1. 引言
無論是哪個平臺哪種編程語言,字符串亂碼真是一個讓人無語的問題:你說這個問題比較小吧,但是關鍵時刻來一下真是受不了。解決方式也有很多種,但是與其將編碼轉換來轉換去,不如統一使用同一種編碼方式,比如國際通用的UTF-8編碼。因此,新的程序代碼最好都統一使用UTF-8編碼的方式。但是C++作為一種歷史悠久的編程語言,肯定存在很多存量代碼,如何將其改造成UTF-8編碼也是一個問題,筆者在這里總結一二,可能不是很全,如果有遺漏就再開一篇補充。
2. 詳述
2.1 操作系統
統一使用統一使用UTF-8編碼還有個好處是跨平臺。但是操作系統本身也是有字符編碼的,這會影響到與操作系統相關的應用,比如說終端。Linux系統一般不用擔心,目前一般都默認使用UTF-8編碼。Windows系統則有點麻煩,一般使用ANSI碼(本地碼)。本地碼的意思就是基于當前系統區域設置的字符編碼,以國內大陸的來說就是國標碼:GB2312/GBK/GB18030。這就是為什么Windows的終端總是出現亂碼的原因,因為編碼不一致:GBK編碼的終端遇到UTF-8編碼字符串當然不會正確展示了。
當然現在Windows系統也能設置成UTF-8編碼了,如下圖1所示。但是還是建議不要輕易這么設置,Windows系統沒有將UTF-8編碼設置系統的默認編碼主要也是為了保證兼容性,在Unicode編碼大規模使用之前本地碼還是使用了相當長的時間的,有相當數據量的遺留程序都是使用的本地碼。為了避免大規模應用程序亂碼問題的出現,不能要求每個用戶都這么設置。
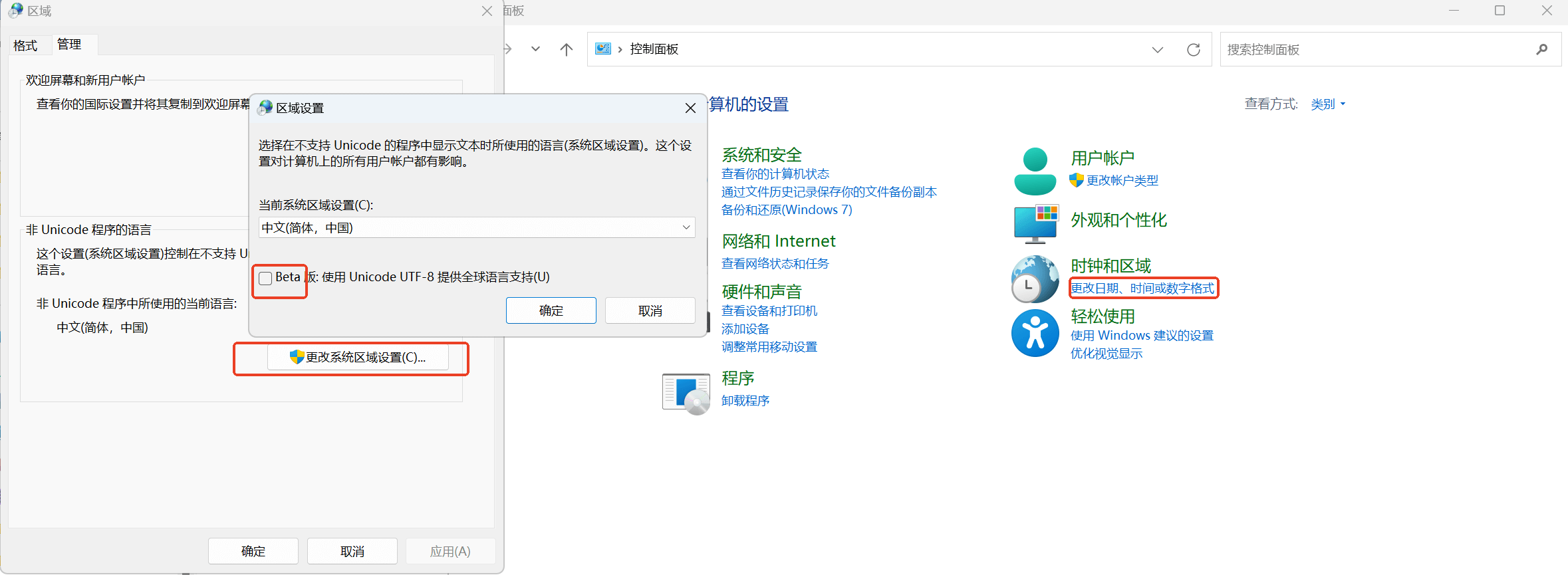
2.2 編譯器
雖然最好不要在操作系統層面設置成UTF-8編碼,但是還是可以編寫基于UTF-8編碼的程序的。將代碼文件修改成UTF-8編碼是一方面,另外一方面是編譯器要將代碼文件按照UTF-8編碼進行編譯。因為無論是ASCII、GB18030還是UTF-8編碼的文本文件,其實都是沒有具體的標識符的,編譯器需要知道以哪種字符編碼來編譯代碼文件中的字符。
Linux系統還是不用擔心,默認情況下文本文件通常使用UTF-8編碼,GCC編譯器也會默認使用系統的默認字符編碼也就是UTF-8編碼來進行編譯。麻煩的還是Windows系統,暫時不討論各種復雜的情況,筆者以Visual Studio的MSVC編譯器為例,介紹一下自己的做法。
首先還是要將代碼文件修改成UTF-8編碼,這里推薦使用Visual Studio的一個擴展:FileEncoding,它可以很方便的在代碼頁面的右下角修改代碼文件編碼,如下圖2所示。不過有一點要注意,選擇使用UTF-8編碼而不是UTF-8(BOM)編碼。
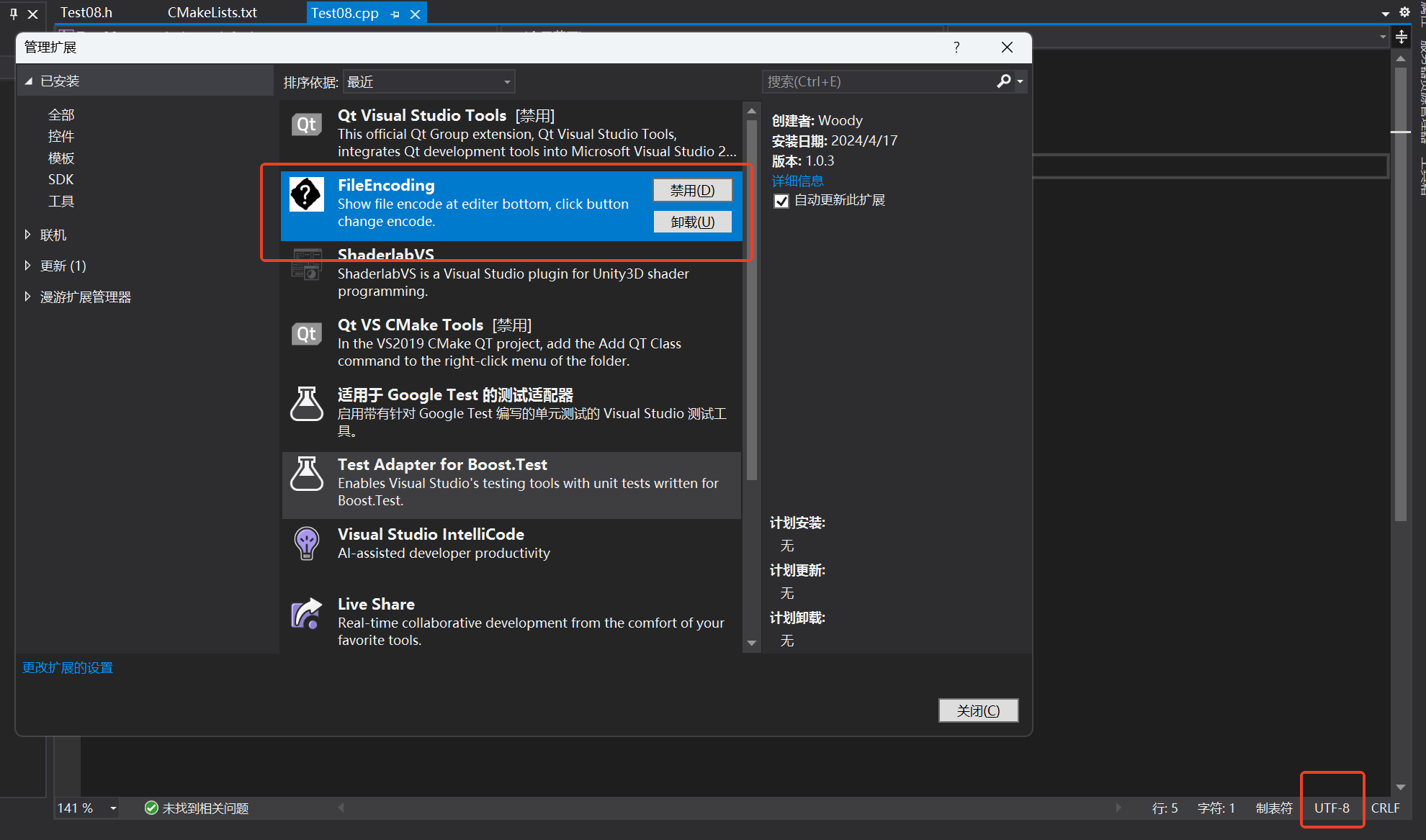
然后是給MSVC編譯器增加一個編譯選項:/utf-8,這個編譯選項會將源代碼字符集和執行字符集指定為使用UTF-8編碼字符集。具體來說,如果你是原生的MSVC的項目,應該執行的操作是:
- 打開項目“屬性頁” 對話框。
- 依次選擇“配置屬性”->“C/C++”->“命令行”屬性頁。
- 在“附加選項”中,添加/utf-8選項以指定首選編碼。
- 選擇“確定”以保存更改。
如果是CMake項目,那么在CMakeLists.txt中增加如下配置,意思是如果是MSVC編譯器,就增加/utf-8選項:
if ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "Clang")
message(">> using Clang")
elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "GNU")
message(">> using GCC")
elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "Intel")
message(">> using Intel C++")
elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "MSVC")
message(">> using Visual Studio C++")
add_compile_options("/utf-8")
else()
message(">> unknow compiler.")
endif()
最后,還需要考慮一點,字符最終需要顯示到終端的,無論是GUI終端還是命令行終端,你必須確保終端的字符編碼也是UTF-8編碼才行。例如打印字符串到命令行終端,可使用如下示例代碼(C++17環境下):
#include <iostream>
#ifdef _WIN32
#include <Windows.h>
#endif
using namespace std;
int main() {
#ifdef _WIN32
SetConsoleOutputCP(65001);
#endif
string str = "這是中文字符串,測試能否正確顯示!";
std::cout << str << endl;
return 0;
}
這段代碼的意思是在Windows環境下,設置控制臺輸出窗口的代碼頁是65001,也就是UTF-8編碼。同時由于代碼文件是UTF-8編碼,字符串常量"這是中文字符串,測試能否正確顯示!"也是UTF-8編碼。std::string與具體的字符編碼無關,它只是個8位字符數組,因此可以接受UTF-8編碼的字符串并被打印輸出。
2.3 漸進升級
按照以上步驟編寫新的基于UTF-8編碼的程序是沒有問題的,但是實際操作大概率不行。因為C++程序往往有足夠多的存量代碼,我們往往需要以庫的形式或者組件的形式來調用它們。問題是C++程序調用庫是需要include頭文件的,一旦設置了/utf-8編譯選項,MSVC就會強制將這些舊代碼按照UTF-8編碼進行編譯。在這種情況下,有很大的概率會出現亂碼問題,或者出現如下編譯錯誤:
warning C4828: 文件包含在偏移 0x66f 處開始的字符,該字符在當前源字符集中無效(代碼頁 65001)。
一般而言,MSVC項目的存量代碼一般為本地編碼(GBK編碼),最直接的解決方案是一個一個地按照上述方式去升級這些代碼,但是這樣做就要看存量代碼有多少、是否有權限這么做了,如果工作量太大還是不建議這么做。比較合理的辦法還是漸進式更新:
- 只在新的代碼項目中使用UTF-8編碼的方式。
- 舊的代碼項目還是使用GBK編碼。
- 修改調用的舊代碼庫的頭文件,保證沒有非ASCII字符(中文字符)。
由于UTF-8編碼是兼容ASCII字符的,因此即使強制要求MSVC按照UTF-8編碼編譯這個文件,也是不會出現亂碼或者編譯不通過的問題的。并且這樣也是有可行性的,一般頭文件的代碼內容很少,修改起來也不容易出錯。其實在大部分情況下也確實不需要修改什么,大多數常用庫為了方便國際通用,頭文件很少出現非ASCII字符。
當然這樣做也存在一個問題:舊的代碼接口是本地編碼,新的代碼卻是UTF-8編碼,調用的時候字符串傳參需要將UTF-8編碼轉換成GBK編碼字符串。但是這也是沒有辦法的辦法,只修改接口部分的代碼總比大規模修改程序好。想要完全避免字符編碼的問題就要統一使用UTF-8,最好按照這個原則,從調用端到底層框架逐漸將代碼都升級成UTF-8編碼。
3. 案例
所有接口統一使用UTF-8編碼真的是任何程序開發的金玉良言,否則就總是會遇到字符編碼轉換的問題,非常影響工作效率。不過可能因為兼容性或者其他原因,目前還做不到將所有的接口統一編碼。筆者這里就列舉一些常用的組件和庫的接口的字符串編碼案例。
3.1 std::filesystem::path
個人認為C++17的std::filesystem使用起來還是很方便的,但是std::filesystem::path的初始化并沒有如我所想統一使用UTF-8編碼。在Linux環境下初始化std::filesystem::path使用的確實是UTF-8編碼字符串,但是在Windows環境下,初始化需要使用UTF-16編碼字符串。例如一個初始化路徑的跨平臺代碼:
#ifdef _WIN32
std::filesystem::path launchConfigPath =
L"C:/Github/中文路徑/launch-config.json";
#else
std::filesystem::path launchConfigPath =
"/home/Github/中文路徑/launch-config.json";
#endif
在MSVC編譯器中,以L開頭的字符串是一個寬字符字符串,對應于UTF-16編碼。而如果本身是一個UTF-8編碼的std::string,那么就需要將其轉換成UTF-16編碼的字符串std::wstring,Windows下std::filesystem::path能使用std::wstring對象進行初始化。std::string和std::wstring的相互轉換如下所示:
std::wstring Utf8StringToWideString(const std::string& utf8_str) {
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
return converter.from_bytes(utf8_str);
}
std::string WideStringToUtf8String(const std::wstring& wstr) {
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
return converter.to_bytes(wstr);
}
經過筆者的驗證,其實Windows環境下使用GBK編碼字符串初始化std::filesystem::path也可以。不過這不是重點,重點是我很疑惑Windows環境下為什么不干脆統一使用UTF-8編碼初始化呢?本身標準庫的意義就在于統一不同系統環境下的行為,這里為了保證統一不得不又采用預編譯的辦法來跨平臺,感覺這里標準庫白標準了,微軟真是不做人啊。
不過,雖然std::filesystem::path的初始化使用的字符編碼不統一,但是卻可以返回UTF-8編碼字符串,函數接口是u8string()。另外,generic_u8string()接口不僅可以返回UTF-8編碼字符串,而且所有路徑的目錄分隔符被轉換為正斜杠(/)。所以,筆者采用的策略是只要是路徑相關的字符串,一開始就初始化成std::filesystem::path,路徑相關的操作就局限在這個對象中進行,從而避免考慮字符編碼的問題。并且,std::fstream也能接受std::filesystem::path作為參數,使用起來還是很方便的。
3.2 Qt的QString
Qt的QString筆者認為是最好的C++字符串實現,字符編碼實現的非常不錯。在代碼文件保存為UTF-8編碼,并且編譯器按照UTF-8編碼字符串的情況下,可以直接使用字符串字面量進行初始化:
QString str = "這是中文字符串";
這是因為"這是中文字符串"使用的是UTF-8編碼,這個字符串字面量會被正確地解釋為Unicode字符。接著當構造QString時,它能夠自動處理Unicode字符并將其轉換成內部使用的 UTF-16編碼。
但是對于已經存在的std::string或者其他形式的C風格字符串,需要顯式指明其編碼格式,以確保QString能夠正確地解碼它們,例如:
std::string stdString = "一些UTF-8編碼的文本";
QString str = QString::fromUtf8(stdString.c_str());
這是因為QString默認假設傳入的C風格字符串是以ISO 8859-1(Latin-1)編碼的。
3.3 GDAL
在統一使用UTF-8編碼之后,就不用再設置文件路徑的字符編碼不是UTF-8了,直接傳遞到GDALOpen函數中即可。
const char* imgPath = "E:\\Data\\lena.bmp";
GDALDataset* img = (GDALDataset *)GDALOpen(imgPath, GA_ReadOnly);
3.4 OpenCV
OpenCV的讀取圖像接口cv::imread使用的應該是本地編碼,在Windows環境下需要進行編碼轉換:
#ifdef _WIN32
img = cv::imread(Utf8ToGbk(externalTexPath.u8string()), cv::IMREAD_UNCHANGED);
#else
img = cv::imread(externalTexPath.u8string(), cv::IMREAD_UNCHANGED);
#endif
筆者之前的博文《c++中utf8字符串和gbk字符串的轉換》中提供了Utf8編碼與GBK編碼之間的轉換。
4. 補充
筆者查閱字符編碼相關的資料的時候,就感嘆這方面的知識還真就是一本爛賬,除非深入了解,否則是無法完全論述清楚的。個人看法是要認清字符編碼的本質是將有意義的字符與二進制數據類型類型對應起來。以國內的情況來說,我們只需要理解三種字符編碼:ASCII、ANSI以及Unicode,它們大致分別對應于1個字節、2個字節、以及4個字節。
- ASCII編碼是原始編碼,包含大小寫英文字符+數字+標點符號+控制字符+特殊字符,總共是128個。因此準確來說ASCII編碼是7位字符編碼,但在高級語言中使用最小的數據類型就是1字節整型了。
- ANSI編碼是本地編碼,在國內的Windows環境中通常指國標碼(國家標準標碼),更加具體一點就是GB2312、GBK和GB18030這三種編碼。其中,GB2312編碼是第一版國標碼,GBK編碼最常用,但是GB18030編碼是最新的。國標碼最初被設計出來的時候,是2個字節對應于1個字符,同時沒有占用ASCII編碼的內容,因此是兼容ANSI編碼的。
- Unicode編碼是國際編碼,它被設計出來的目的就是囊括并且統一世界上所有的字符,以此解決世界上不同本地編碼字符編碼轉換的問題。Unicode編碼最初被設計出來的時候,同樣是2個字節對應于1個字符,這就是UTF-16編碼。但是字符的增加,Unicode編號很快不夠用了,就擴展成了4字節對應于1個字符,這就是UTF-32編碼。UTF-32編碼的問題就是太浪費了,比如UTF-32編碼的前128位與ANSI編碼的編號是一樣的,但是卻要用4個字節表示,實際上與ANSI編碼一樣,同樣使用1個字節即可。基于這樣的思想就誕生了UTF-8編碼,每個字符根據所分配的Unicode編號大小,使用1~4個字節來表示。
- 那么原來2個字節的UTF-16編碼遇到超過2字節范圍的字符怎么辦呢?答案是使用2個連續的2個字節來進行表示。UTF-16編碼的影響還是非常深遠的,C#的
string、Java的string、Qt的QString以及Win32 API普遍都使用UTF-16編碼。為了保證對4個字節字符的兼容,它們往往會采用“代理對”的技術,由系統實現正常處理字符串長度、索引或其他涉及字符級別的操作。 - UTF-8變長編碼的思想也影響了國標碼的設計,最新的國標碼GB18030編碼也擴展成為了變長編碼,并且兼容ASCII字符的單字節編碼,以及GB2312和GBK的雙字節編碼部分。
- 本文中筆者不想將問題復雜化,特意沒有論述到UTF-8 BOM編碼的內容。UTF-8 BOM編碼與UTF-8編碼是一樣的,只不過在字符內容的部分加了幾個標識符,從而可以讓編輯器知道該字符內容是UTF-8編碼的。UTF-8 BOM編碼也是微軟搞出來的,主要是用來方便在本地編碼的環境中識別出UTF-8編碼。一般國際上更推薦統一使用標準的UTF-8編碼。
5. 參考
- /utf-8 (Set source and execution character sets to UTF-8)
- 探究 Visual Studio 中的亂碼問題
- VS2019 報錯“常量中有換行符”錯誤原因分析
- vs2015:/utf-8 選項解決 UTF-8 without BOM 源碼中文輸出亂碼問題
轉自https://www.cnblogs.com/charlee44/p/18712053
該文章在 2025/2/13 10:16:42 編輯過






 400 186 1886
400 186 1886


