前言
今天要討論一個讓無數人抓狂的話題:如何高效導入百萬級Excel數據。
去年有家公司找到我,他們的電商系統遇到一個致命問題:每天需要導入20萬條商品數據,但一執行就卡死,最長耗時超過3小時。
更魔幻的是,重啟服務器后前功盡棄。
經過半天的源碼分析,我們發現了下面這些觸目驚心的代碼...
1 為什么傳統導入方案會崩盤?
很多小伙伴在實現Excel導入時,往往直接寫出這樣的代碼:
public void importExcel(File file) {
List<Product> list = ExcelUtils.readAll(file);
for (Product product : list) {
productMapper.insert(product);
}
}
這種寫法會引發三大致命問題:
1.1 內存熔斷:堆區OOM慘案
- 問題:POI的
UserModel(如XSSFWorkbook)一次性加載整個Excel到內存 - 實驗:一個50MB的Excel(約20萬行)直接耗盡默認的1GB堆內存
- 癥狀:頻繁Full GC ? CPU飆升 ? 服務無響應
1.2 同步阻塞:用戶等到崩潰
- 過程:用戶上傳文件 → 同步等待所有數據處理完畢 → 返回結果
- 風險:連接超時(HTTP默認30秒斷開)→ 任務丟失
1.3 效率黑洞:逐條操作事務
- 實測數據:MySQL單線程逐條插入≈200條/秒 → 處理20萬行≈16分鐘
- 幕后黑手:每次insert都涉及事務提交、索引維護、日志寫入
2 性能優化四板斧
第一招:流式解析
使用POI的SAX模式替代DOM模式:
OPCPackage pkg = OPCPackage.open(file);
XSSFReader reader = new XSSFReader(pkg);
SheetIterator sheets = (SheetIterator) reader.getSheetsData();
while (sheets.hasNext()) {
try (InputStream stream = sheets.next()) {
Sheet sheet = new XSSFSheet();
RowHandler rowHandler = new RowHandler();
sheet.onRow(row -> rowHandler.process(row));
sheet.process(stream);
}
}
?? 避坑指南:
- 不同Excel版本需適配(HSSF/XSSF/SXSSF)
- 避免在解析過程中創建大量對象,需復用數據容器
第二招:分頁批量插入
基于MyBatis的批量插入+連接池優化:
public void batchInsert(List<Product> list) {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
ProductMapper mapper = sqlSession.getMapper(ProductMapper.class);
int pageSize = 1000;
for (int i = 0; i < list.size(); i += pageSize) {
List<Product> subList = list.subList(i, Math.min(i + pageSize, list.size()));
mapper.batchInsert(subList);
sqlSession.commit();
sqlSession.clearCache();
}
}
關鍵參數調優:
mybatis.executor.batch.size=1000
spring.datasource.druid.maxActive=50
spring.datasource.druid.initialSize=10
第三招:異步化處理
架構設計:
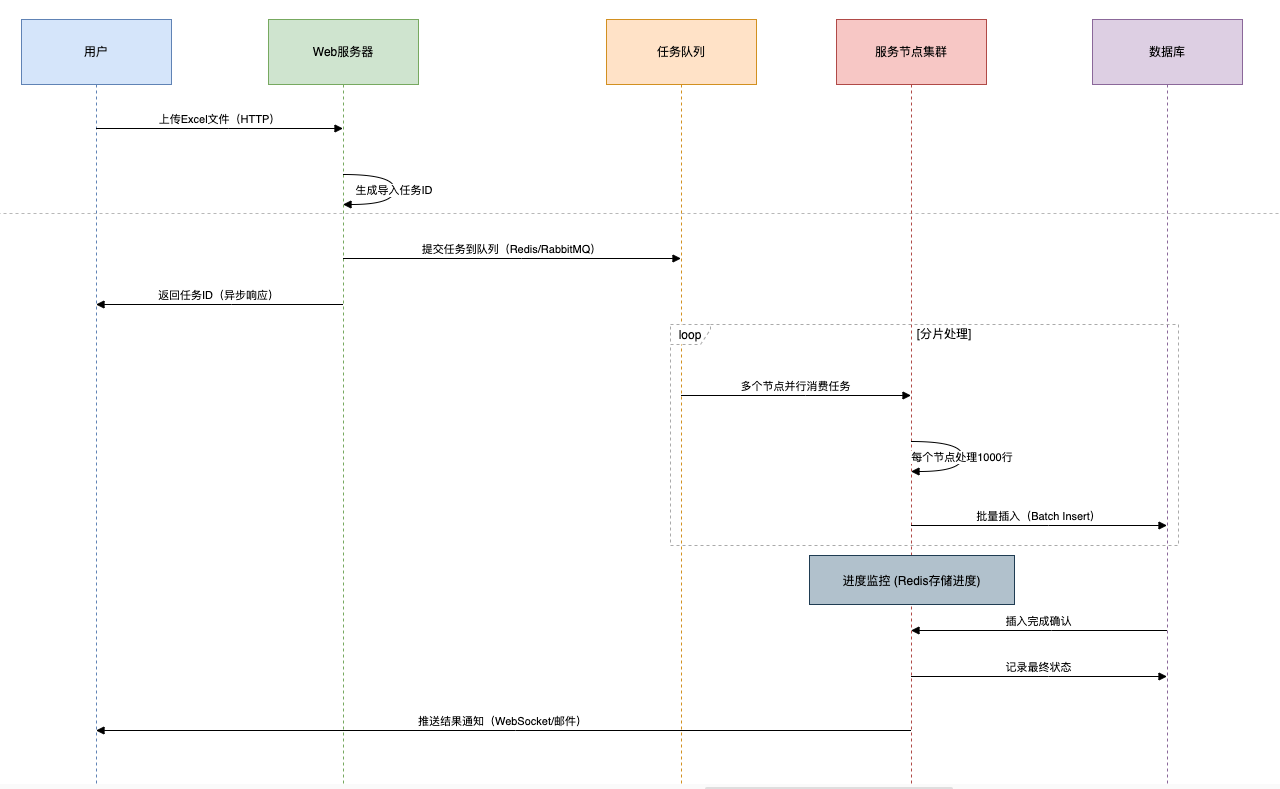
- 前端上傳:客戶端使用WebUploader等分片上傳工具
- 服務端:
- 生成唯一任務ID
- 寫入任務隊列(Redis Stream/RabbitMQ)
- 異步線程池:
- 結果通知:通過WebSocket或郵件推送完成狀態
第四招:并行導入
對于千萬級數據,可采用分治策略:
| 階段 | 操作 | 耗時對比 |
|---|
| 單線程 | 逐條讀取+逐條插入 | 基準值100% |
| 批處理 | 分頁讀取+批量插入 | 時間降至5% |
| 多線程分片 | 按Sheet分片,并行處理 | 時間降至1% |
| 分布式分片 | 多節點協同處理(如Spring Batch集群) | 時間降至0.5% |
3 代碼之外的關鍵經驗
3.1 數據校驗必須前置
典型代碼缺陷:
public void validateAndInsert(Product product) {
if (product.getPrice() < 0) {
throw new Exception("價格不能為負");
}
productMapper.insert(product);
}
? 正確實踐:
- 在流式解析階段完成基礎校驗(格式、必填項)
- 入庫前做業務校驗(數據關聯性、唯一性)
3.2 斷點續傳設計
解決方案:
- 記錄每個分片的處理狀態
- 失敗時根據偏移量(offset)恢復
3.3 日志與監控
配置要點:
@Bean
public MeterRegistryCustomizer<PrometheusMeterRegistry> metrics() {
return registry -> registry.config().meterFilter(
new MeterFilter() {
@Override
public DistributionStatisticConfig configure(Meter.Id id, DistributionStatisticConfig config) {
return DistributionStatisticConfig.builder()
.percentiles(0.5, 0.95)
.build().merge(config);
}
}
);
}
四、百萬級導入性能實測對比
測試環境:
- 服務器:4核8G,MySQL 8.0
- 數據量:100萬行x15列(約200MB Excel)
| 方案 | 內存峰值 | 耗時 | 吞吐量 |
|---|
| 傳統逐條插入 | 2.5GB | 96分鐘 | 173條/秒 |
| 分頁讀取+批量插入 | 500MB | 7分鐘 | 2381條/秒 |
| 多線程分片+異步批量 | 800MB | 86秒 | 11627條/秒 |
| 分布式分片(3節點) | 300MB/節點 | 29秒 | 34482條/秒 |
總結
Excel高性能導入的11條軍規:
- 決不允許全量加載數據到內存 → 使用SAX流式解析
- 避免逐行操作數據庫 → 批量插入加持
- 永遠不要讓用戶等待 → 異步處理+進度查詢
- 橫向擴展比縱向優化更有效 → 分片+分布式計算
- 內存管理是生死線 → 對象池+避免臨時大對象
- 合理配置連接池參數 → 杜絕瓶頸在數據源
- 前置校驗絕不動搖 → 臟數據必須攔截在入口
- 監控務必完善 → 掌握全鏈路指標
- 設計必須支持容災 → 斷點續傳+冪等處理
- 拋棄單機思維 → 擁抱分布式系統設計
- 測試要覆蓋極端場景 → 百萬數據壓測不可少
?轉自https://www.cnblogs.com/12lisu/p/18805646
該文章在 2025/4/3 11:37:20 編輯過






 400 186 1886
400 186 1886


