隨著所有主流瀏覽器現(xiàn)已支持 getHTML() 方法,前端開(kāi)發(fā)者有了一個(gè)強(qiáng)大的新工具來(lái)操作DOM。本文主要探討 getHTML()的獨(dú)特優(yōu)勢(shì),特別是在處理Shadow DOM時(shí)的卓越表現(xiàn)。
getHTML()與innerHTML的異同
getHTML()和 innerHTML 的 getter 在基本功能上相似,都返回元素內(nèi)部DOM樹(shù)的HTML表示。但getHTML()的真正優(yōu)勢(shì)在于它能夠包含Shadow DOM的HTML,而innerHTML則完全忽略Shadow DOM。
getHTML()的高級(jí)用法
getHTML()接受一個(gè)可選的options對(duì)象參數(shù),通過(guò)適當(dāng)?shù)倪x項(xiàng)可以獲取完整的HTML,包括Shadow DOM:
const container = document.body;
const host = createDiv(123);
const root = attachShadowDOM(host);
container.append(host);
console.log(container.getHTML({ shadowRoots: [root] }));
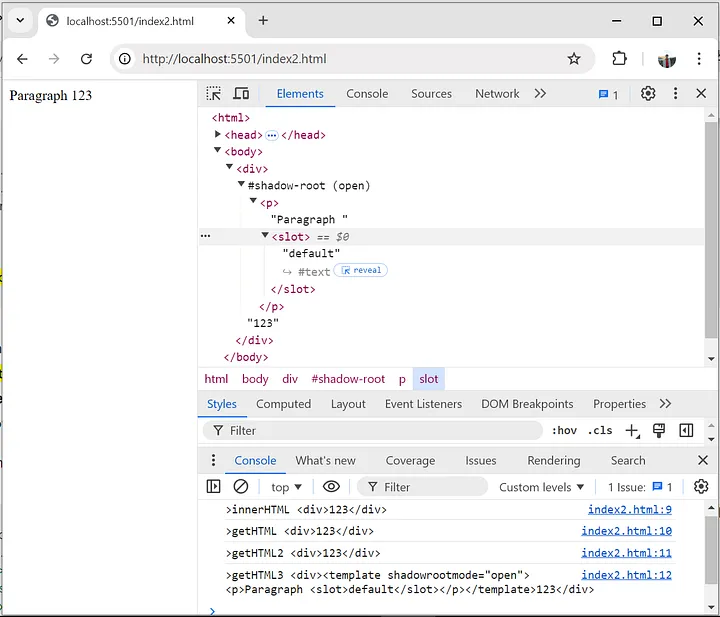 ?
?
這段代碼會(huì)返回包含聲明式Shadow Root的完整HTML:
<div>
<template shadowrootmode="open">
<p>Paragraph <slot>default</slot></p>
</template>
123
</div>
如果在瀏覽器中將返回的 上面的 HTML 作為新頁(yè)面打開(kāi),則會(huì)再現(xiàn)原始 DOM 樹(shù):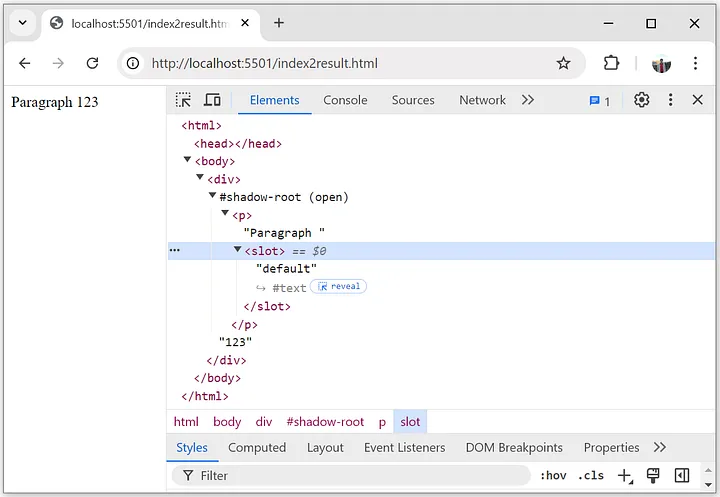
通常,shadow trees和slots是在自定義元素的構(gòu)造函數(shù)中創(chuàng)建的,但為了保持上面和下面示例頁(yè)面中的代碼簡(jiǎn)單,這里沒(méi)有創(chuàng)建任何自定義元素。相反,使用了兩個(gè)輔助函數(shù):
// shared.js
export function attach(host) {
const shadowRoot = host.attachShadow({ mode: 'open' });
shadowRoot.innerHTML = '<p>Paragraph <slot>default</slot></p>';
return shadowRoot;
}
export function div(n) {
const el = document.createElement('div');
if (n) el.innerHTML = n;
return el;
}
div(n)創(chuàng)建一個(gè)新的div元素,里面包含數(shù)字n,例如<div>123</div>,而attach(host)將HTML為<p>Paragraph <slot>default</slot></p>的shadow樹(shù)附加到host元素上。為了用常見(jiàn)情況挑戰(zhàn)getHTML(),div中的數(shù)字123被分配到shadow DOM的slot中。
處理嵌套的Shadow DOM
在上面的頁(yè)面中,getHTML()被調(diào)用時(shí)使用了所有兩個(gè)可能的選項(xiàng):
<script type="module">
import { attach, div } from './shared.js';
const container=document.body;
const host=div(123);
const root=attach(host);
container.append(host);
console.log('>innerHTML',container.innerHTML);
console.log('>getHTML',container.getHTML());
console.log('>getHTML2',container.getHTML({ serializableShadowRoots: true }));
console.log('>getHTML3',container.getHTML({ shadowRoots: [root] }));
</script>
options對(duì)象可以有兩個(gè)屬性:serializableShadowRoots和shadowRoots。 當(dāng)getHTML()在沒(méi)有options的情況下被調(diào)用時(shí),Shadow DOM會(huì)被忽略,就像在innerHTML中一樣。
如果serializableShadowRoots為true,HTML將包括具有serializable屬性設(shè)置為true的shadow roots。這樣的roots通常不應(yīng)該存在,因?yàn)閟erializable是與getHTML()一起引入的,默認(rèn)情況下它是false。
要獲取shadow roots的HTML,需要在shadowRoots屬性中提供要序列化的shadow roots。當(dāng)shadow roots是open的時(shí)候,可以很容易地遞歸檢索網(wǎng)頁(yè)中的所有shadow roots。在網(wǎng)頁(yè)上下文中無(wú)法檢索closed shadow roots,但可以在瀏覽器擴(kuò)展注入的內(nèi)容腳本中檢索。
提供的shadow roots不一定會(huì)被序列化。在下一個(gè)示例頁(yè)面中,創(chuàng)建了兩個(gè)shadow trees。第二個(gè)shadow DOM嵌套在第一個(gè)中:
<script type="module">
import { attach, div } from './shared.js';
const container=document.body;
const host=div(123);
const root=attach(host);
container.append(host);
const host2=div(456);
const root2=attach(host2);
container.append(host);
root.append(host2);
console.log('>innerHTML',container.innerHTML);
console.log('>getHTML',container.getHTML());
console.log('>getHTML2',container.getHTML({ serializableShadowRoots: true }));
console.log('>getHTML3',container.getHTML({ shadowRoots: [root] }));
console.log('>getHTML4',container.getHTML({ shadowRoots: [root2] }));
console.log('>getHTML5',container.getHTML({ shadowRoots: [root,root2] }));
</script>
如果第一個(gè)shadow DOM不包含在options中,getHTML()不會(huì)返回第二個(gè)shadow DOM的HTML: 要被序列化,shadow roots需要直接連接到要被序列化的DOM。如果省略了父shadow root,嵌套的shadow root也不會(huì)被序列化。
getHTML 局限性
缺少outerHTML等價(jià)物:目前還沒(méi)有獲取包含元素自身在內(nèi)的HTML的方法。
單根元素限制:getHTML()返回的HTML如果沒(méi)有單一根元素,瀏覽器可能無(wú)法正確解析為聲明式Shadow DOM。
封閉的Shadow DOM:在網(wǎng)頁(yè)上下文中無(wú)法獲取封閉的Shadow DOM,但可以通過(guò)瀏覽器擴(kuò)展的內(nèi)容腳本來(lái)實(shí)現(xiàn)。
結(jié)語(yǔ)
getHTML()為開(kāi)發(fā)者提供了一種強(qiáng)大的方法來(lái)處理包含Shadow DOM的復(fù)雜DOM結(jié)構(gòu)。雖然它有一些限制,但在處理現(xiàn)代Web組件和復(fù)雜UI時(shí),getHTML()的優(yōu)勢(shì)是顯而易見(jiàn)的。隨著Web組件的普及,掌握getHTML()將成為前端開(kāi)發(fā)者的重要技能。
在實(shí)際開(kāi)發(fā)中,getHTML()可以用于創(chuàng)建更精確的DOM快照、調(diào)試復(fù)雜的組件結(jié)構(gòu),以及在需要保留Shadow DOM結(jié)構(gòu)的情況下序列化頁(yè)面內(nèi)容。隨著Web標(biāo)準(zhǔn)的不斷發(fā)展,我們可以期待看到更多類似getHTML()這樣的強(qiáng)大API,進(jìn)一步增強(qiáng)前端開(kāi)發(fā)的能力和靈活性。
該文章在 2024/11/11 14:40:15 編輯過(guò)
晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車(chē)隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

