前言
最近開發過程中遇到了關于使用base64加密傳輸遇到的神奇問題。需求就是用戶的id在鏈接上露出時需要加密處理,于是后端把下發的用戶id改成了base64加密處理后下發了,前端只需要把加密后的用戶id原樣傳給后端就行。就是這個看似簡單的流程,前端啥也沒干只是原樣透傳,但后端有概率拿到的用戶id不對。
問題描述
本地寫個后端服務模擬當時的情景:
后端框架:nest
@Get('getUserInfo')
getUserInfo(@Req() req) {
const query = req.query
const cookie = req.cookies
console.log('cookie', cookie)
const userId = query.userId || cookie.uid
const token = Buffer.from(userId).toString('base64')
console.log('加密后的token', token)
return {
code: 0,
data: {
userId,
token
}
}
}
前端請求后:
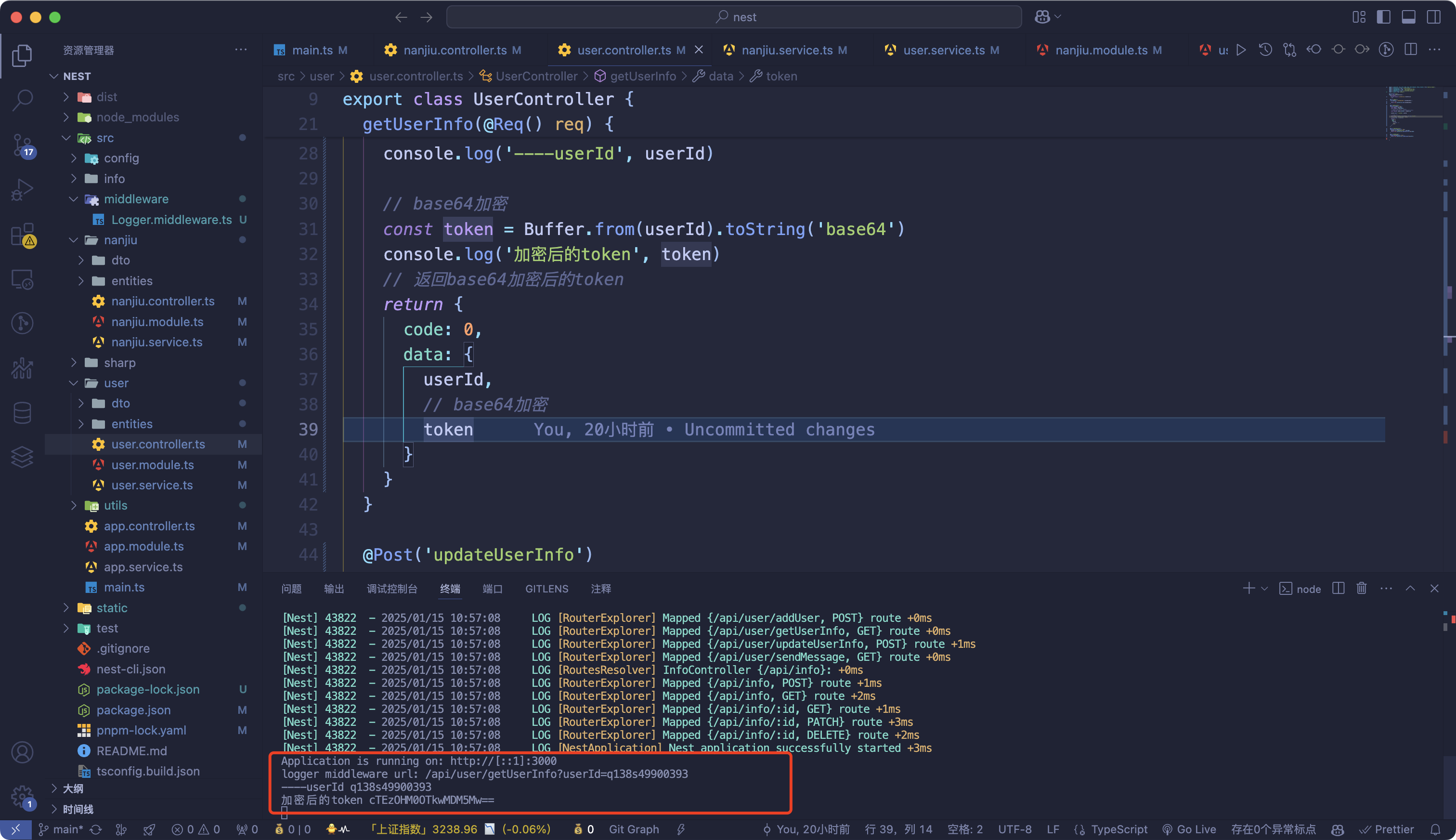
服務這邊能夠正常拿到cookie并使用base64加密,然后把加密后的token返回給前端
前端也正常拿到了后端返回的加密后的token
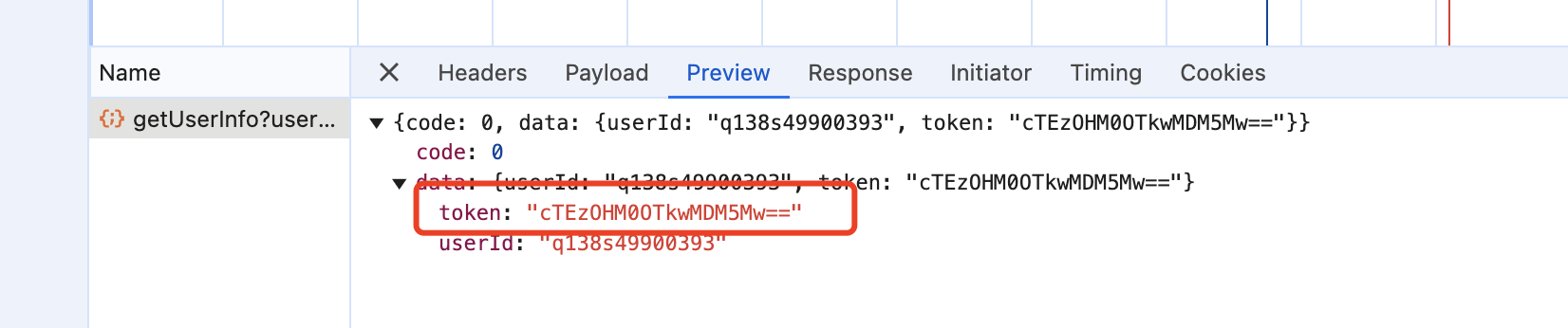
最后前端只需要在用戶分享時把加密的token帶在鏈接上,從這個鏈接進入時再把鏈接上加密的token帶給后端即可,中間不需要做任何處理。
就是這個過程,出現了奇怪的現象,絕大多數用戶都是OK,但是會有一些用戶的token帶給后端時,后端解不出來了。
心想這跟前端好像沒啥關系,因為前端壓根沒處理后端返回的token,后端給我啥,我只是原樣給他傳了啥。
經排查發現,所有有問題的用戶id都是加密后的token中包含了+符號
比如這樣的:zm+3DQ/gYeMzQ/HM2L76+CA==傳到后端時,所有的+都變成了空格,導致后端解出來是錯的
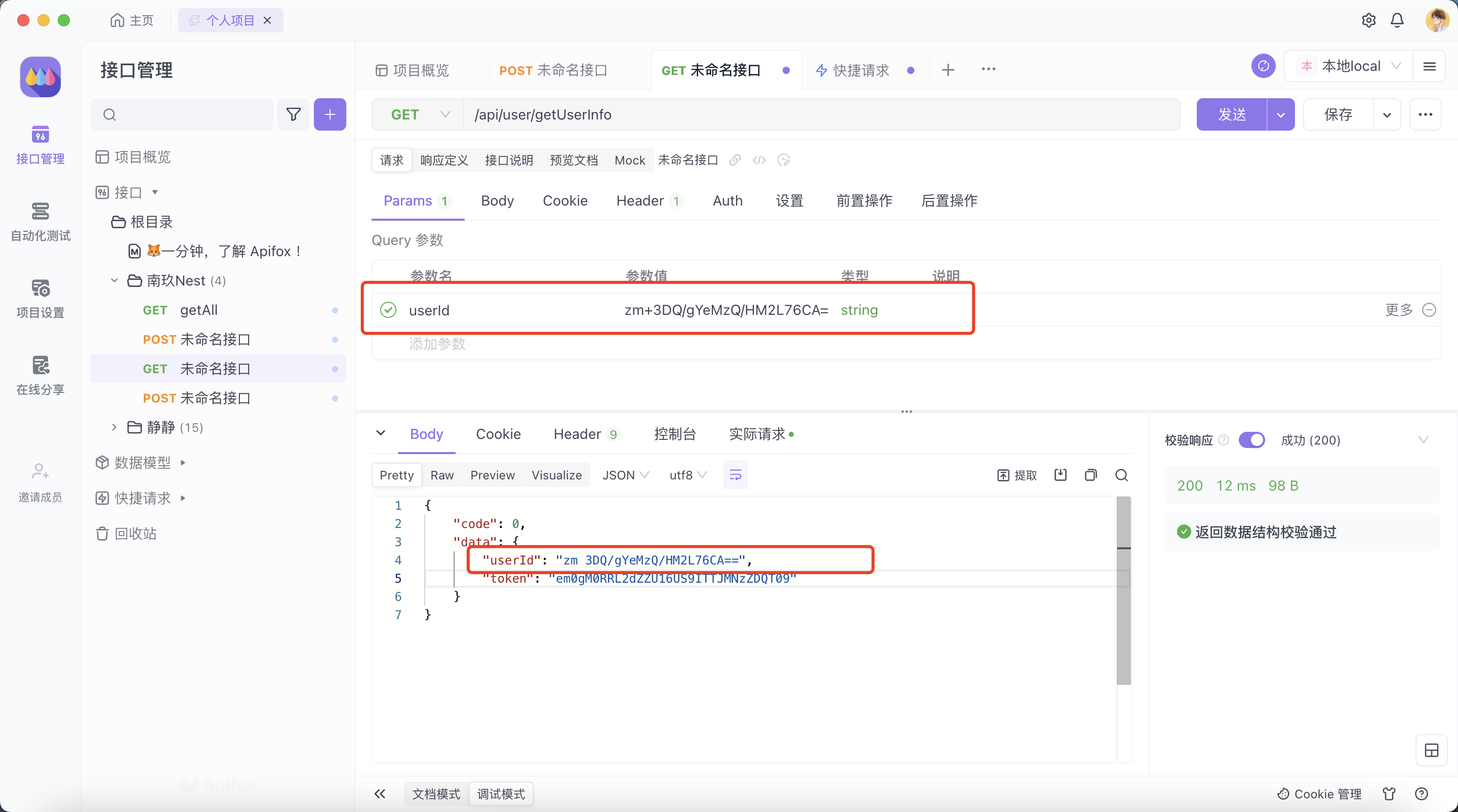
URL是如何進行編碼的
這個問題的主要原因還是因為URL被編碼造成的,由于請求是get請求,所以最終所有的參數都是拼接在鏈接上的,最開始前端傳給后端的token是沒有經過編碼的,那它為什么自己編碼了?并且編碼后與預期的還不一致?
由于種種歷史原因,RFC與W3C都定義過URL的編碼標準
RFC規范
在RFC3986中提到:除了 數字 、 字母 、-_.~ 不會被轉義,其他字符都會被以百分號(%)后跟兩位十六進制數 %{hex} 的方式進行轉義。在這個規則中空格會被轉為%20,而+會被轉為%2B

W3C規范
在W3C規范中卻又說空格可以被編碼為+或%20

為什么會同時存在兩種規范,這不是在挖坑嗎?
因為URL中不能存在空格,所以在URL中的空格會自動替換成+或%20
這就是上面出現+變空格的原因,在你不確定正在以哪一個規范進行編解碼時,就很容易出現這個問題。它可能是瀏覽器造成的,也可能是開發語言的規范不同造成的。
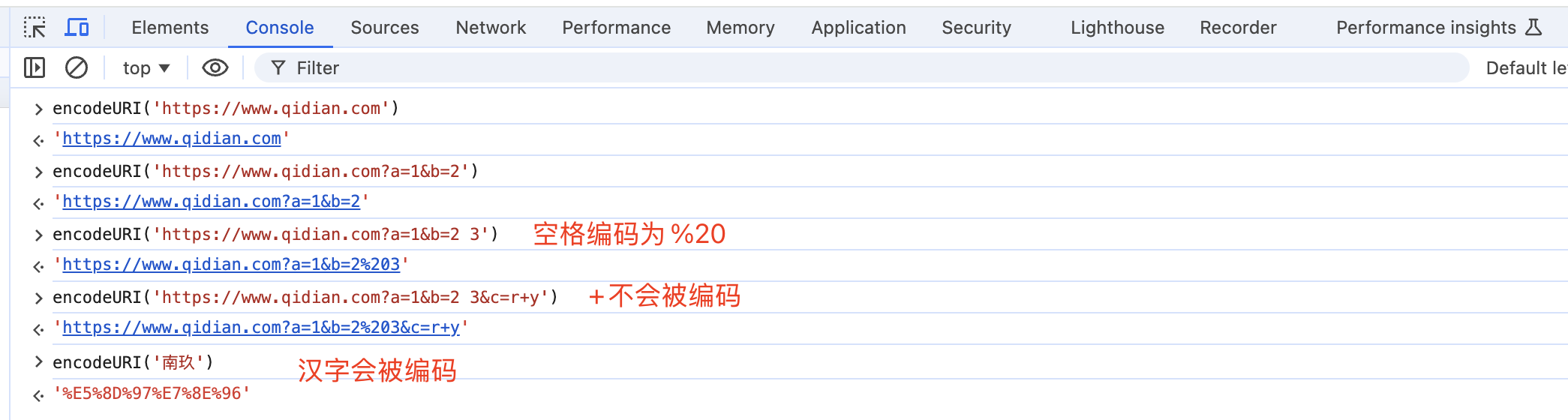
比如Google搜索:
當我們搜索s+2時,地址欄出現的是s%2B2

當我們搜索s 2時,地址欄出現的卻是s+2

這里就是空格被編碼為+了,你要是不了解W3C這條規范,是不是覺得匪夷所思了??
前端編碼規范
在JS中對字符串進行編碼的方法有三個:escape、encodeURI、encodeURIComponent
escape已經被廢棄了,不再推薦使用,所以我們這里只需要關注后面兩個的區別
encodeURI
該函數只會編碼URI中完全禁止的字符。該函數的目的是對URI進行完整的編碼,因此對以下在URI中具有特殊含義的 ASCII 標點符號,encodeURI是不會進行轉義的(;/???&=+$,#)
所以對于encodeURI來說,空格會被編碼為%20,但是+并不會編碼。因為空格是URI中禁止的字符,而+不是
總結來說就是:
encodeURL除了這些A-Z a-z 0-9 ; , / ? : @ & = + $ – _ . ! ~ * ‘ ( ) # 不會被編碼,其余字符都會被編碼
encodeURIComponent
功能與encodeURI類似,但是encodeURIComponent編碼的范圍更廣,并且該函數一般用于對URI的參數部分進行編碼
對于encodeURIComponent來說,空格會被編碼為%20,+會被編碼為%2B

總結來說就是:
encodeURLComponent除了這些A-Z a-z 0-9 - _ . ! ~ * ' ( ) 不會被編碼,其余字符都會被編碼
兩者使用場景的差異
- 當encode的內容不作為URI參數時,使用
encodeURI進行編碼
const url = encodeURI('https://www.qidian.com')
- 當encode的內容作為URI參數時,使用
encodeURIComponent進行編碼
const deepLink = `weixin://webview?url=${encodeURIComponent('https://www.baidu.com')}`
結論
對于JS的編碼方法來說,只有encodeURIComponent會對+進行編碼,并且編碼規范是RFC3986,也就是說使用這個方法空格會被轉為%20,而+會被轉為%2B。從而也就不會出現+變空格或空格變+的問題。
上述問題是如何產生的?
上面分別介紹了URL的編碼規范,以及前端編碼方法應用的規范。總結下來就是空格不會在前端產生,前端應用的編碼規范不會將空格編碼成+,也不會把+解碼成空格。
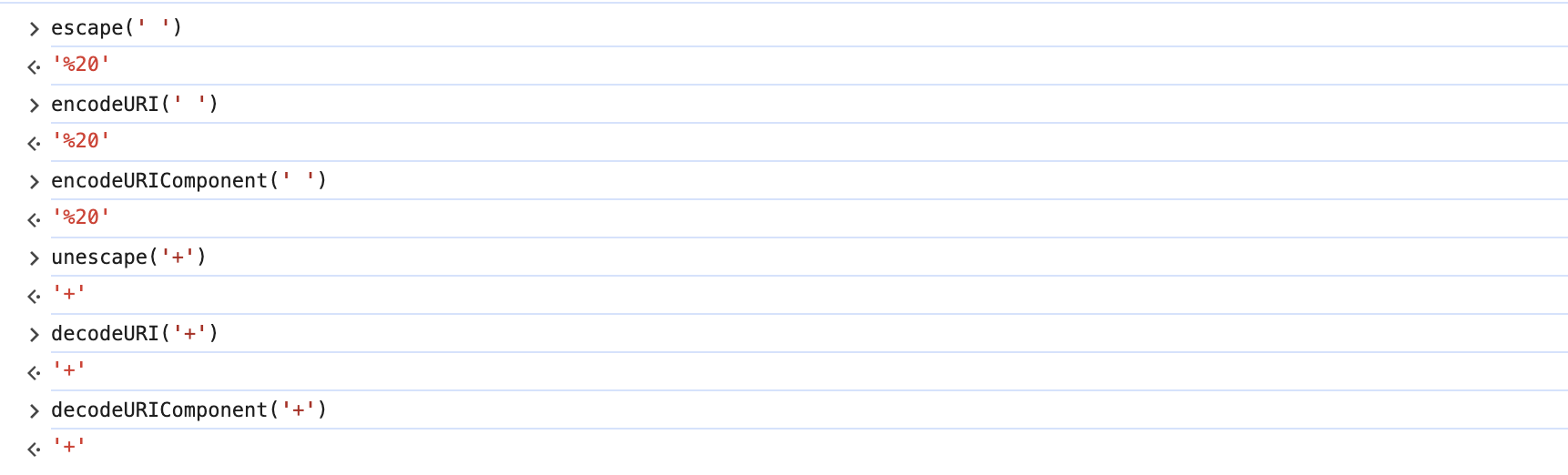
并且特意寫了個node服務來模擬當時的場景。
結論是:只要傳給后端的base64字符串在前端經過了編碼就不會有問題。因為上面我們介紹過瀏覽器的編碼規范,確實是會存在+變空格的問題。所以我們需要主動編碼,不要把編碼的機會留給瀏覽器。
- 前端編碼了,后端拿到的也是正常的
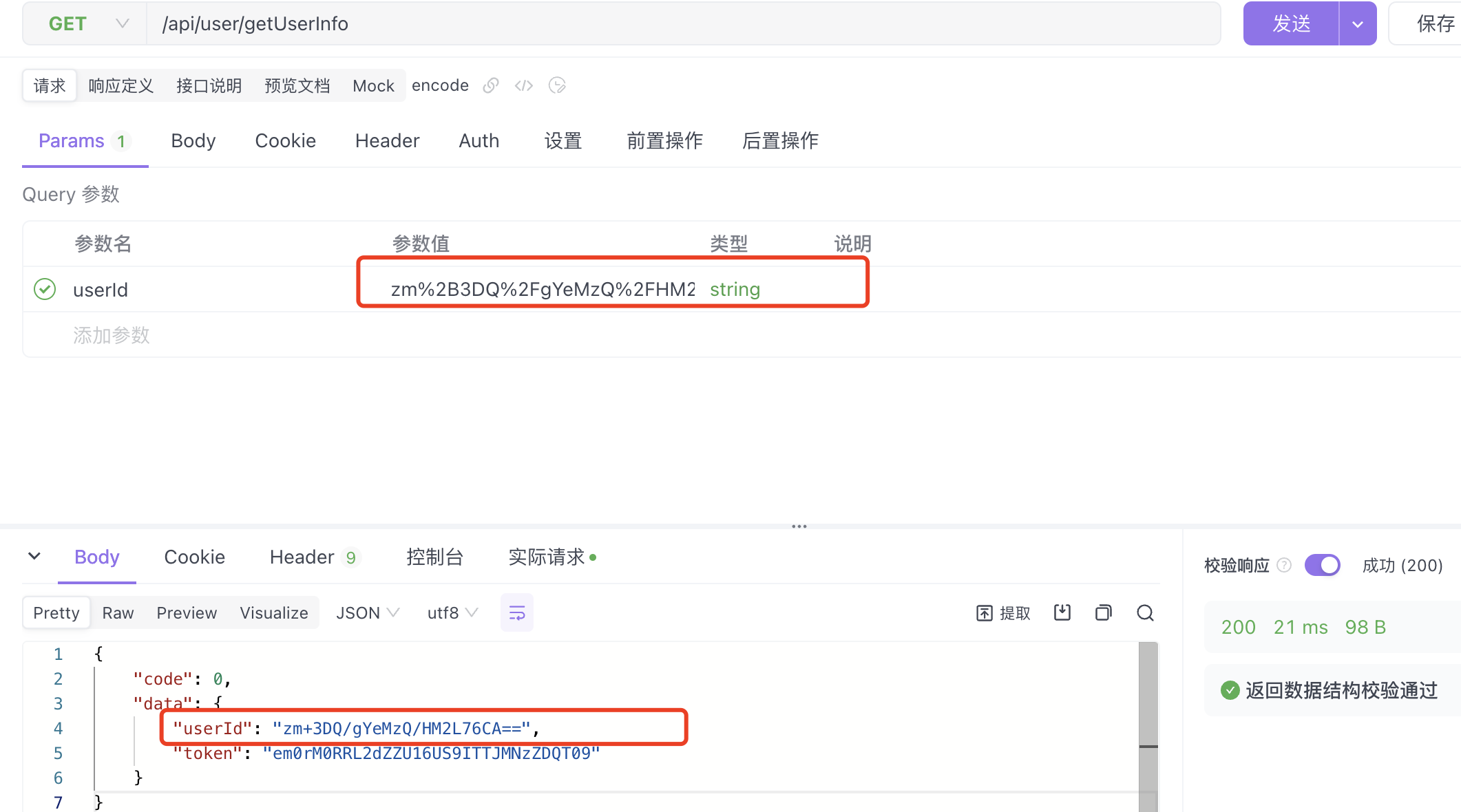
- 沒編碼,后端拿到的
+變成空格了
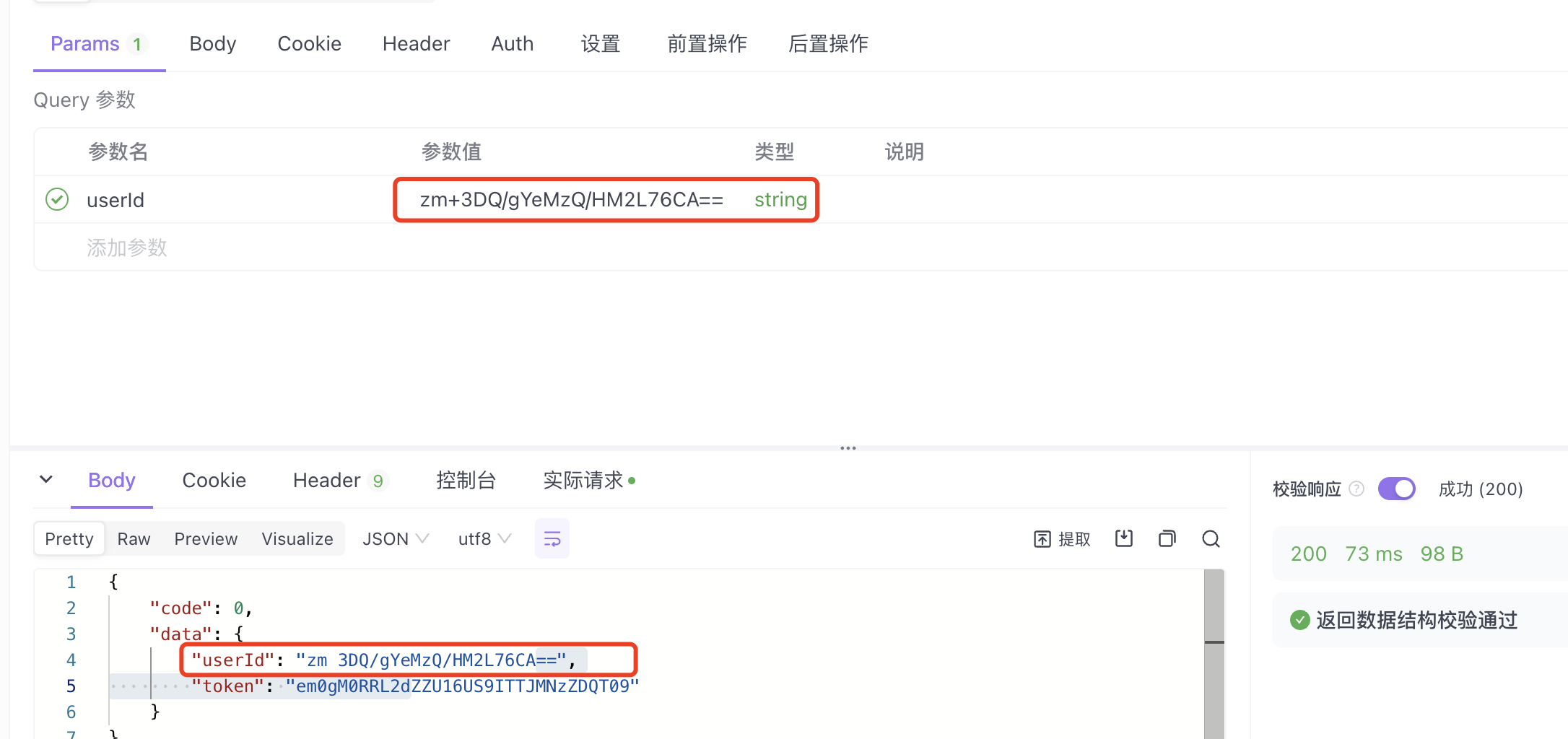
所以當時前端未進行編碼時,從CURL中就能看到+已經變成了空格,但后面前端編碼后,curl看是正常的,后端解碼出來卻還是有問題的。
我這邊怎么都復現不了當時傳給后端是編碼過的base64字符串,后端拿到的卻還是+變成了空格
沒辦法,只好找后端同學問問他當時是怎么解碼的...
經過一番驗證后,結論是他那邊多解碼了一次,他們框架層有一次自動解碼
'zm%2B3DQ%2FgYeMzQ%2FHM2L76CA%3D%3D' ----> 'zm+3DQ/gYeMzQ/HM2L76CA=='
實際上這里就已經是正確的了,但后端同學又自己解碼了一次,按理來說再次解碼應該也不會有問題

但是!!!這是因為javascript遵循的是RFC3986規范,但java好像并不是
java自帶的decode方法底層是這樣實現的

這里是按W3C的規范,由于URL中不能存在空格,所以URL Encode 會把空格替換成+,然后解碼也同樣會將+替換成空格。真相了....
解決方案
- 按理來說我們只需要保證傳給后端的
+字符按RFC3986規范編碼成了%2B就不會有問題,不要把編碼的機會留給瀏覽器,在JS中只需調用encodeURIComponent即可 - 后端接收到帶空格的
base64字符串時,通過正則將空格替換為+,因為base64中不會出現空格 - 由于標準
Base64編碼包含64個字符A-Z, a-z,0-9,+,/,=,有一種URL safe的base64格式,把其中的+,/換成-,_,也能夠解決上面的問題。
?https://www.cnblogs.com/songyao666/p/18707544
該文章在 2025/2/11 9:29:25 編輯過






 400 186 1886
400 186 1886


