Tesseract OCR:開源的文字識別引擎
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
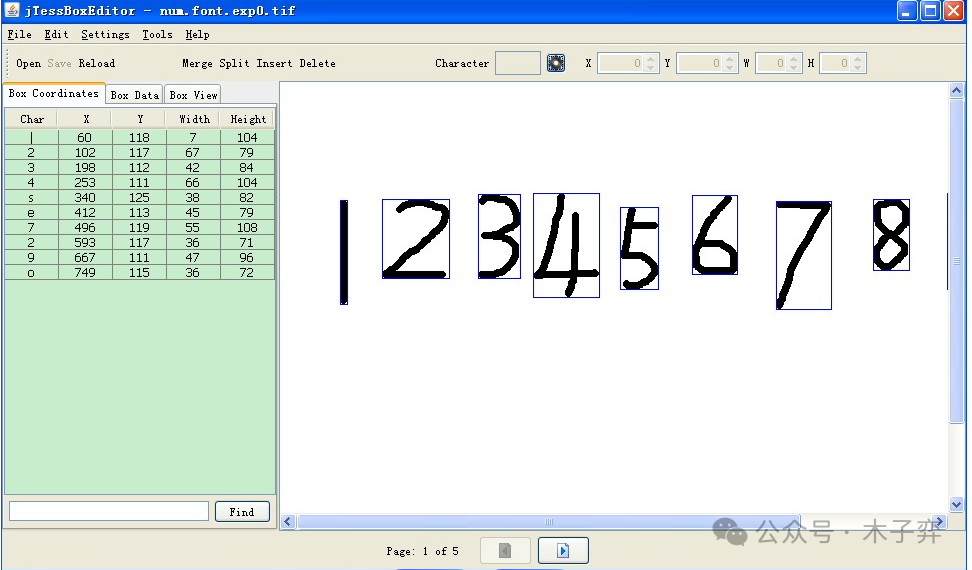
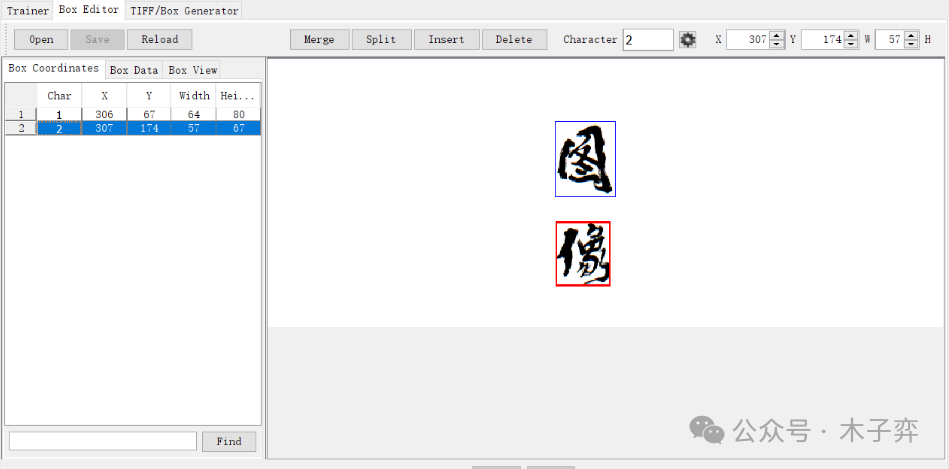
Tesseract OCR 是一個開源的光學字符識別(OCR)引擎,由惠普實驗室于1985年開發(fā),并在2005年由谷歌接手維護。Tesseract 以其高精度、靈活性和開源特性,成為OCR領域中最受歡迎的工具之一。它能夠從圖像中提取文本,并支持超過100種語言的識別,廣泛應用于文檔數(shù)字化、自動化數(shù)據(jù)錄入、圖像分析等領域。
1. Tesseract OCR 的核心特性Tesseract OCR 具有以下核心特性:
2. Tesseract OCR 的工作原理Tesseract OCR 的工作流程可以分為以下幾個步驟:
3. Tesseract OCR 的應用場景Tesseract OCR 的應用場景非常廣泛,以下是一些典型的例子:
4. Tesseract OCR 的安裝與使用安裝 Tesseract OCR在大多數(shù)Linux發(fā)行版中,可以通過包管理器安裝Tesseract: sudo apt-get install tesseract-ocr在Windows和macOS上,可以從Tesseract官網(wǎng)下載預編譯的二進制文件。 使用 Tesseract OCRTesseract 提供了命令行工具,可以快速進行OCR識別。以下是一個簡單的示例: tesseract input_image.png output_text -l eng
在 Python 中使用 Tesseract通過 from PIL import Image5. Tesseract OCR 的優(yōu)缺點優(yōu)點:
缺點:
6. Tesseract OCR 的未來發(fā)展
隨著深度學習和計算機視覺技術的不斷進步,Tesseract OCR 也在持續(xù)優(yōu)化和改進。未來的發(fā)展方向可能包括:
7. 總結Tesseract OCR 是一個功能強大、開源免費的文字識別工具,適用于各種OCR應用場景。無論是文檔數(shù)字化、自動化數(shù)據(jù)錄入,還是多語言文本識別,Tesseract 都能提供可靠的解決方案。盡管在處理低質(zhì)量圖像時可能存在一些挑戰(zhàn),但通過適當?shù)念A處理和模型訓練,Tesseract 仍然可以滿足大多數(shù)用戶的需求。 如果你正在尋找一個高效、靈活的OCR工具,Tesseract OCR 無疑是一個值得嘗試的選擇。通過結合其強大的功能和開源社區(qū)的支持,你可以輕松實現(xiàn)從圖像中提取文本的目標。 閱讀原文:原文鏈接 該文章在 2025/2/24 10:13:44 編輯過 |
關鍵字查詢
相關文章
正在查詢... 的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務費用、相關報表等業(yè)務管理,結合碼頭的業(yè)務特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標簽打印,條形碼,二維碼管理,批號管理軟件。")
同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
")