。 查詢性能差:因為UUID是無序的,基于UUID的范圍查詢性能低。UUID在數據頁中分布分散,導致更多的磁盤隨機讀取,而不是連續讀取,增加了IO負擔。 排序和對比成本高:UUID長度較長,進行排序和比較的成本也較高,尤其在需要頻繁排序的場景中,性能開銷更大。 閱讀性差:UUID是隨機生成的長字符串,可讀性差,不易辨識和調試,增加了手動操作或日志分析的難度。 解決方案 了解了兩種方案的優缺點,接下來就是要取舍了,如何平衡各方?
最后決定采用 UUID v7 UUIDv7特點:
以目前公司新項目為例,之前采用java的hutool工具生成uuid,同樣支持uuidv7。只需要更換一個調用方法即可,代碼修改量極小。 總結
該文章在 2024/11/4 10:34:50 編輯過 |
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886