大模型 Token 究竟是啥:圖解大模型Token
當(dāng)前位置:點晴教程→知識管理交流
→『 技術(shù)文檔交流 』
前幾天,一個朋友問我:“大模型中的 Token 究竟是什么?” 這確實是一個很有代表性的問題。許多人聽說過 Token 這個概念,但未必真正理解它的作用和意義。思考之后,我決定寫篇文章,詳細解釋這個話題。 我說:像 DeepSeek 和 ChatGPT 這樣的超大語言模型,都有一個“刀法精湛”的小弟——分詞器(Tokenizer)。
當(dāng)大模型接收到一段文字。
會讓分詞器把它切成很多個小塊。
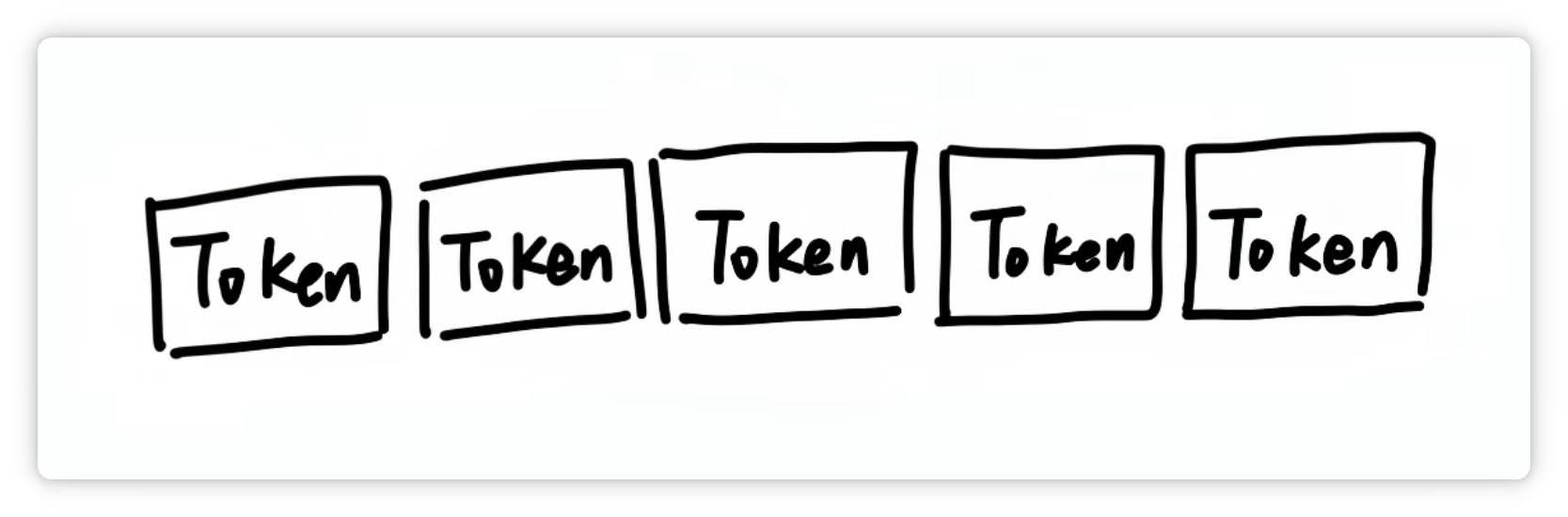
這切出來的每一個小塊就叫做一個 Token。
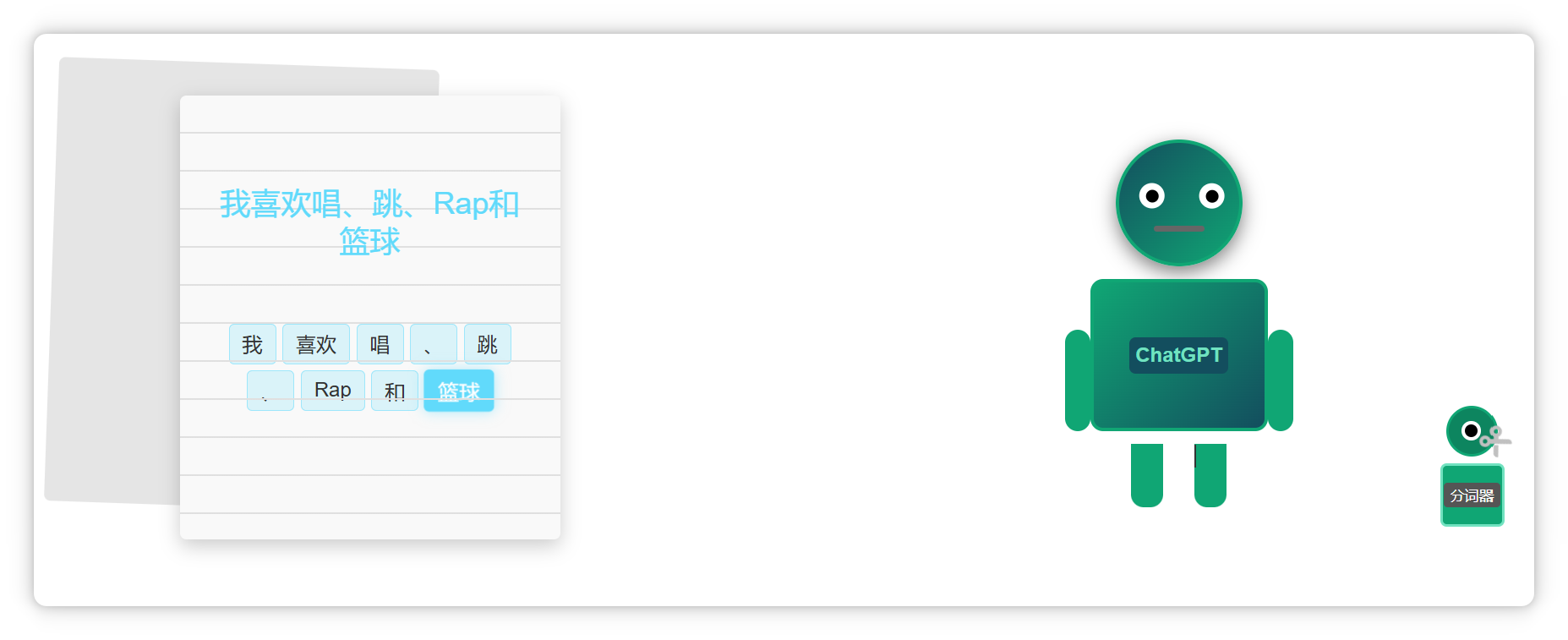
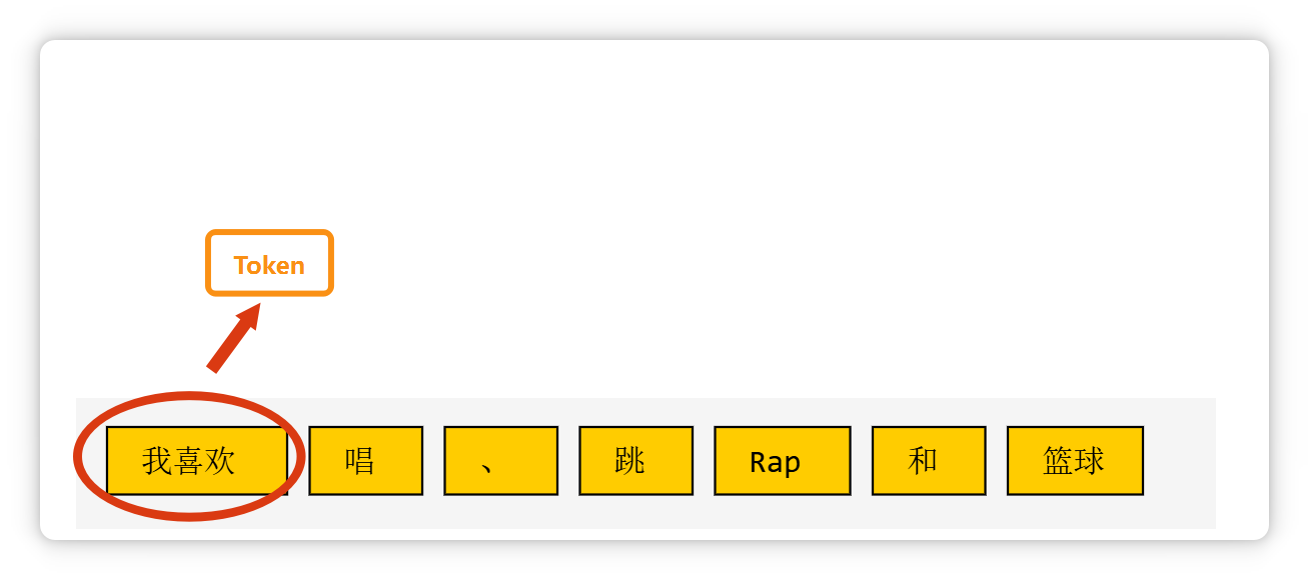
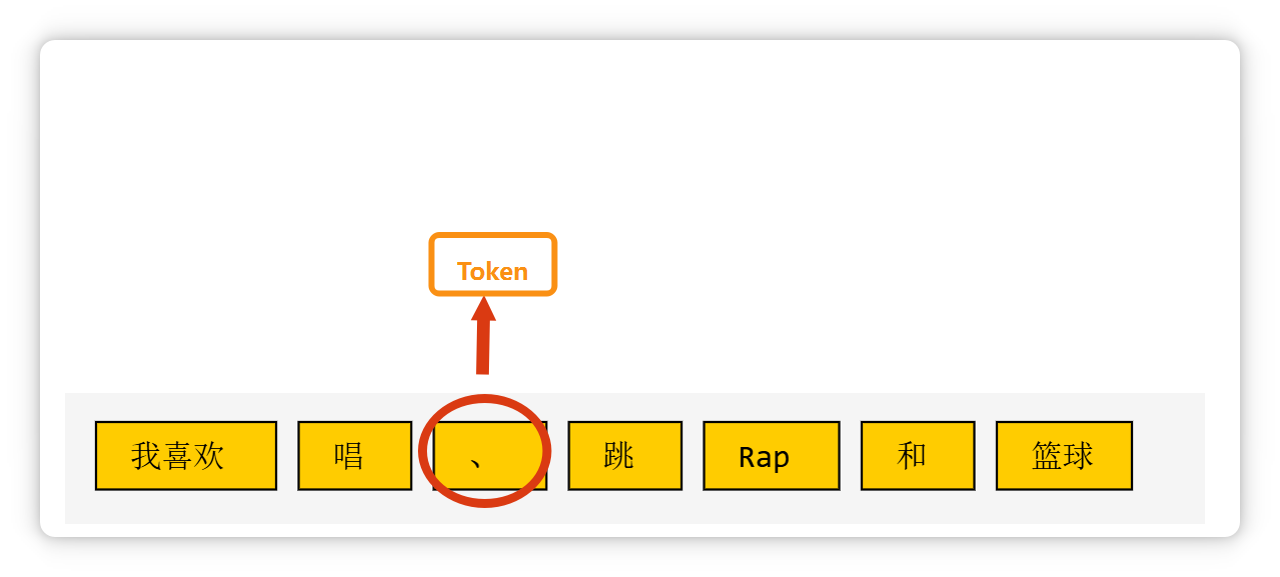
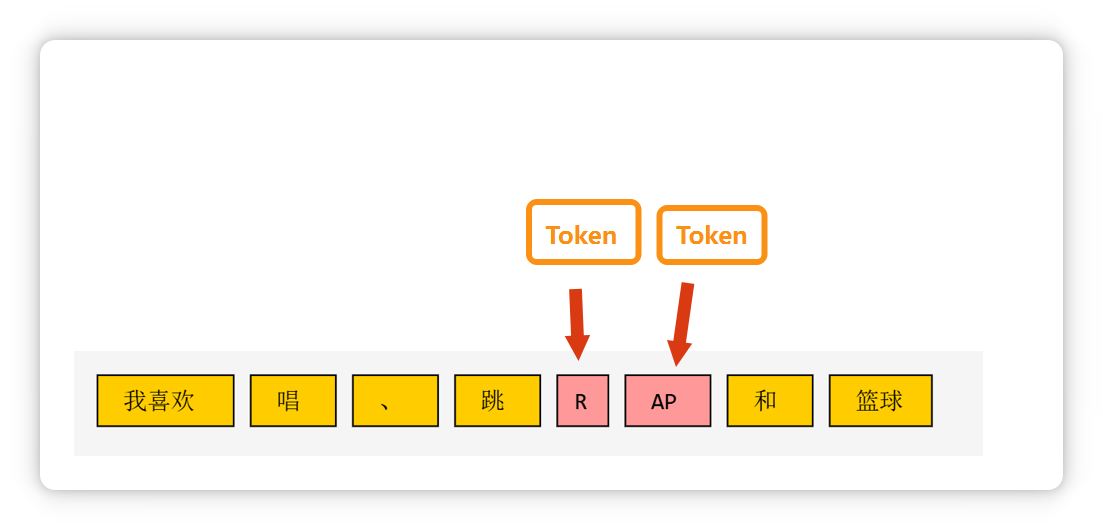
比如這段話(我喜歡唱、跳、Rap和籃球),在大模型里可能會被切成這個樣子。
像單個漢字,可能是一個 Token。
兩個漢字構(gòu)成的詞語,也可能是一個 Token。
三個字構(gòu)成的常見短語,也可能是一個 Token。
一個標(biāo)點符號,也可能是一個 Token。
一個單詞,或者是幾個字母組成的一個詞綴,也可能是一個 Token。
大模型在輸出文字的時候,也是一個 Token 一個 Token 的往外蹦,所以看起來可能有點像在打字一樣。
朋友聽完以后,好像更疑惑了:
于是,我決定換一個方式,給他通俗解釋一下。 大模型的Token究竟是啥,以及為什么會是這樣。 首先,請大家快速讀一下這幾個字:
是不是有點沒有認出來,或者是需要愣兩秒才可以認出來? 但是如果這些字出現(xiàn)在詞語或者成語里,你瞬間就可以念出來。
那之所以會這樣,是因為我們的大腦在日常生活中,喜歡把這些有含義的詞語或者短語,優(yōu)先作為一個整體來對待。
不到萬不得已,不會去一個字一個字的摳。
這就導(dǎo)致我們對這些詞語還挺熟悉,單看這些字(旯妁圳侈邯)的時候,反而會覺得有點陌生。 而大腦??之所以要這么做,是因為這樣可以節(jié)省腦力,咱們的大腦還是非常懂得偷懶的。
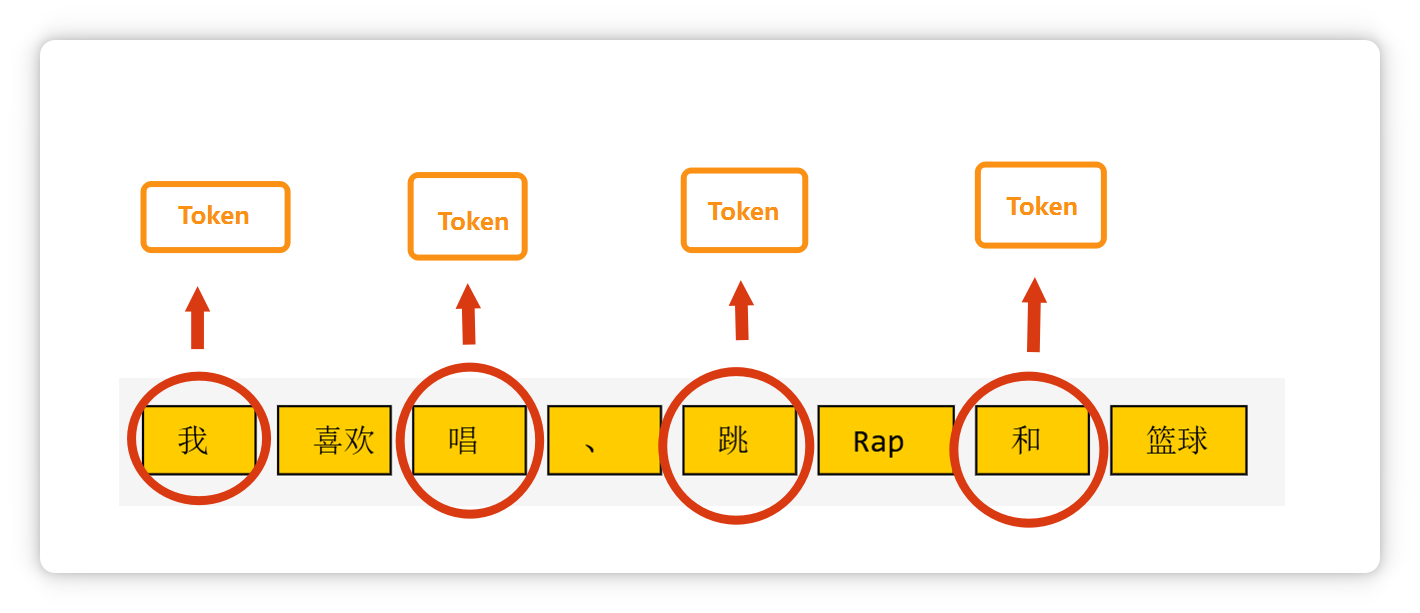
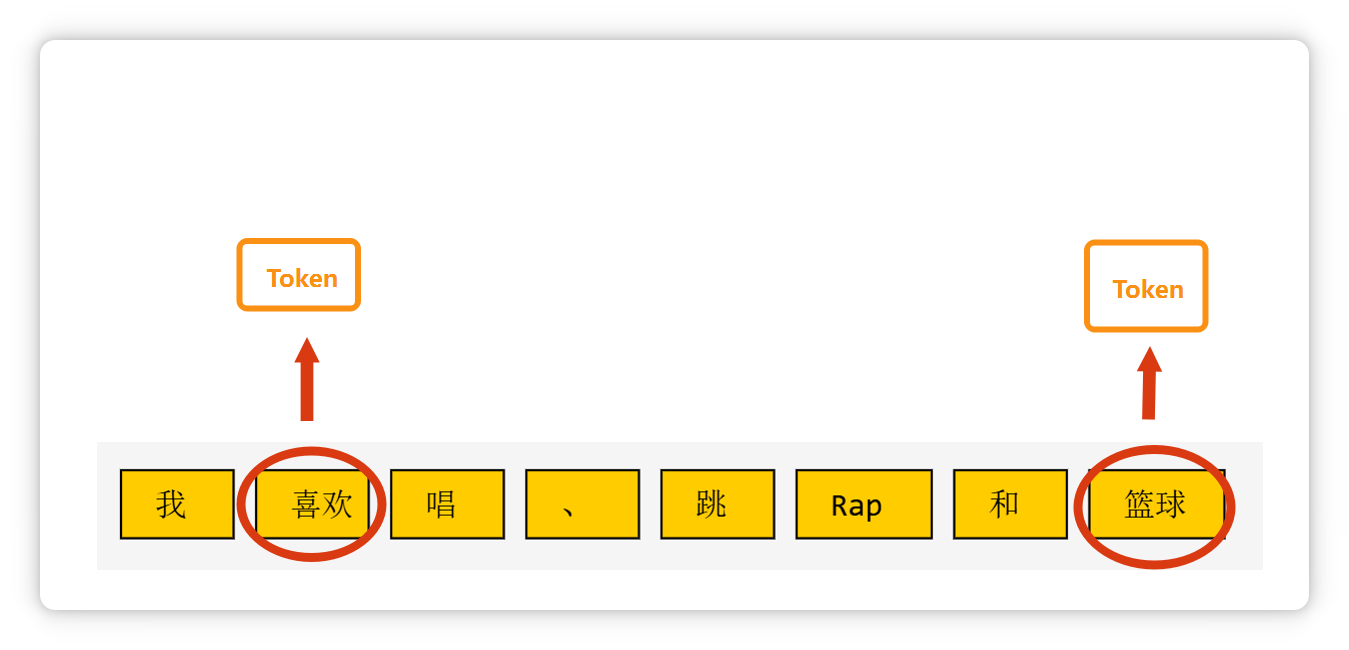
比如 “今天天氣不錯” 這句話,如果一個字一個字的去處理,一共需要有6個部分。
但是如果劃分成3個、常見且有意義的詞。
就只需要處理3個部分之間的關(guān)系,從而提高效率,節(jié)省腦力。 既然人腦可以這么做,那人工智能也可以這么做。
所以就有了分詞器,專門幫大模型把大段的文字,拆解成大小合適的一個個 Token。
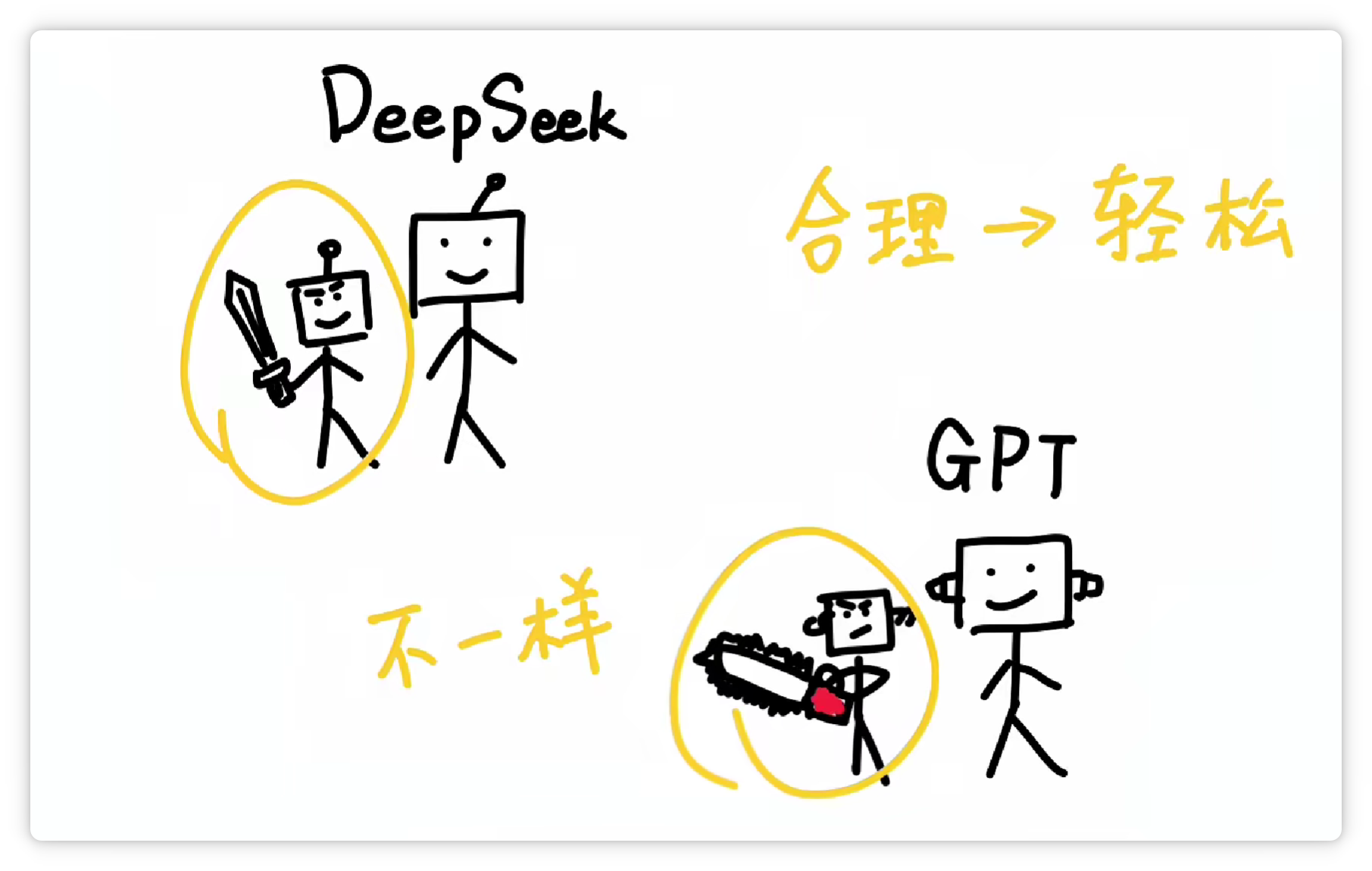
不同的分詞器,它的分詞方法和結(jié)果不一樣。
分得越合理,大模型就越輕松。這就好比餐廳里負責(zé)切菜的切配工,它的刀功越好,主廚做起菜來當(dāng)然就越省事。
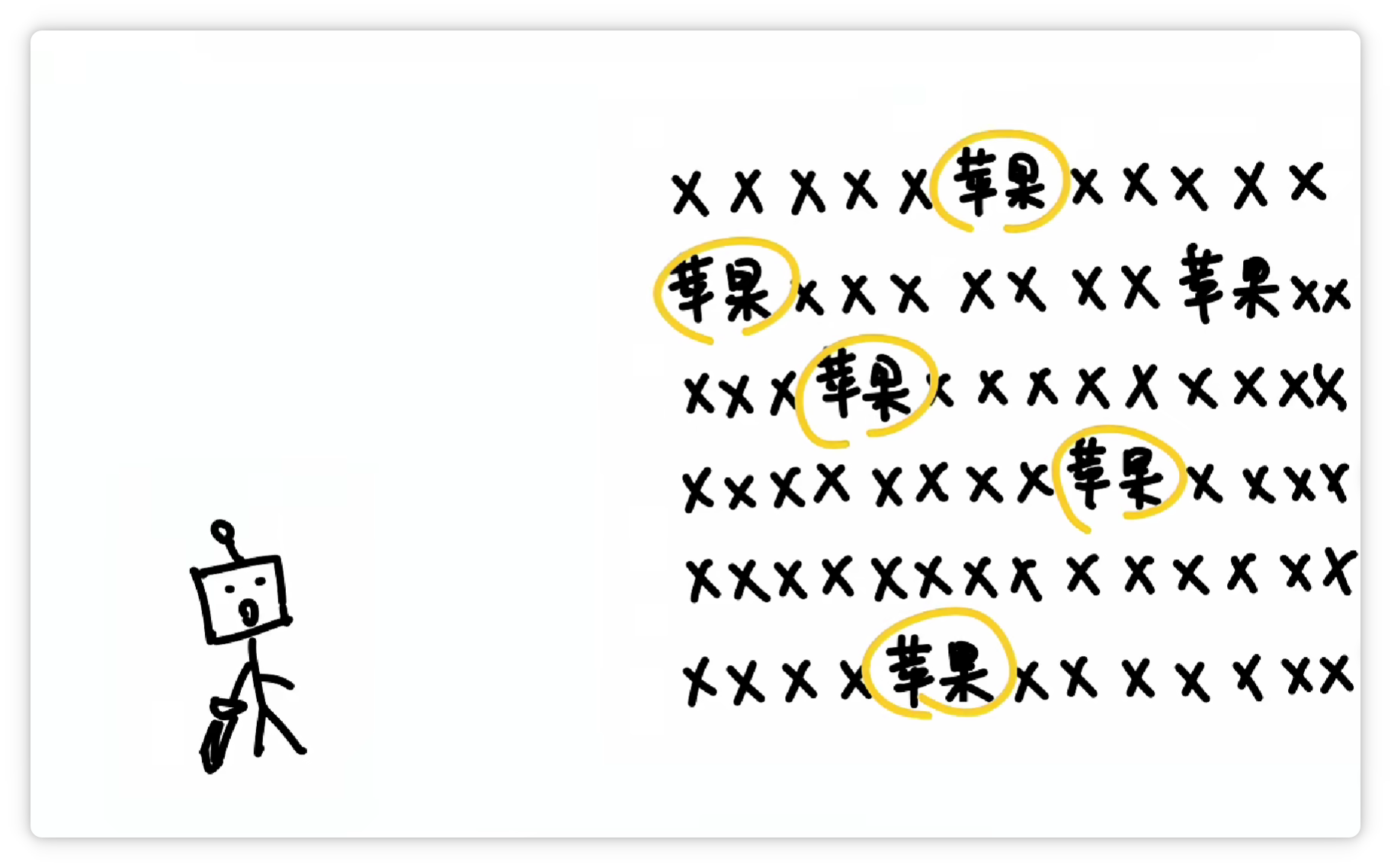
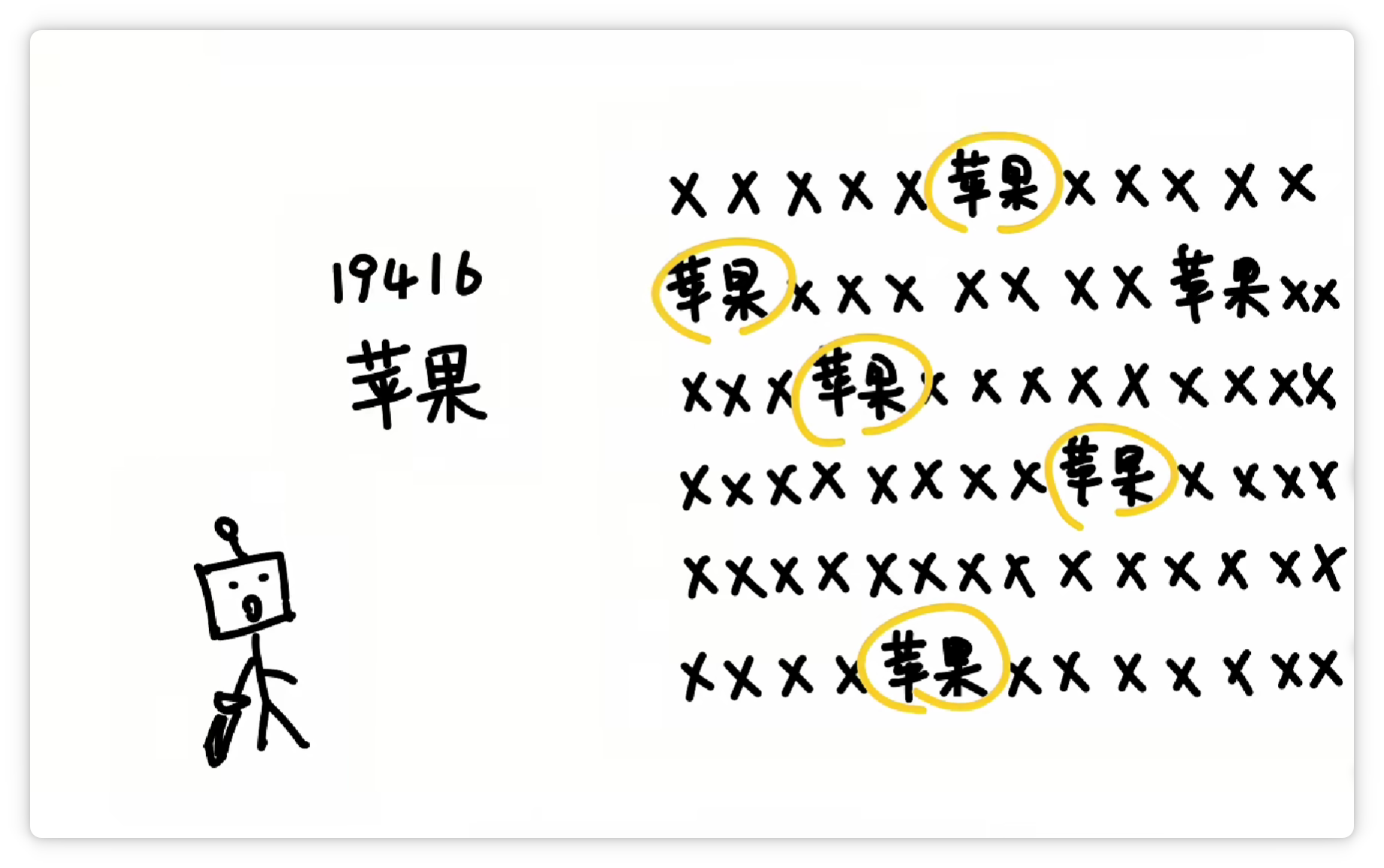
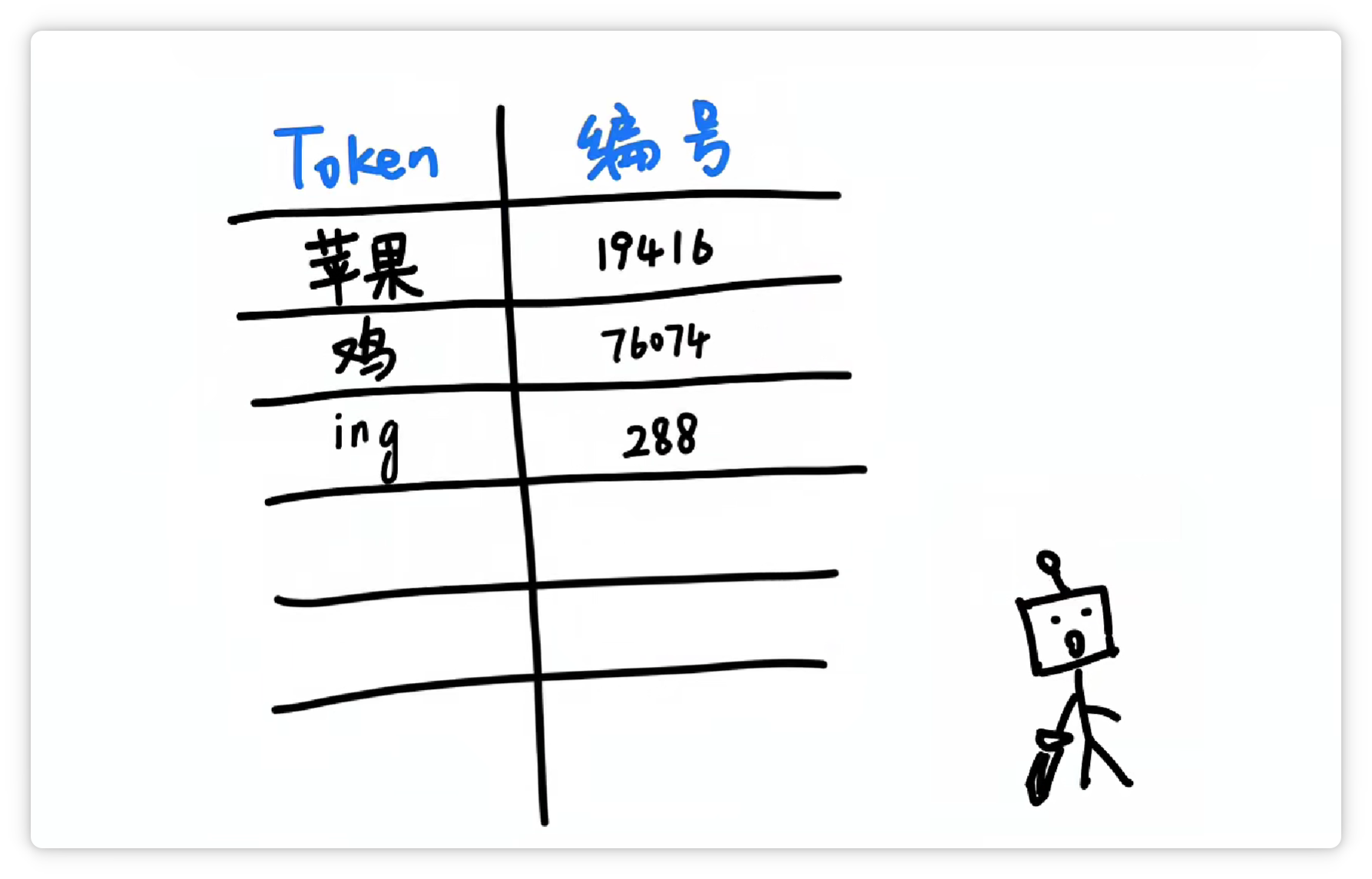
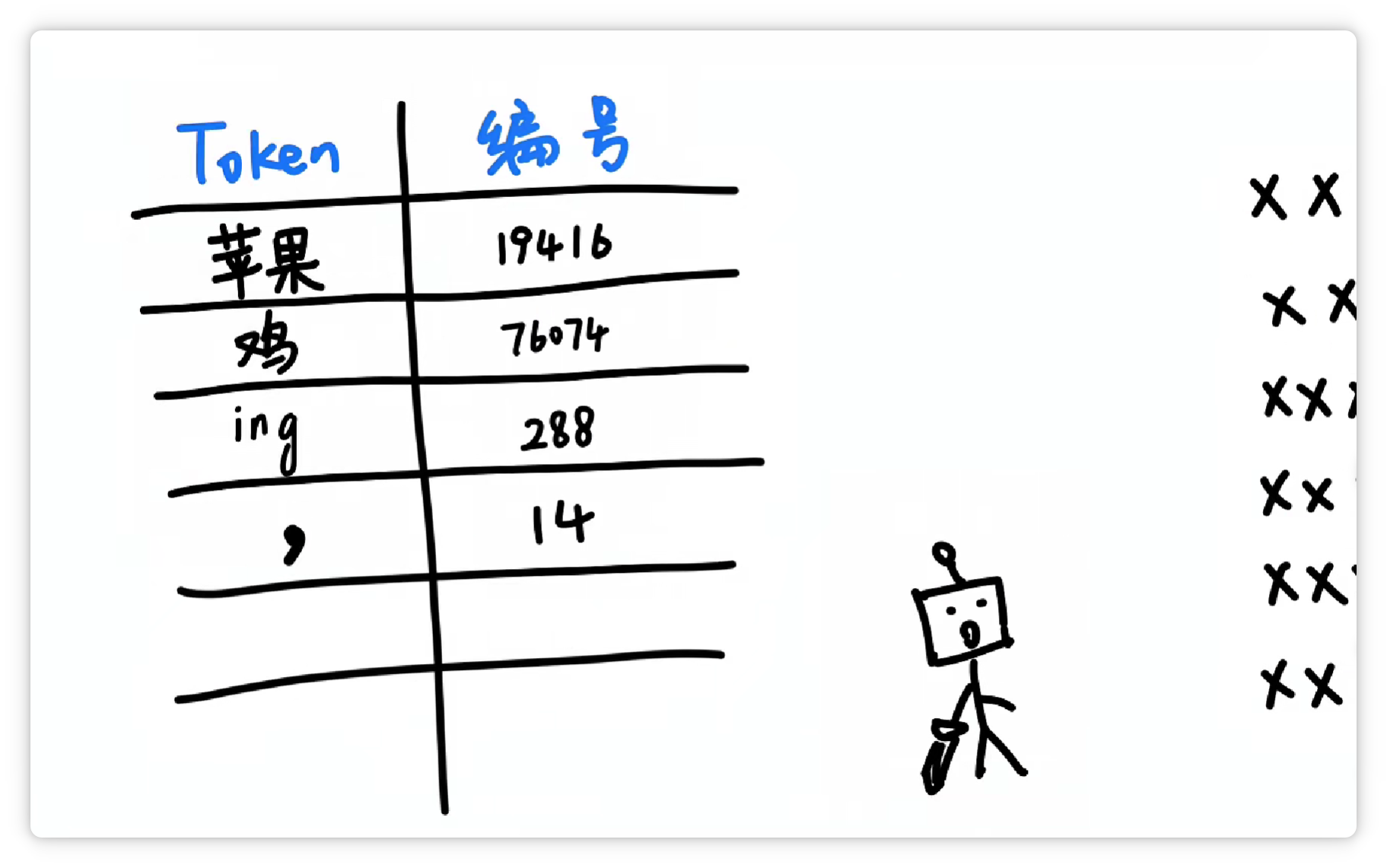
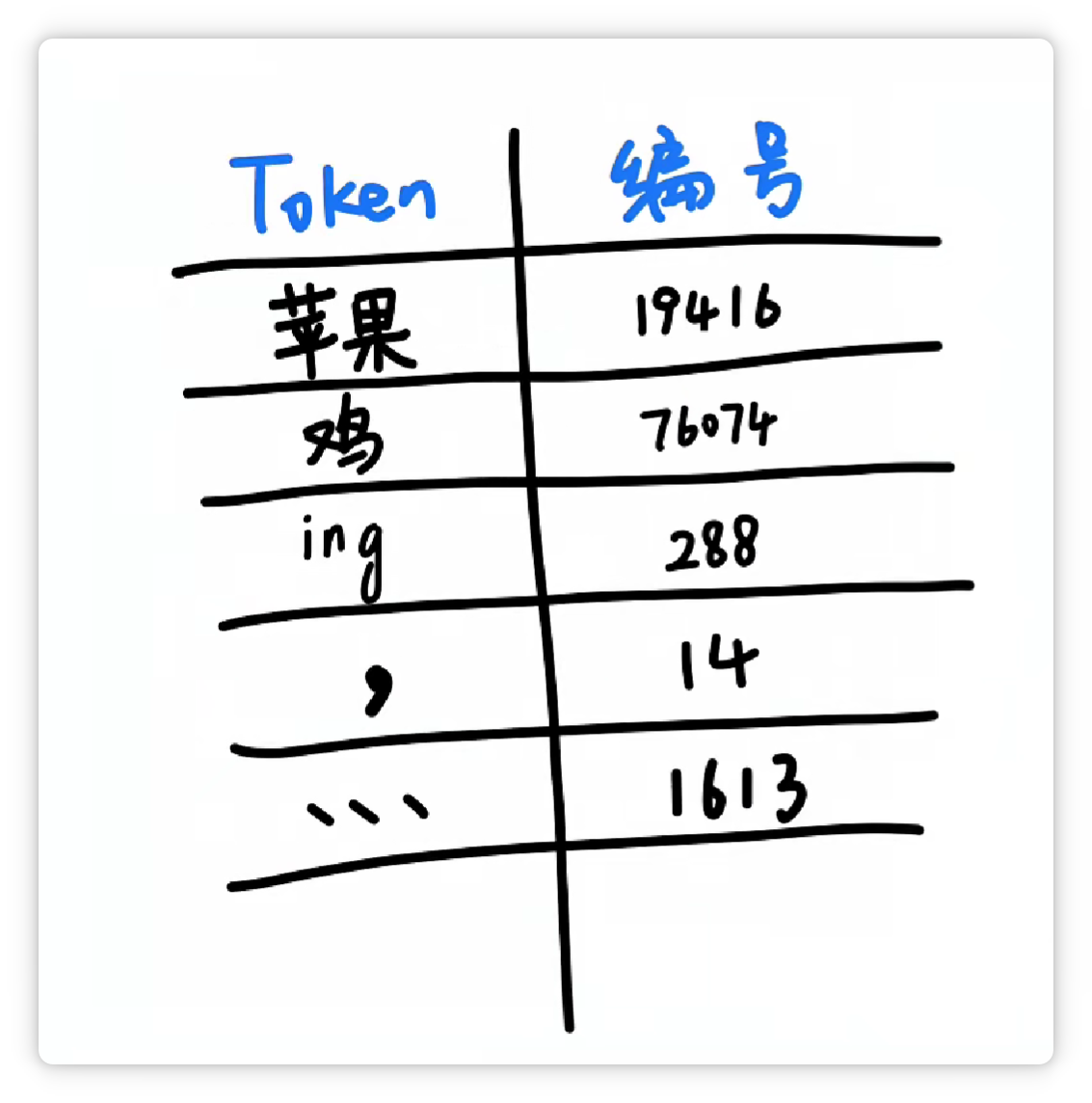
分詞器究竟是怎么分的詞呢? 其中一種方法大概是這樣,分詞器統(tǒng)計了大量文字以后,發(fā)現(xiàn) “蘋果” 這兩個字,經(jīng)常一起出現(xiàn)。
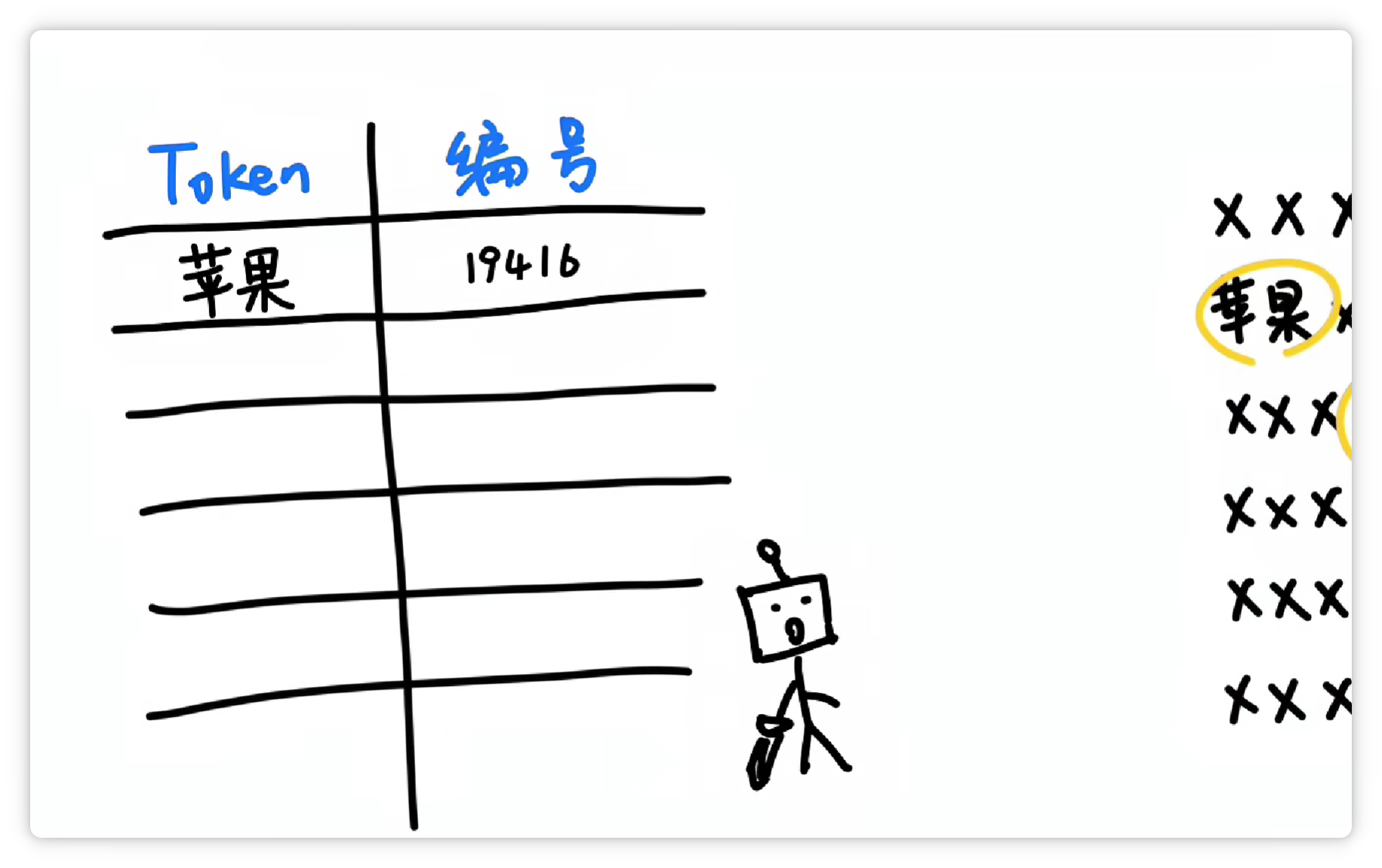
就把它們打包成一個 Token,給它一個數(shù)字編號,比如 19416。
然后丟到一個大的詞匯表里。
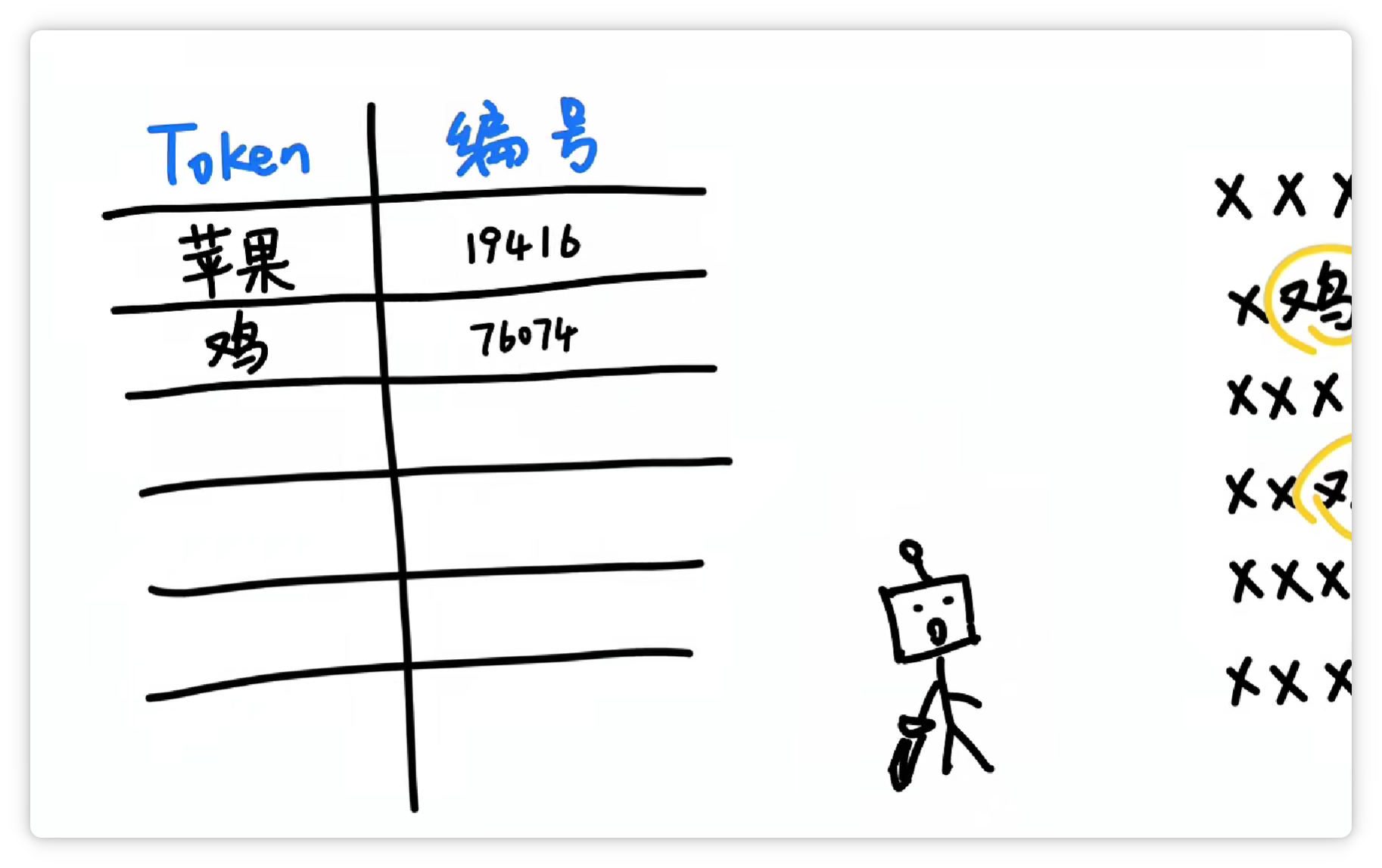
這樣下次再看到 “蘋果” 這兩個字的時候,就可以直接認出這個組合就可以了。 然后它可能又發(fā)現(xiàn) “雞” 這個字經(jīng)常出現(xiàn),并且可以搭配不同的其他字。
于是它就把 “雞” 這個字,打包成一個 Token,給它配一個數(shù)字編號,比如 76074。
并且丟到詞匯表里。
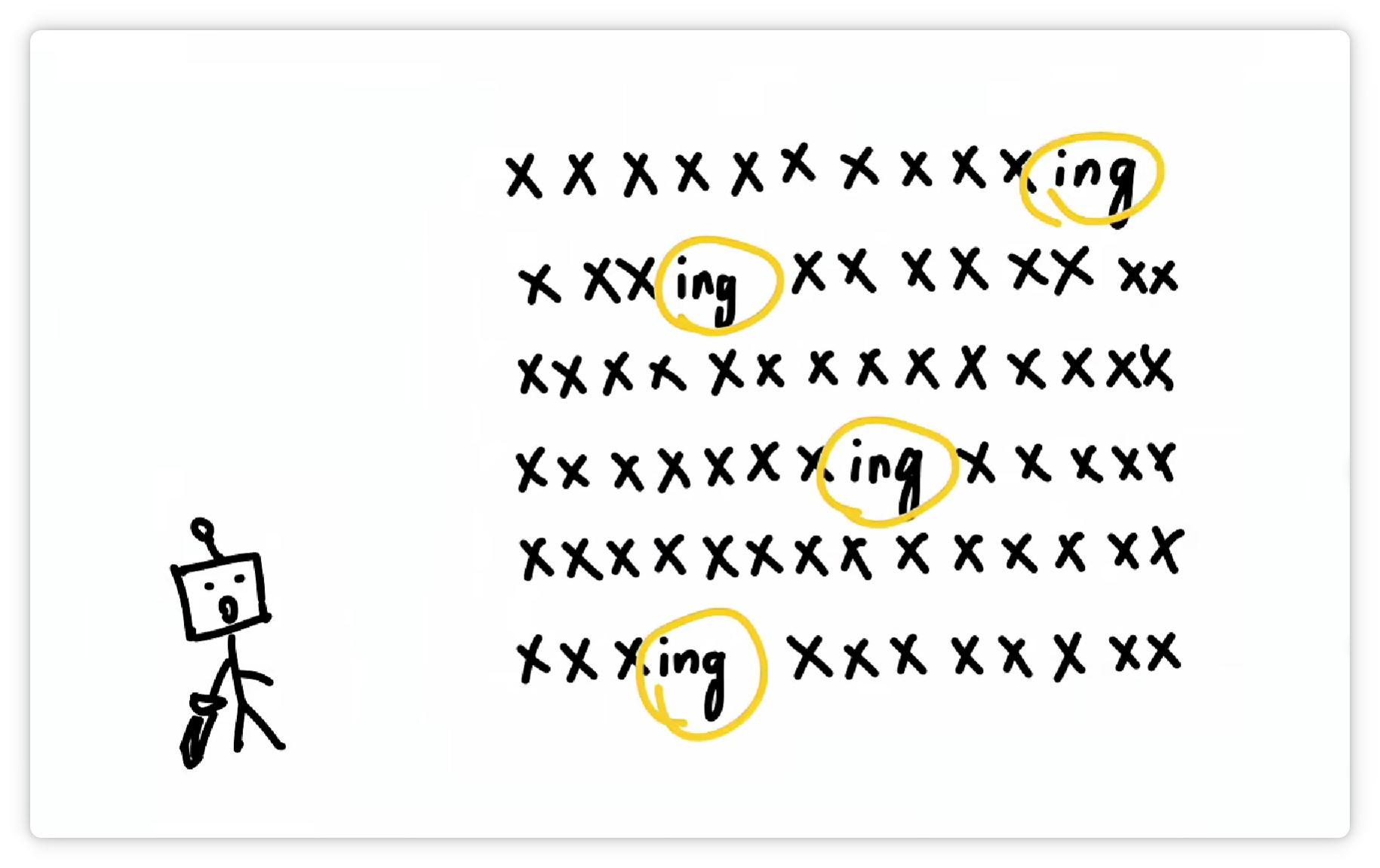
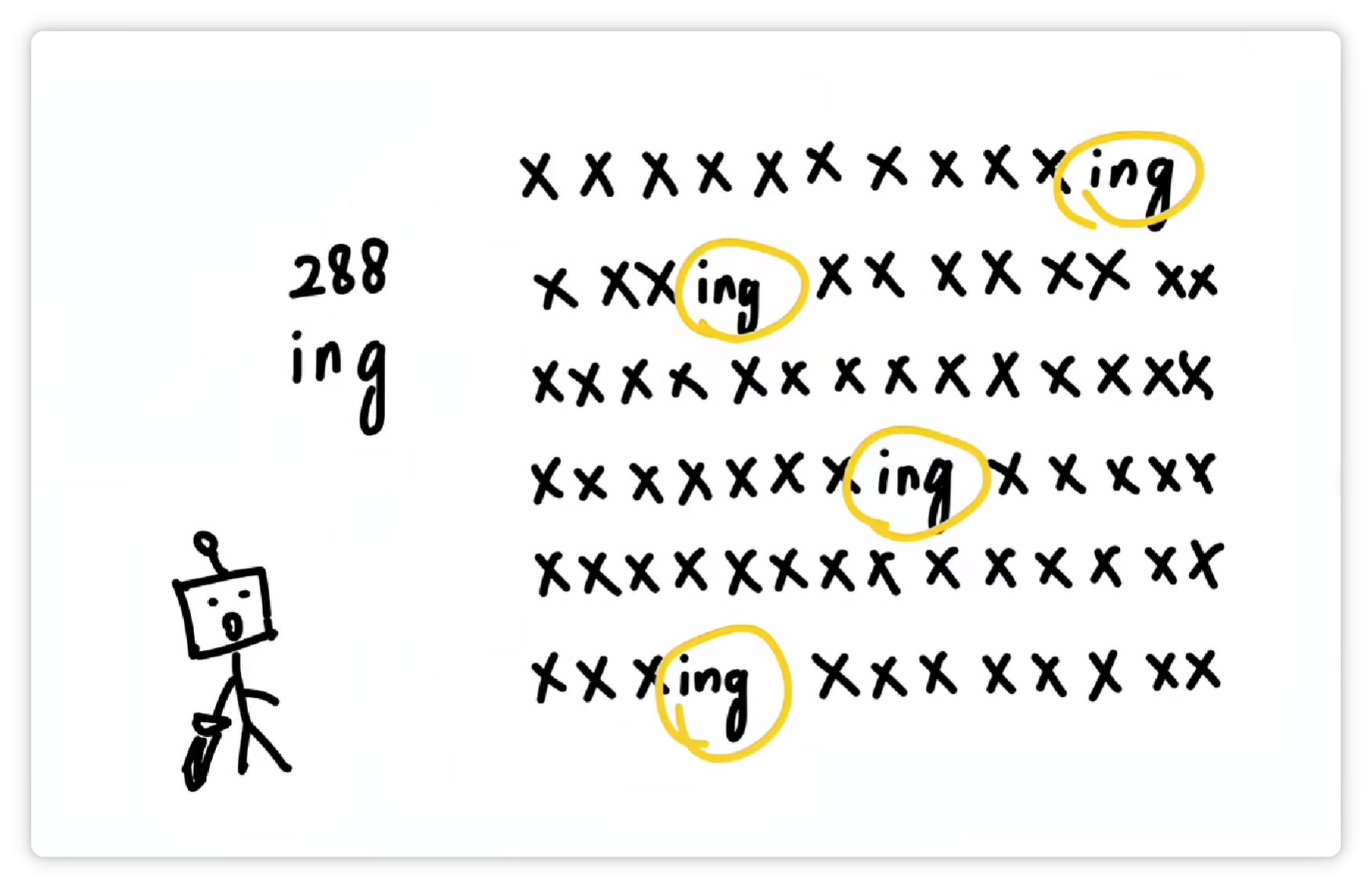
它又發(fā)現(xiàn) “ing” 這三個字母經(jīng)常一起出現(xiàn)。
于是又把 “ing” 這三個字母打包成一個 Token,給它配一個數(shù)字編號,比如 288。
并且收錄到詞匯表里。
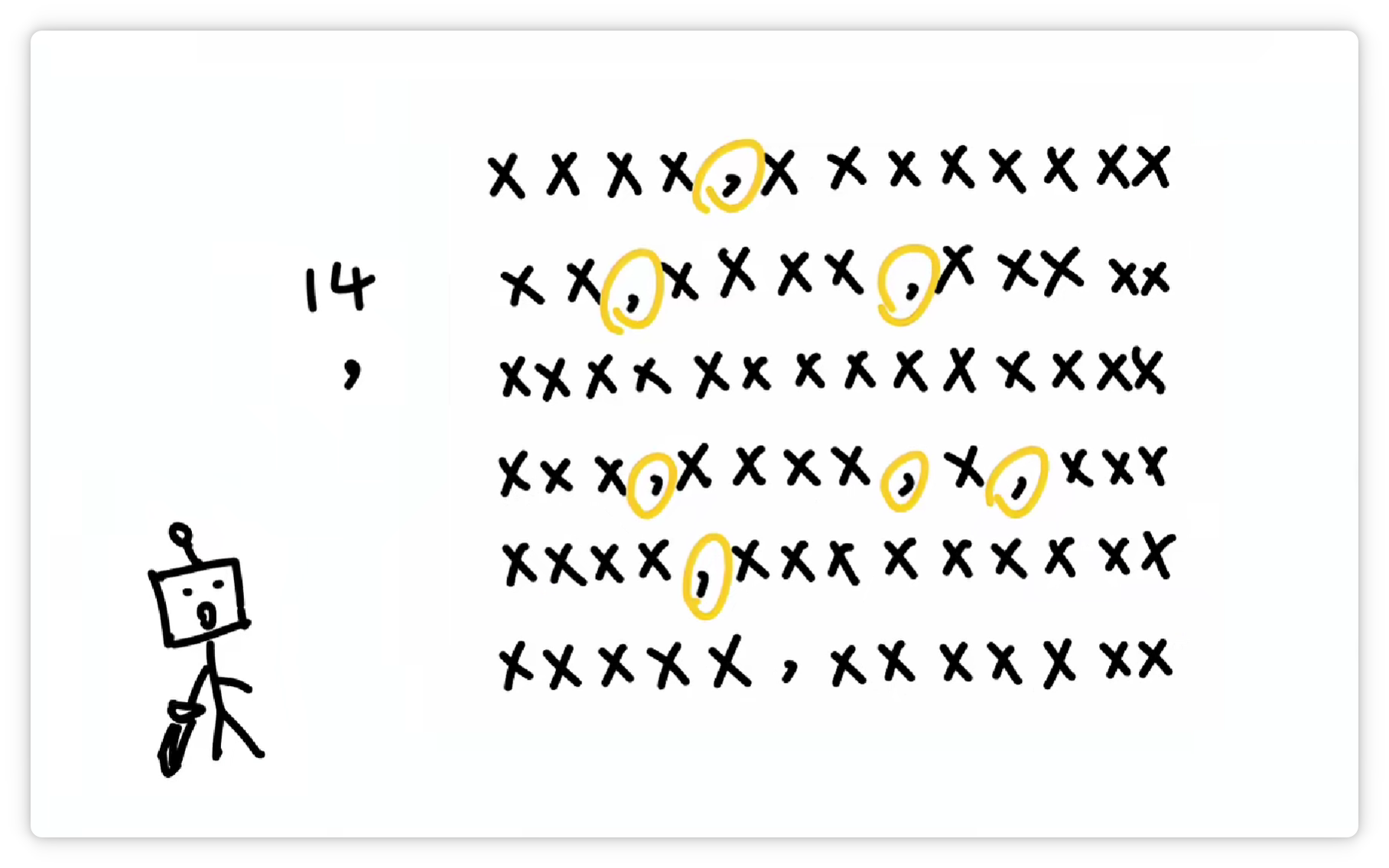
它又發(fā)現(xiàn) “逗號” 經(jīng)常出現(xiàn)。
于是又把 “逗號” 也打包作為一個 Token,給它配一個數(shù)字編號,比如 14。
收錄到詞匯表里。
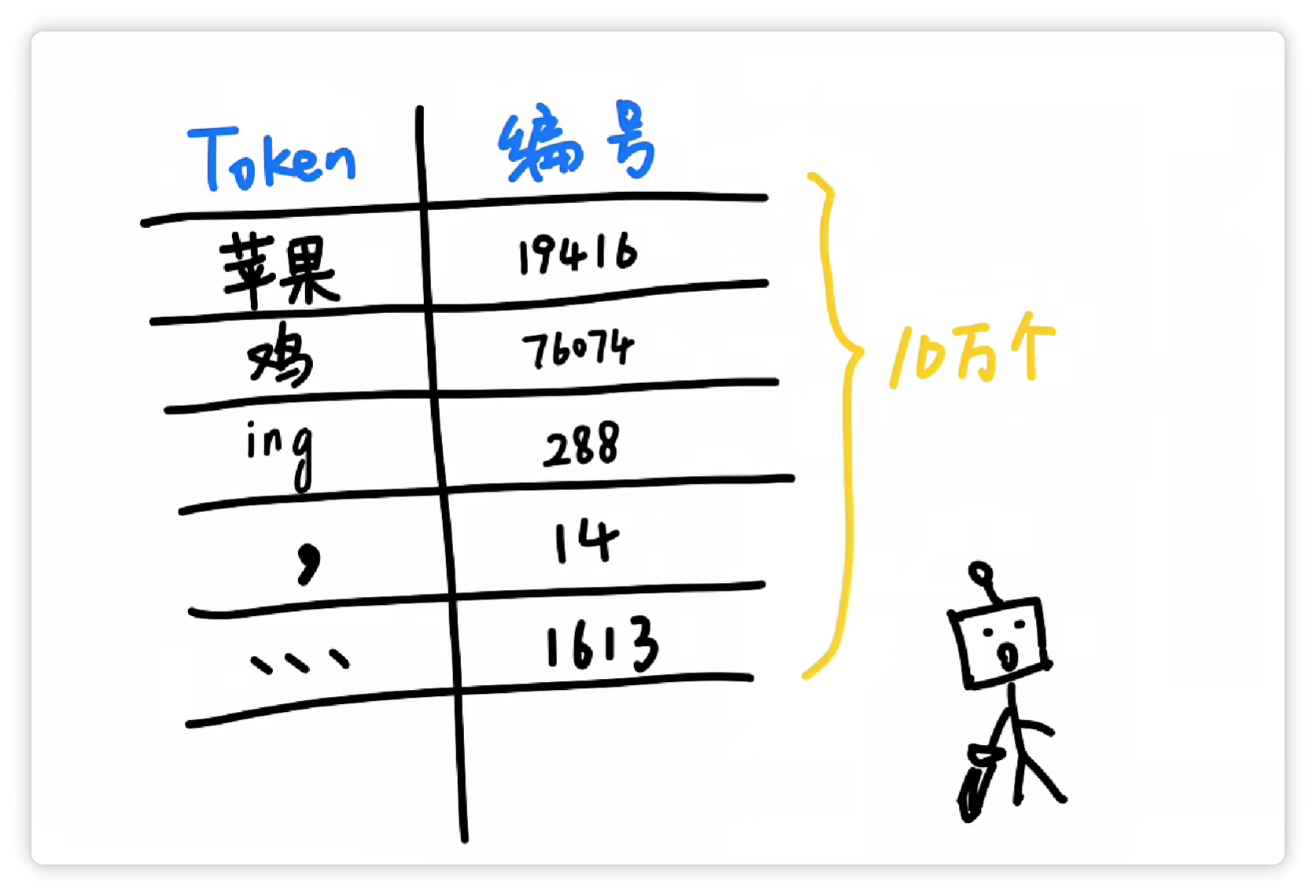
經(jīng)過大量統(tǒng)計和收集,分詞器就可以得到一個龐大的Token表。
可能有5萬個、10萬個,甚至更多Token,可以囊括我們?nèi)粘R姷降母鞣N字、詞、符號等等。
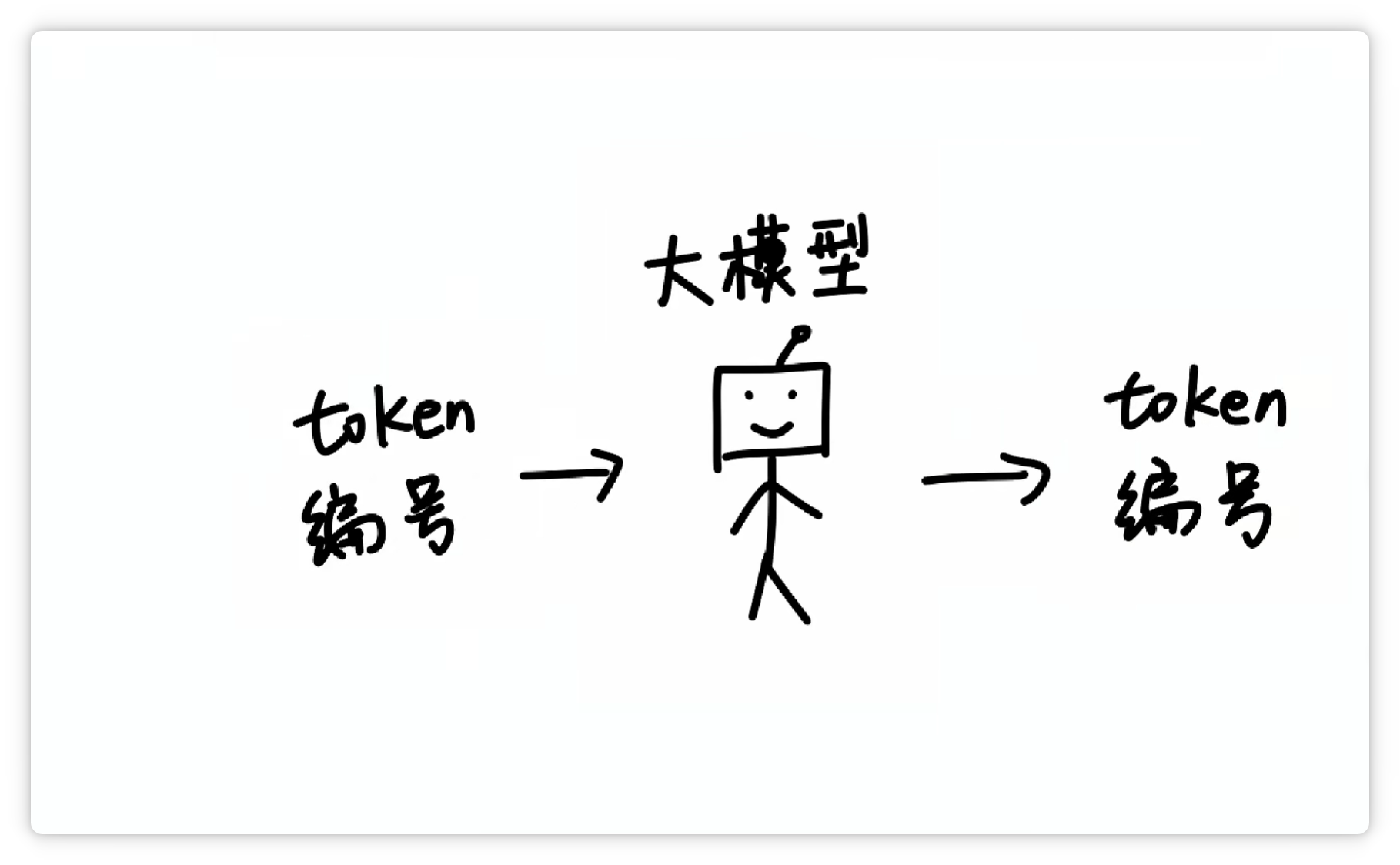
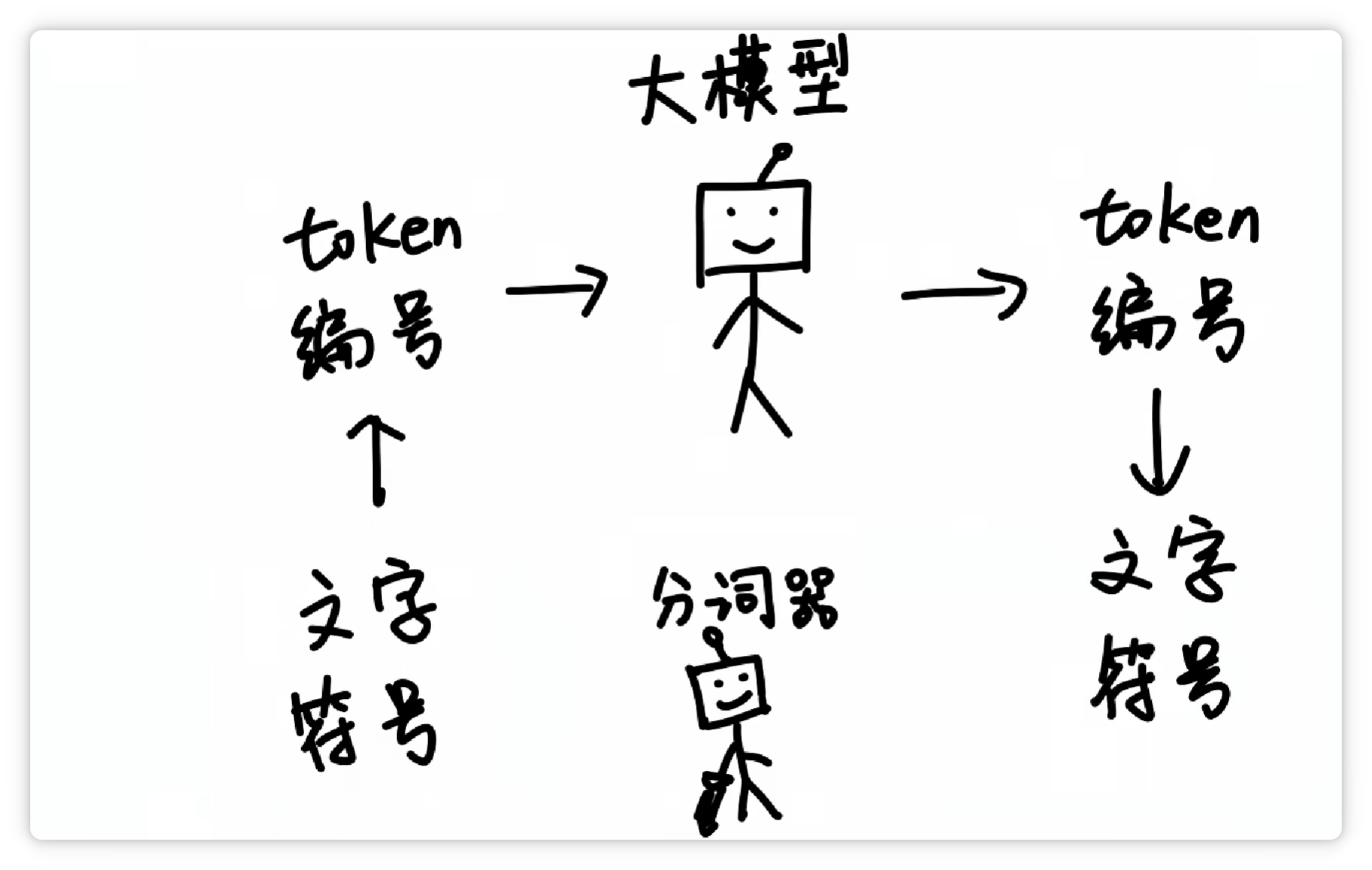
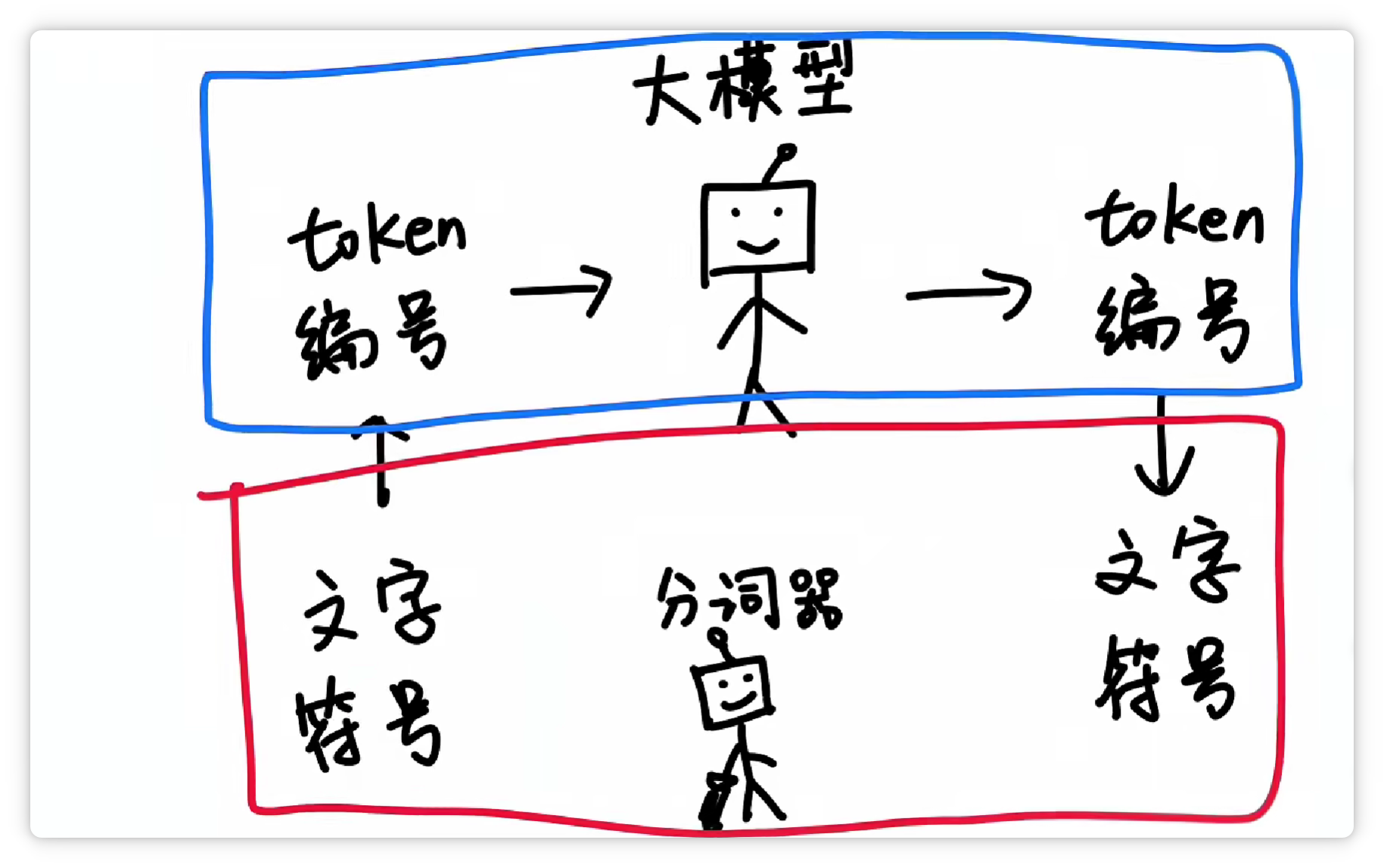
這樣一來,大模型在輸入和輸出的時候,都只需要面對一堆數(shù)字編號就可以了。
再由分詞器按照Token表,轉(zhuǎn)換成人類可以看懂的文字和符號。
這樣一分工,工作效率就非常高。
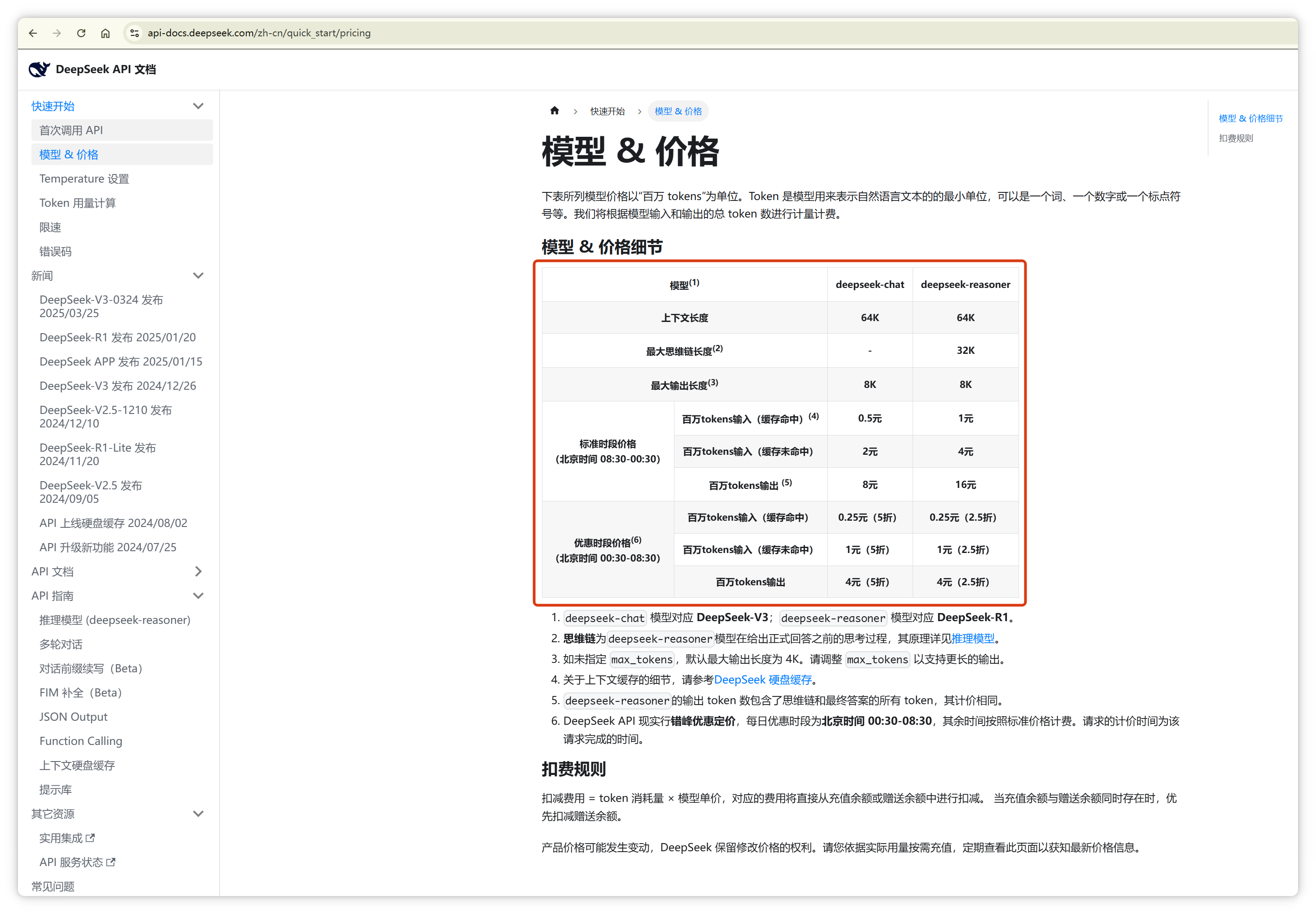
有這么一個網(wǎng)站 Tiktokenizer:https://tiktokenizer.vercel.app
輸入一段話,它就可以告訴你,這段話是由幾個Token構(gòu)成的,分別是什么,以及這幾個Token的編號分別是多少。
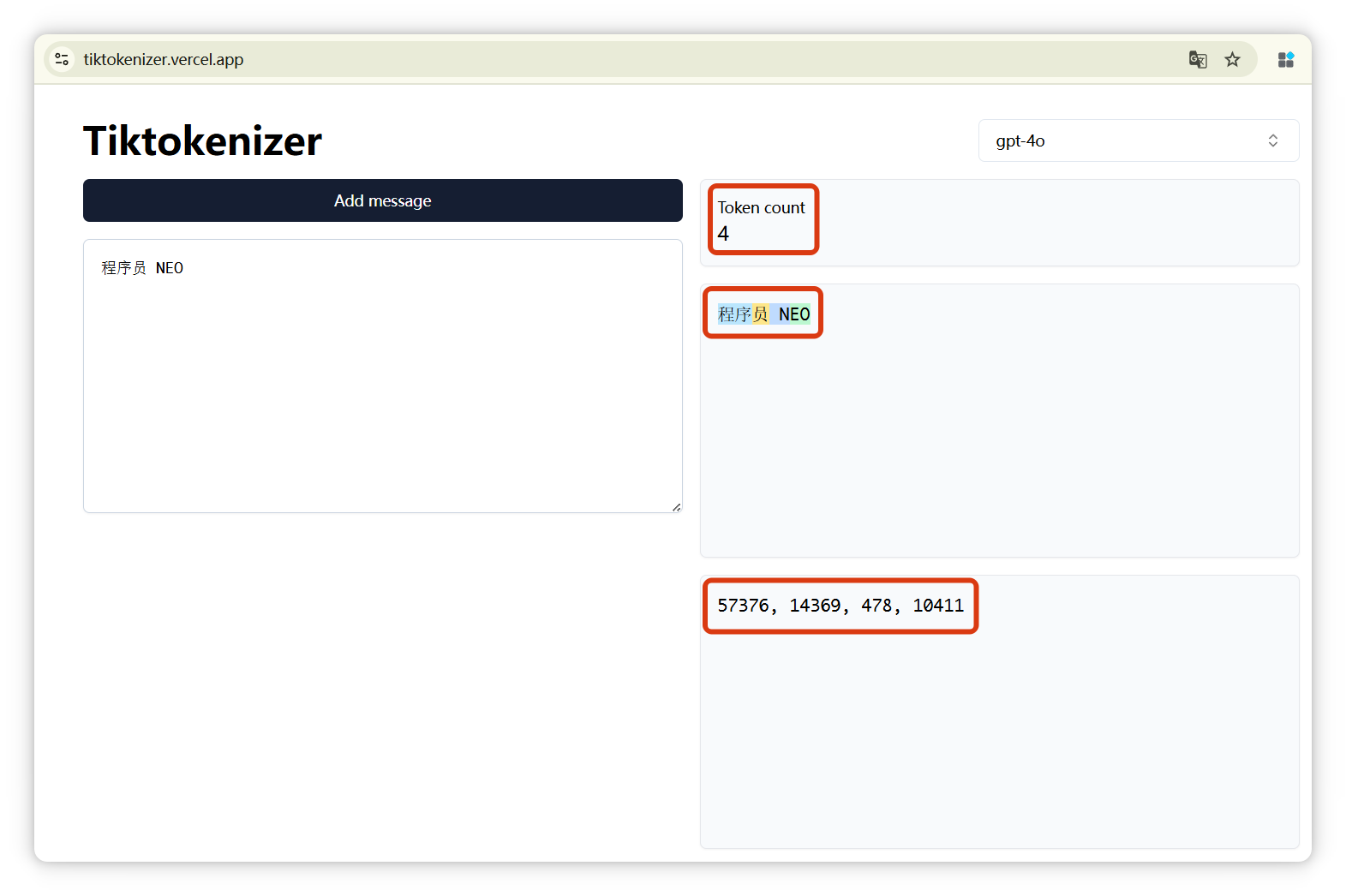
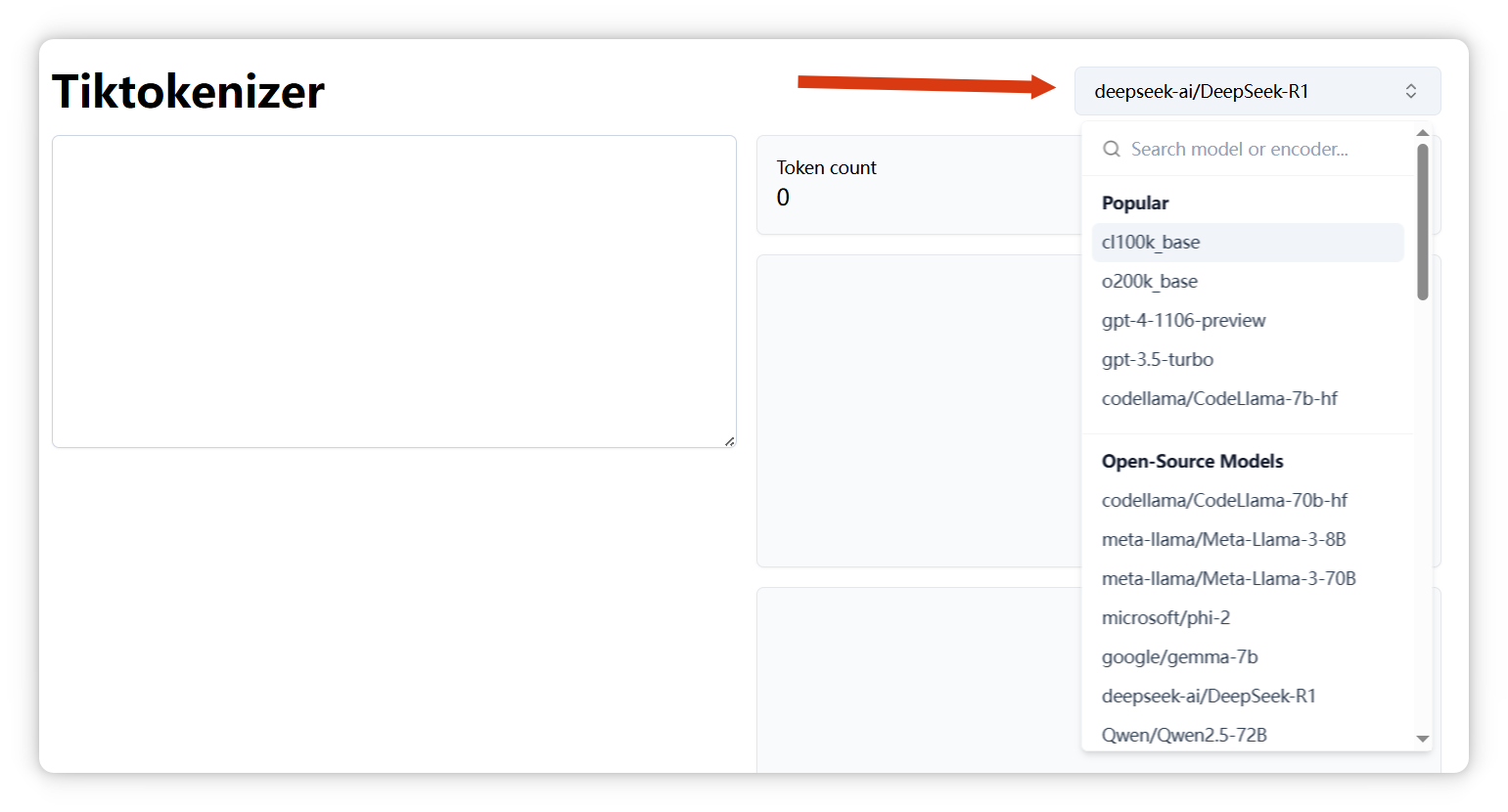
我來演示一下,這個網(wǎng)站有很多模型可以選擇,像 GPT-4o、DeepSeek、LLaMA 等等。
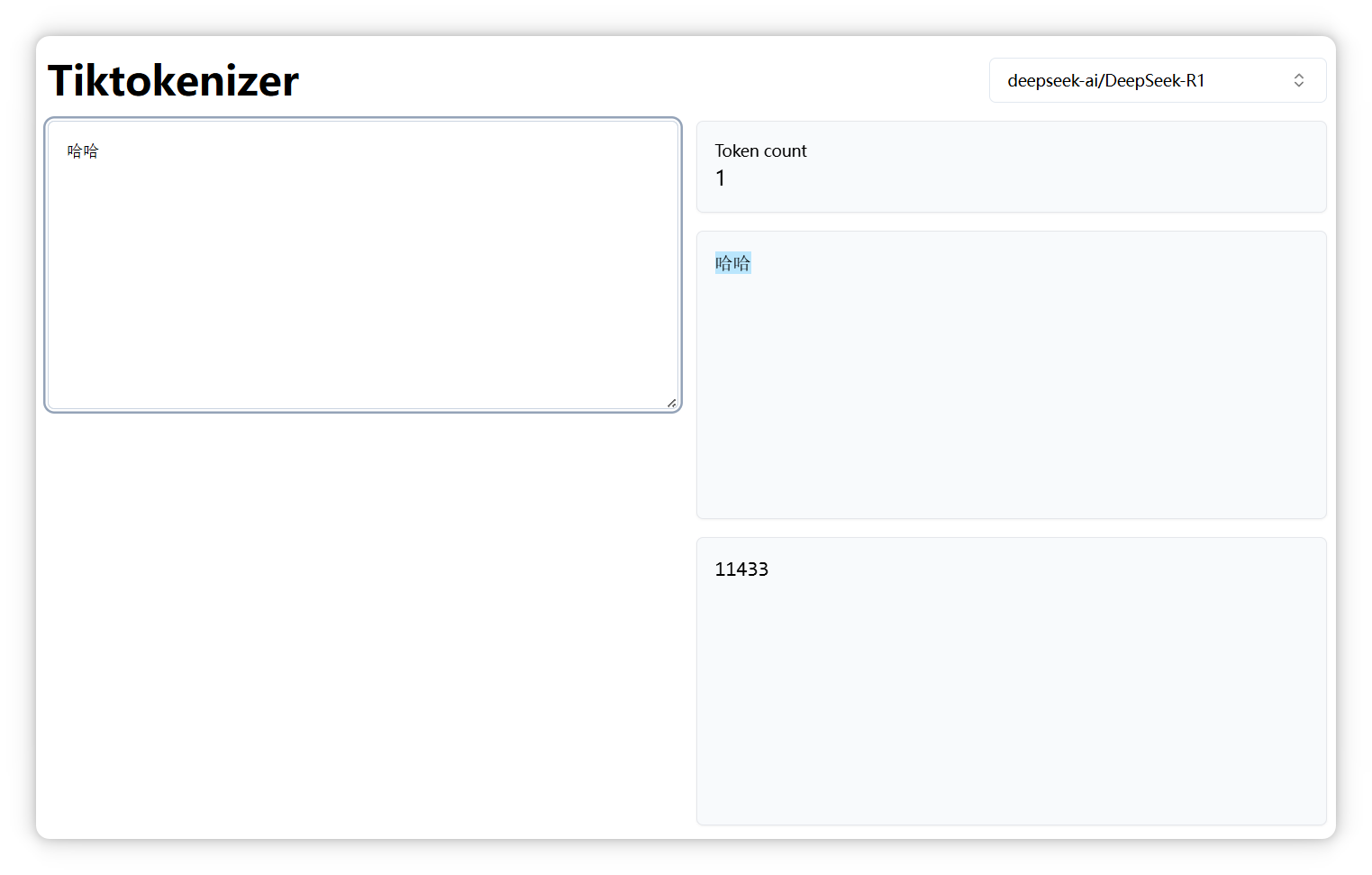
我選的是 DeepSeek,我輸入 “哈哈”,顯示是一個 Token,編號是 11433:
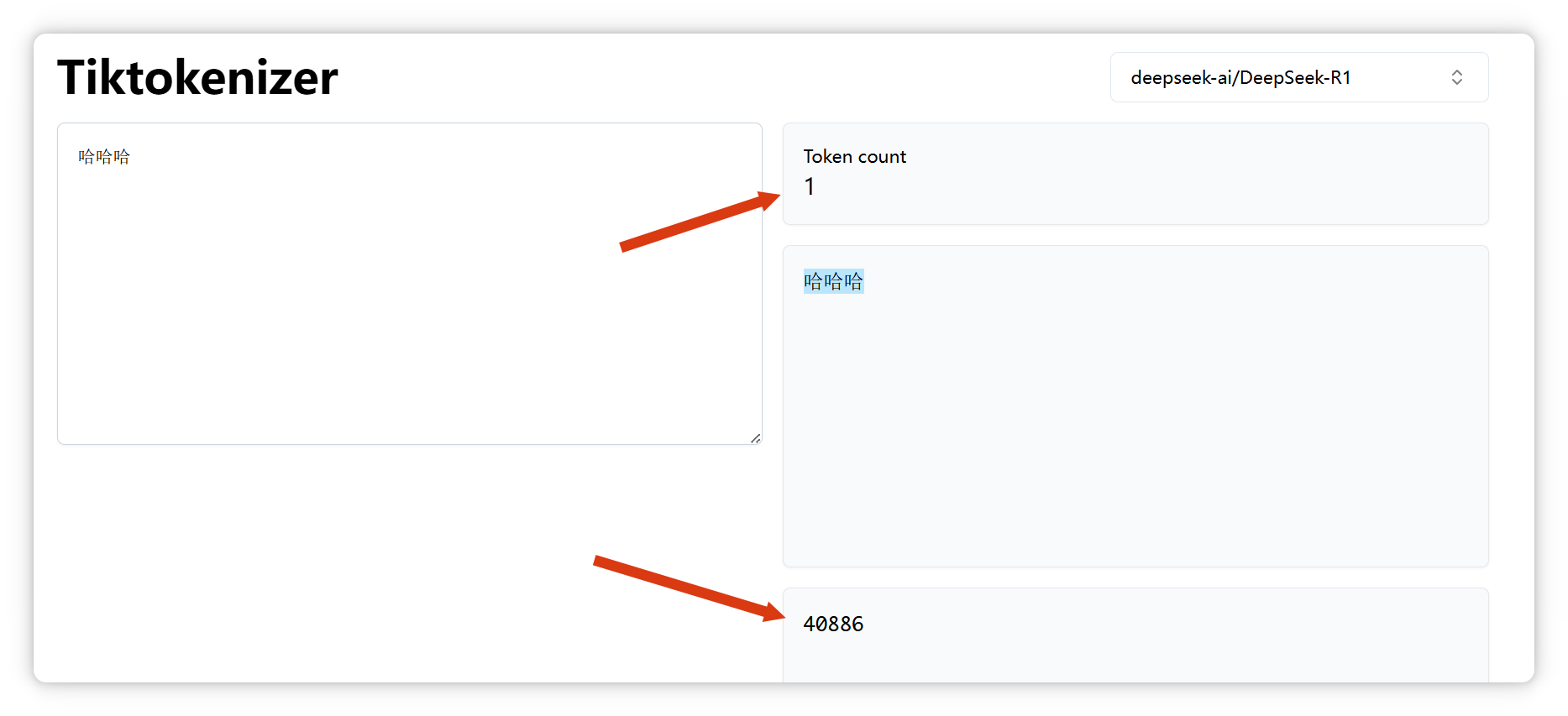
“哈哈哈”,也是一個 Token,編號是 40886:
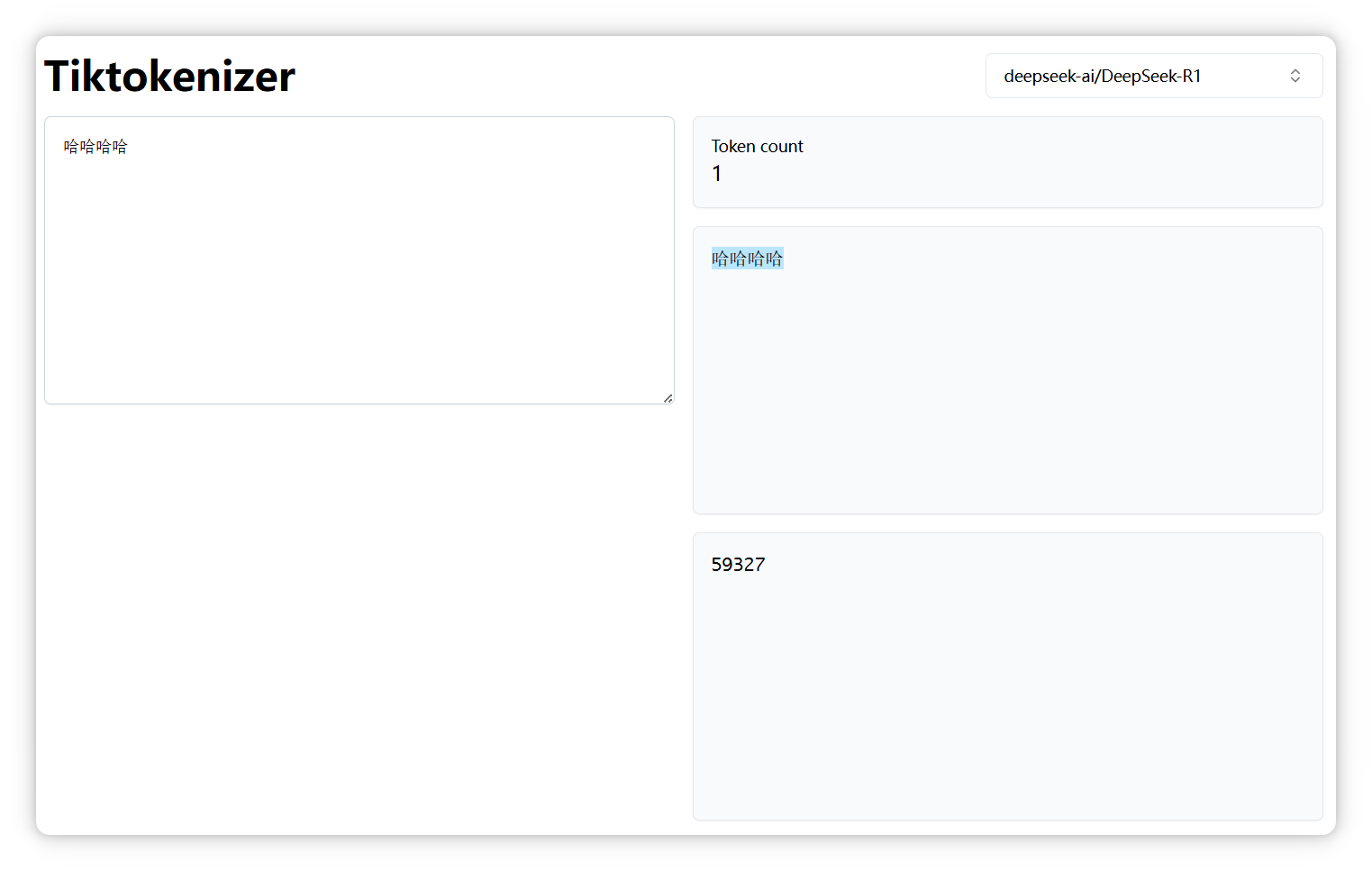
4個 “哈”,還是一個 Token,編號是 59327:
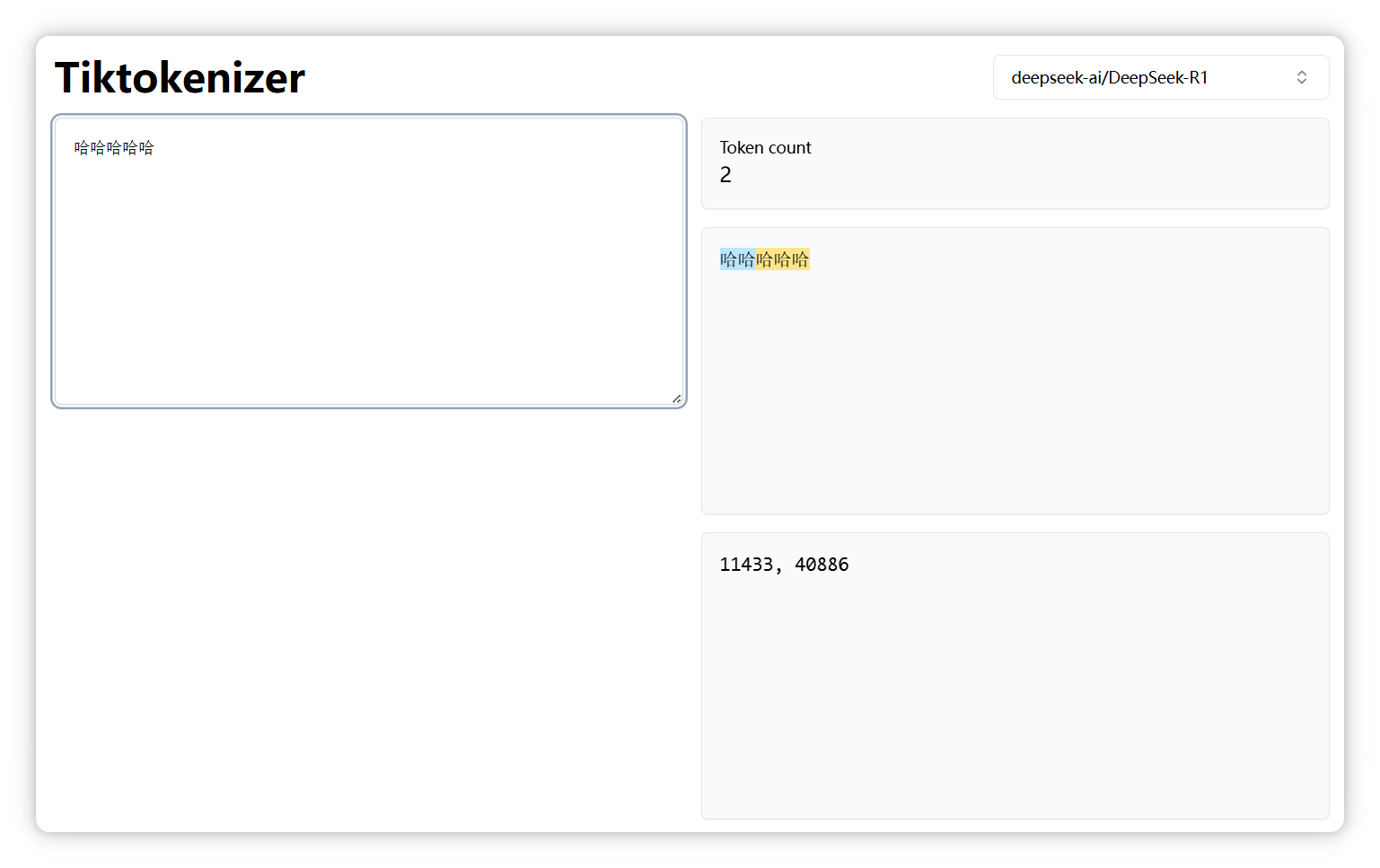
但是5個 “哈”,就變成了兩個Token,編號分別是 11433, 40886:
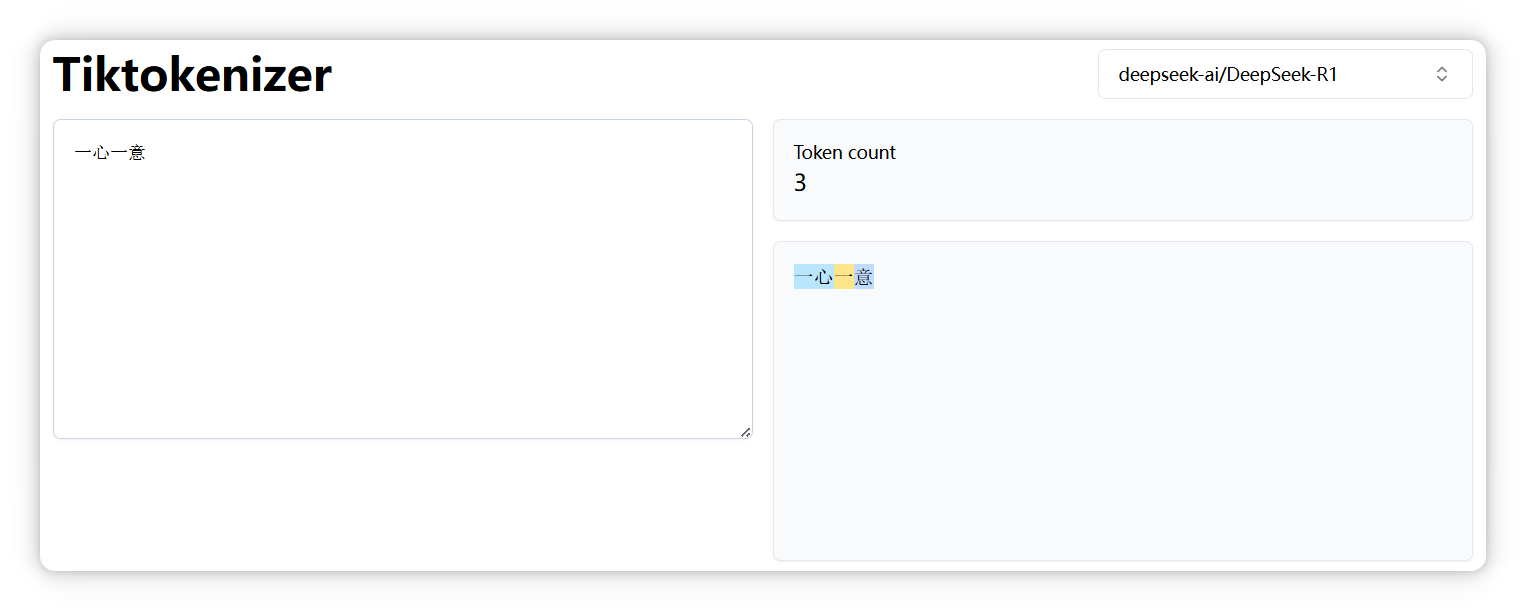
說明大家平常用兩個 “哈” 或者三個的更多。 再來,“一心一意” 是三個 Token。
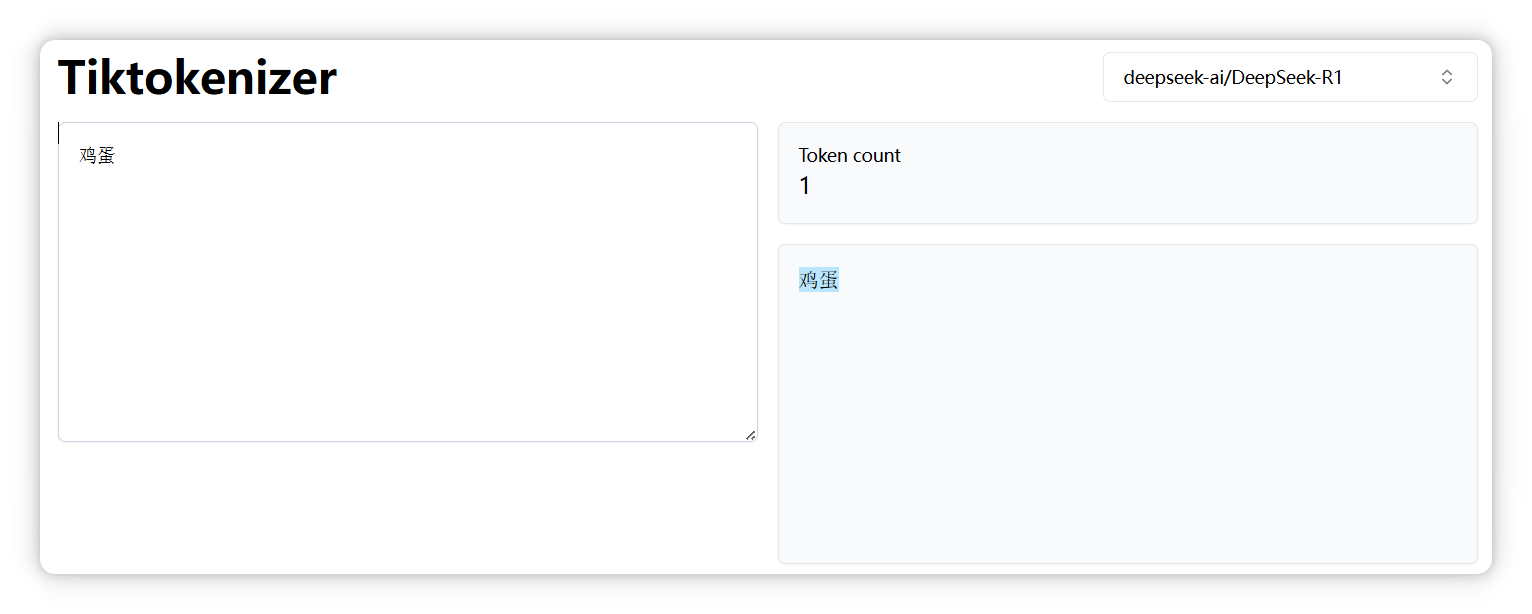
“雞蛋” 是一個 Token。
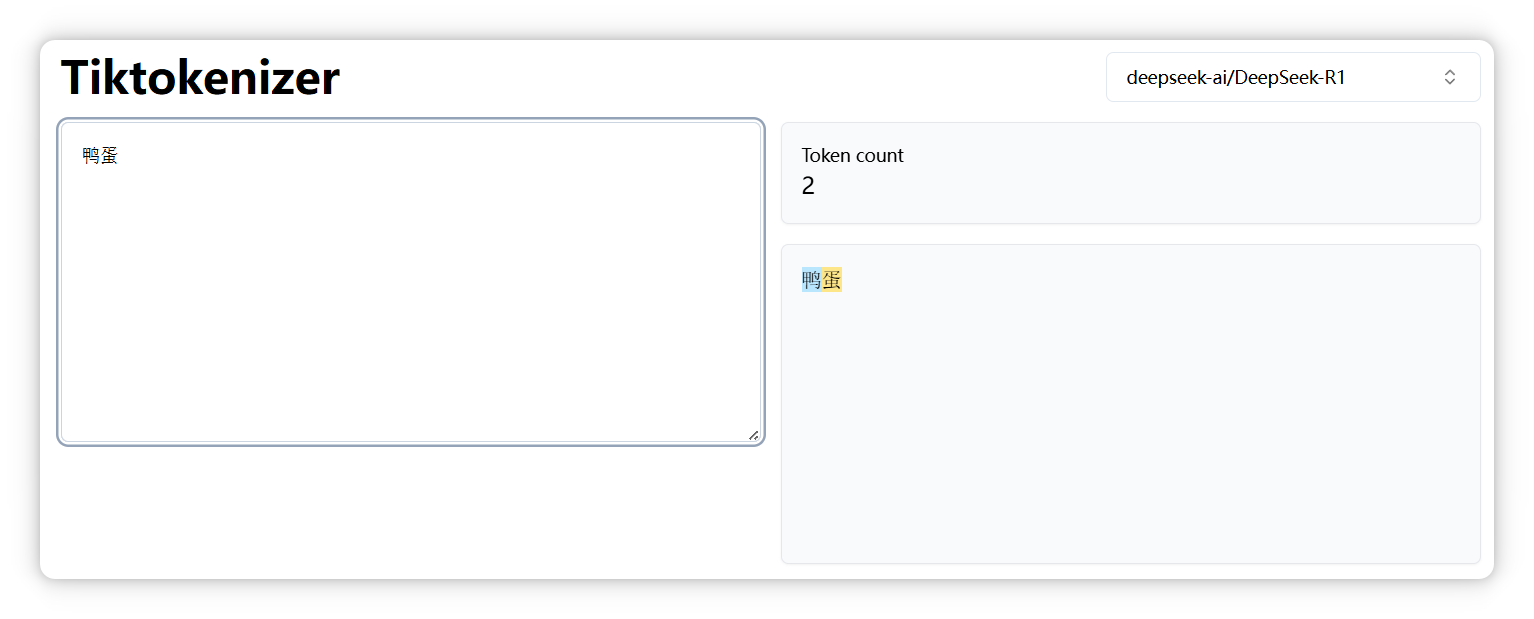
但是 “鴨蛋” 是兩個 Token。
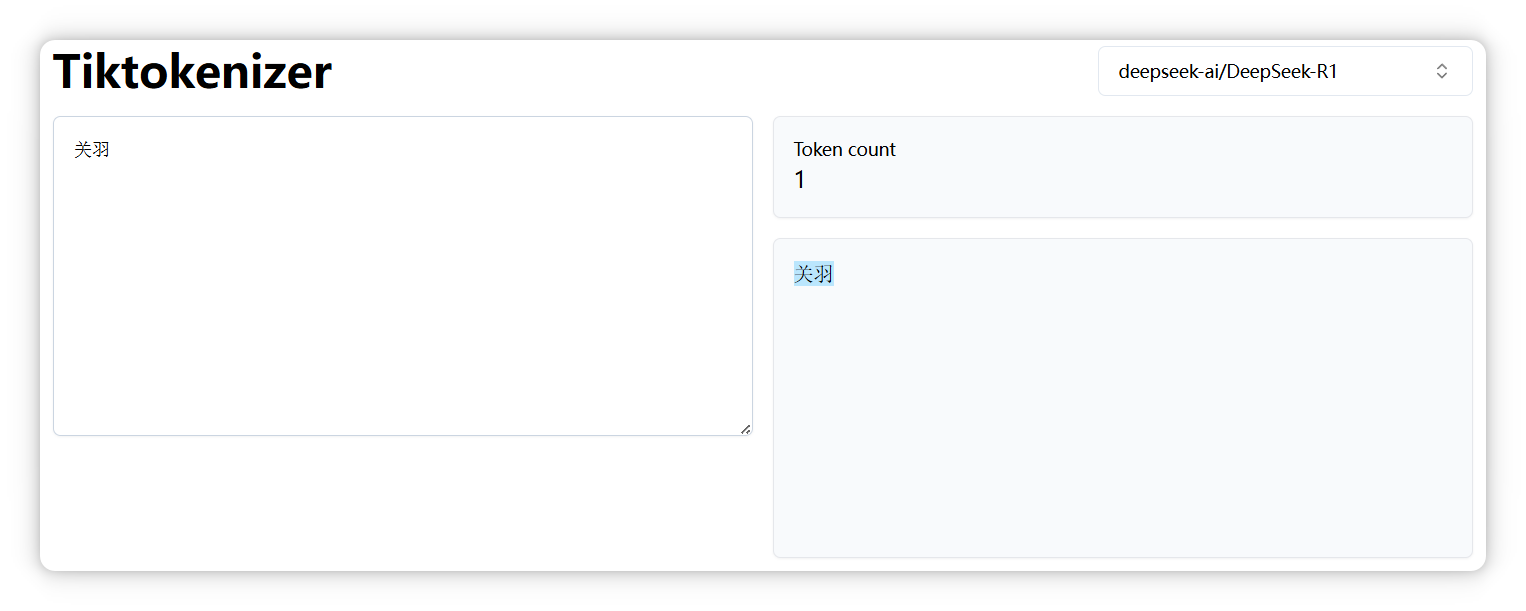
“關(guān)羽” 是一個 Token。
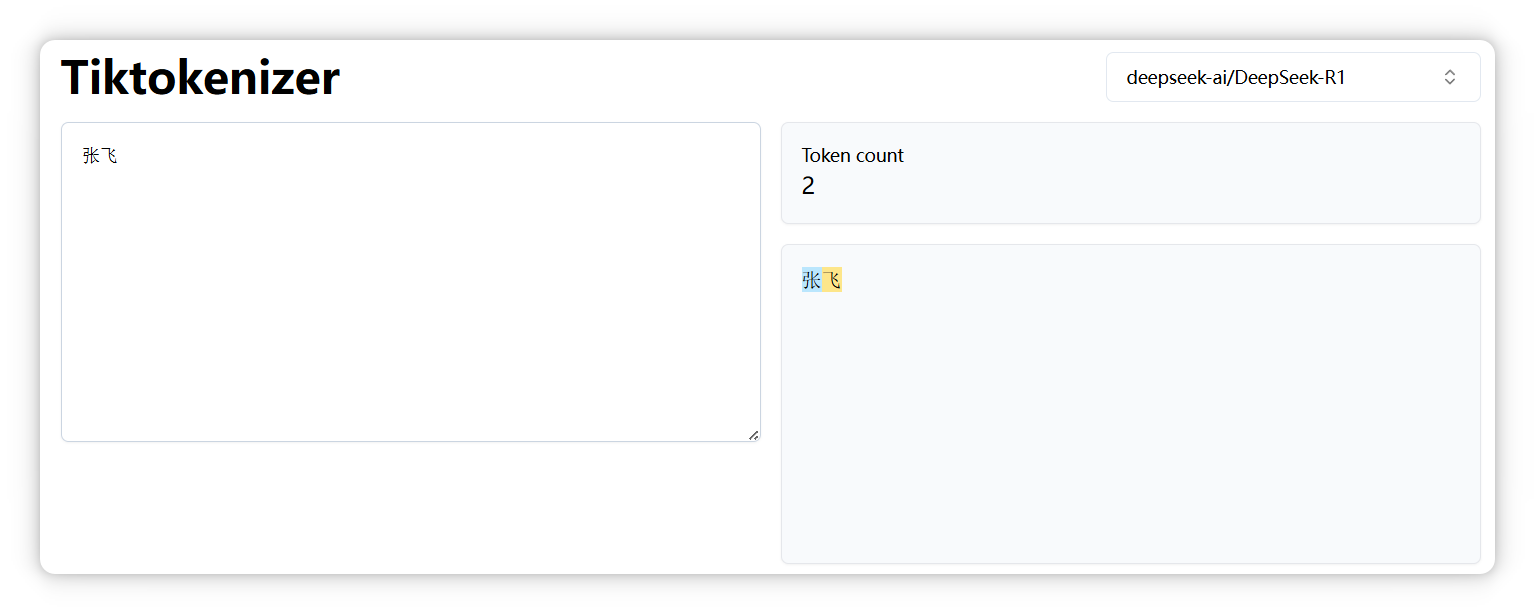
“張飛” 是兩個 Token。
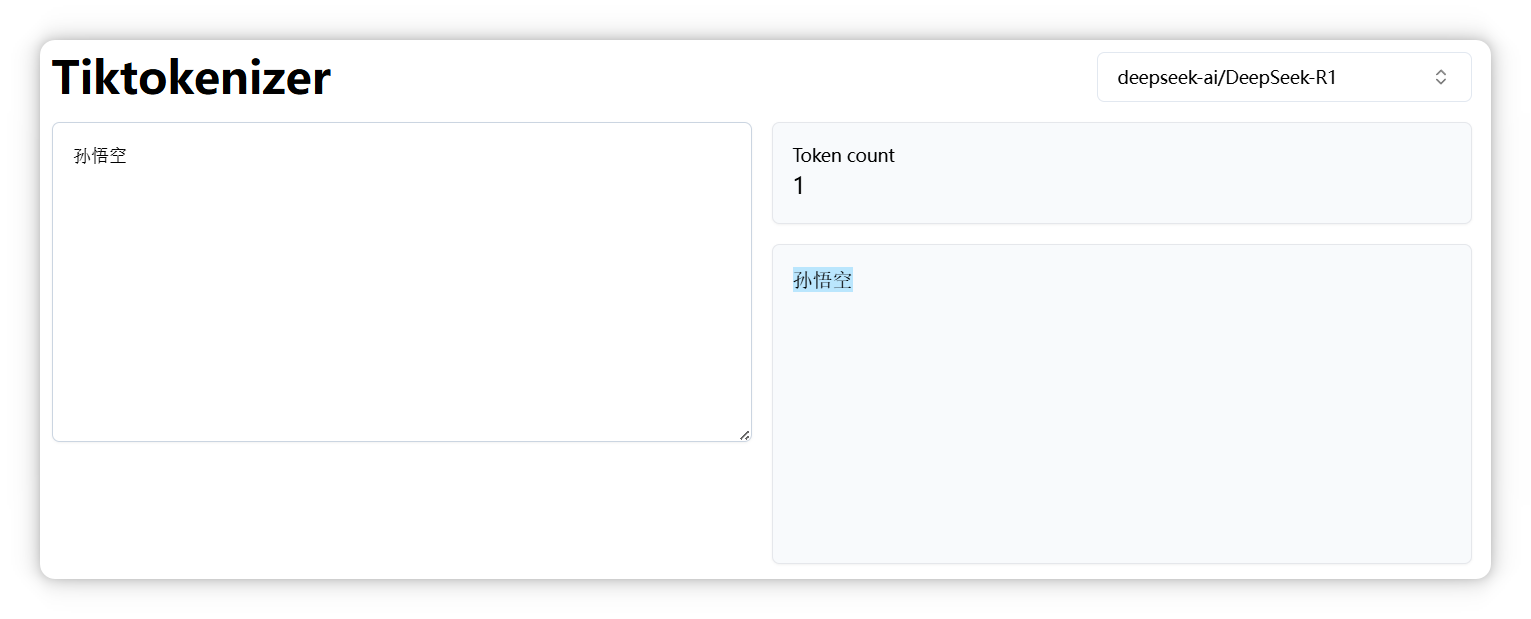
“孫悟空” 是一個 Token。
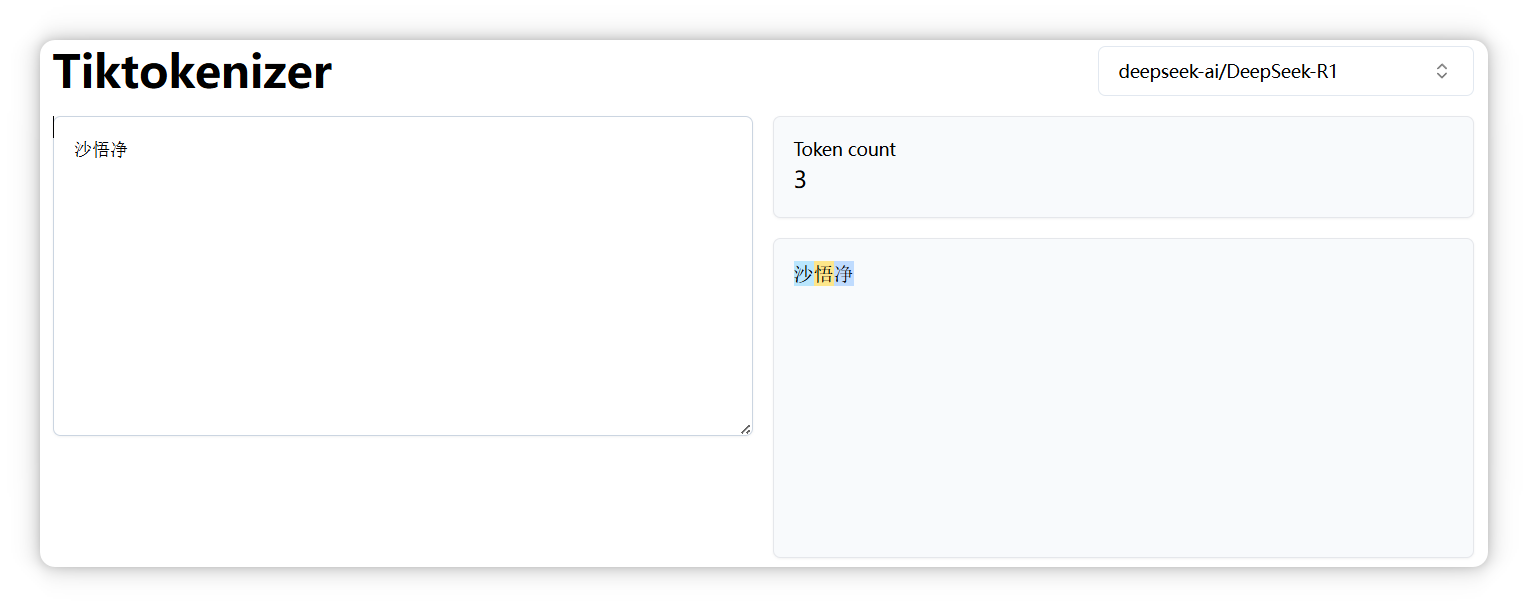
“沙悟凈” 是三個 Token。
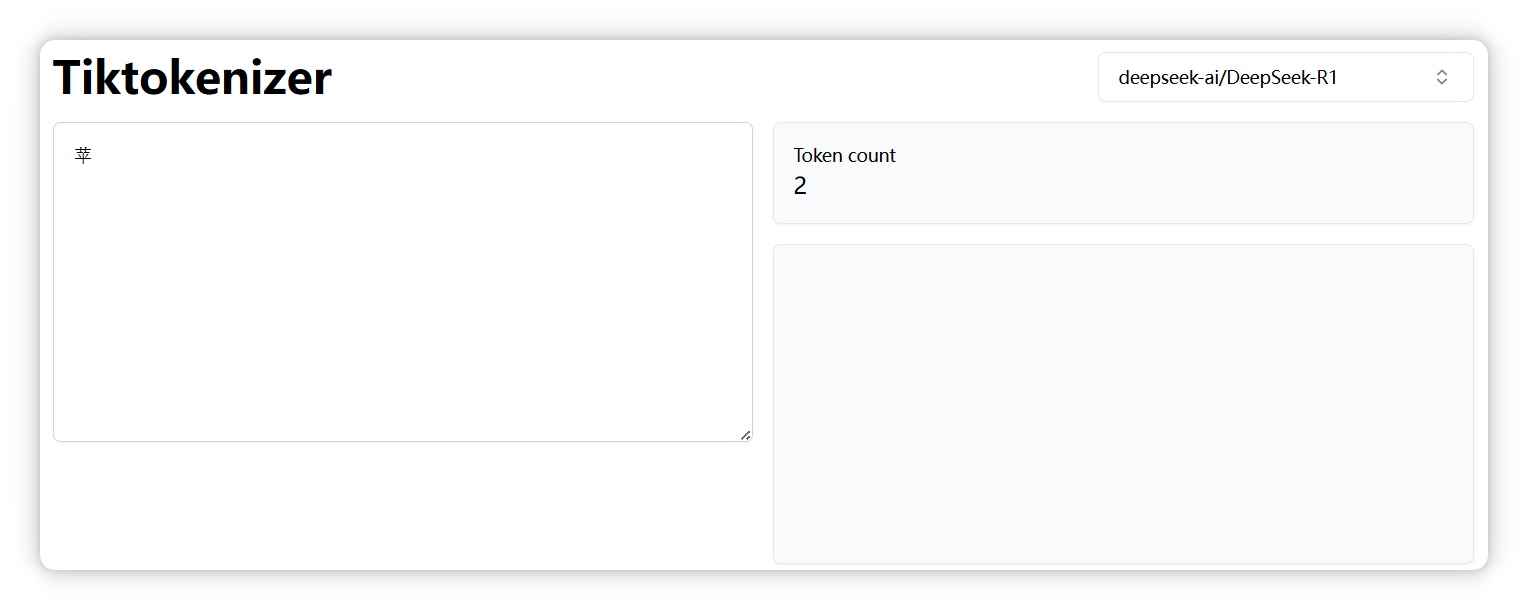
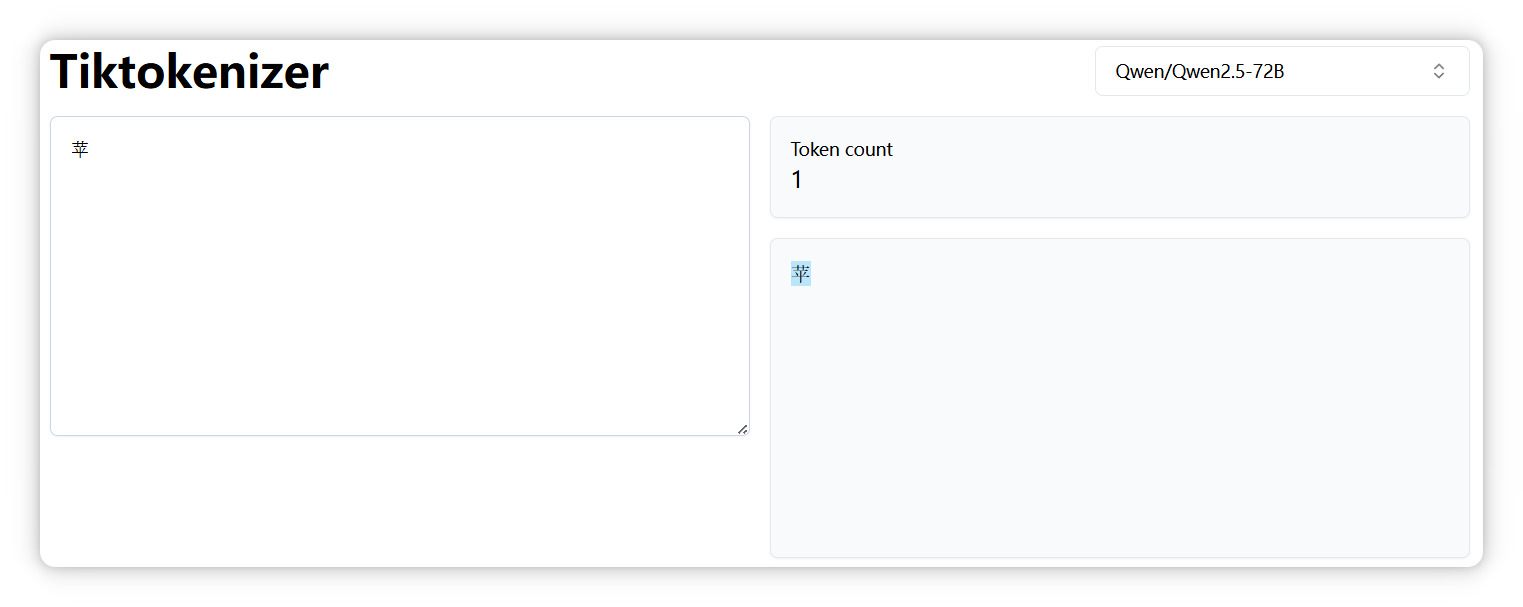
另外,正如前面提到的,不同模型的分詞器可能會有不同的切分結(jié)果。比如,“蘋果” 中的 “蘋” 字,在 DeepSeek 中被拆分成兩個 Token。
但是在
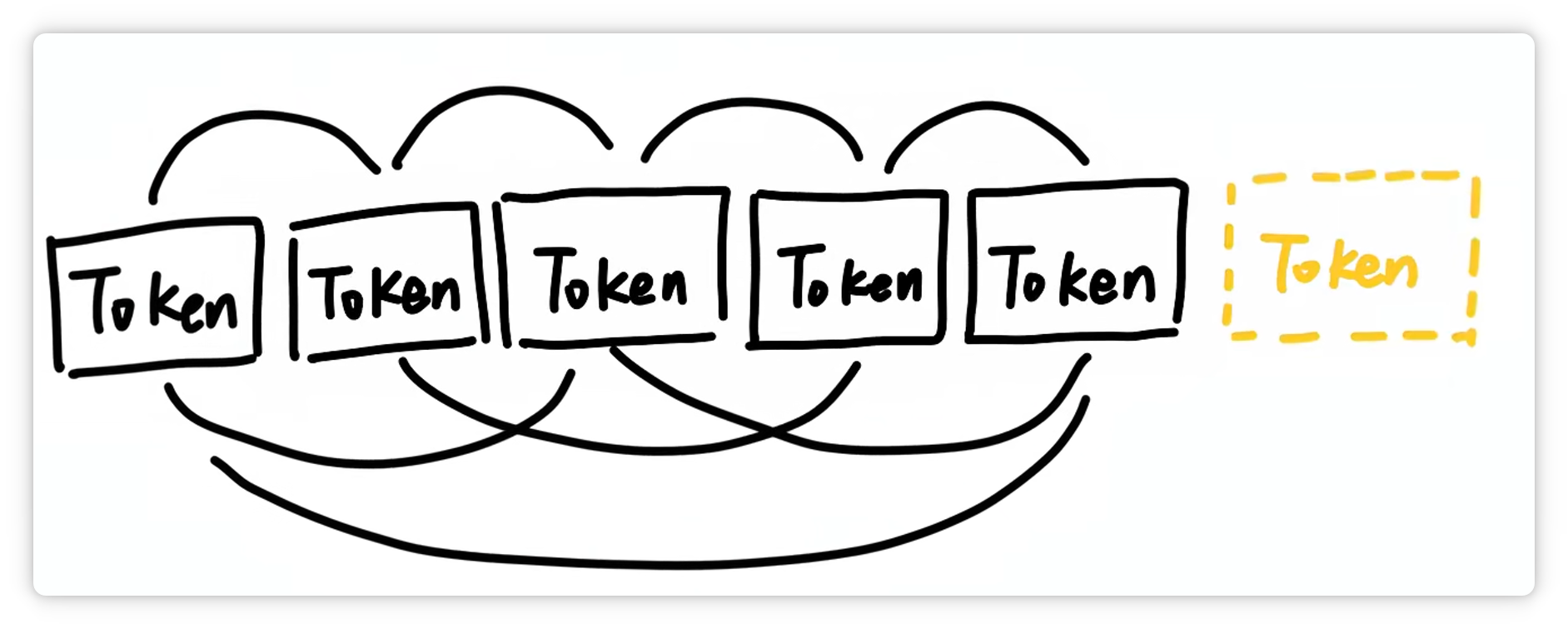
所以回過頭來看,Token 到底是什么? 它就是構(gòu)建大模型世界的一塊塊積木。
大模型之所以能理解和生成文本,就是通過計算這些 Token 之間的關(guān)系,來預(yù)測下一個最可能出現(xiàn)的 Token。
這就是為什么幾乎所有大模型公司都按照 Token 數(shù)量計費,因為 Token 數(shù)量直接對應(yīng)背后的計算成本。
“Token” 這個詞不僅用于人工智能領(lǐng)域,在其他領(lǐng)域也經(jīng)常出現(xiàn)。其實,它們只是恰好都叫這個名字而已。 就像同樣都是 “車模”,汽車模型和車展模特,雖然用詞相同,但含義卻截然不同。
FAQ1. 蘋為啥會是2個?因為“蘋” 字單獨出現(xiàn)的概率太低,無法獨立成為一個 Token。 2. 為什么張飛算兩個 Token?“張” 和 “飛” 一起出現(xiàn)的頻率不夠高,或者“ 張” 字和 “飛” 字的搭配不夠穩(wěn)定,經(jīng)常與其他字組合,因此被拆分為兩個 Token。 Token 在大模型方面最好的翻譯是 '詞元' 非常的信雅達。 轉(zhuǎn)自https://www.cnblogs.com/BNTang/p/18803486 ?該文章在 2025/4/7 8:54:46 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
")