數據庫的最簡單實現
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
原文出處: 阮一峰的博客(@ruanyf)
所有應用軟件之中,數據庫可能是最復雜的。 MySQL的手冊有3000多頁,PostgreSQL的手冊有2000多頁,Oracle的手冊更是比它們相加還要厚。
但是,自己寫一個最簡單的數據庫,做起來并不難。Reddit上面有一個帖子,只用了幾百個字,就把原理講清楚了。下面是我根據這個帖子整理的內容。 一、數據以文本形式保存第一步,就是將所要保存的數據,寫入文本文件。這個文本文件就是你的數據庫。 為了方便讀取,數據必須分成記錄,每一條記錄的長度規定為等長。比如,假定每條記錄的長度是800字節,那么第5條記錄的開始位置就在3200字節。 大多數時候,我們不知道某一條記錄在第幾個位置,只知道主鍵(primary key)的值。這時為了讀取數據,可以一條條比對記錄。但是這樣做效率太低,實際應用中,數據庫往往采用B樹(B-tree)格式儲存數據。 二、什么是B樹?要理解B樹,必須從二叉查找樹(Binary search tree)講起。
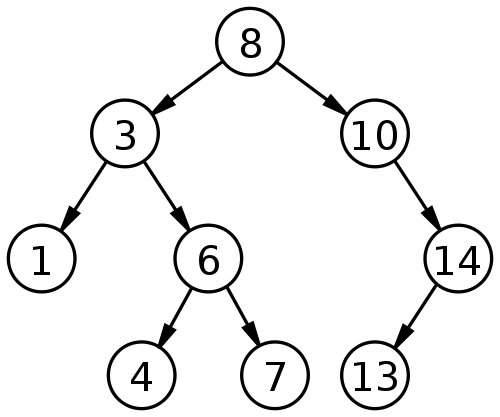
二叉查找樹是一種查找效率非常高的數據結構,它有三個特點。
二叉查找樹的結構不適合數據庫,因為它的查找效率與層數相關。越處在下層的數據,就需要越多次比較。極端情況下,n個數據需要n次比較才能找到目標值。對于數據庫來說,每進入一層,就要從硬盤讀取一次數據,這非常致命,因為硬盤的讀取時間遠遠大于數據處理時間,數據庫讀取硬盤的次數越少越好。 B樹是對二叉查找樹的改進。它的設計思想是,將相關數據盡量集中在一起,以便一次讀取多個數據,減少硬盤操作次數。
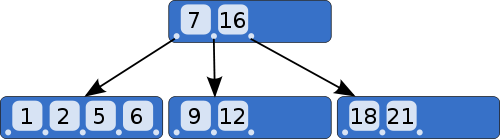
B樹的特點也有三個。
這種數據結構,非常有利于減少讀取硬盤的次數。假定一個節點可以容納100個值,那么3層的B樹可以容納100萬個數據,如果換成二叉查找樹,則需要20層!假定操作系統一次讀取一個節點,并且根節點保留在內存中,那么B樹在100萬個數據中查找目標值,只需要讀取兩次硬盤。 三、索引數據庫以B樹格式儲存,只解決了按照”主鍵”查找數據的問題。如果想查找其他字段,就需要建立索引(index)。 所謂索引,就是以某個字段為關鍵字的B樹文件。假定有一張”雇員表”,包含了員工號(主鍵)和姓名兩個字段。可以對姓名建立索引文件,該文件以B樹格式對姓名進行儲存,每個姓名后面是其在數據庫中的位置(即第幾條記錄)。查找姓名的時候,先從索引中找到對應第幾條記錄,然后再從表格中讀取。 這種索引查找方法,叫做“索引順序存取方法”(Indexed Sequential Access Method),縮寫為ISAM。它已經有多種實現(比如C-ISAM庫和D-ISAM庫),只要使用這些代碼庫,就能自己寫一個最簡單的數據庫。 四、高級功能部署了最基本的數據存取(包括索引)以后,還可以實現一些高級功能。 (1)SQL語言是數據庫通用操作語言,所以需要一個SQL解析器,將SQL命令解析為對應的ISAM操作。 (2)數據庫連接(join)是指數據庫的兩張表通過”外鍵”,建立連接關系。你需要對這種操作進行優化。 (3)數據庫事務(transaction)是指批量進行一系列數據庫操作,只要有一步不成功,整個操作都不成功。所以需要有一個”操作日志”,以便失敗時對操作進行回滾。 (4)備份機制:保存數據庫的副本。 (5)遠程操作:使得用戶可以在不同的機器上,通過TCP/IP協議操作數據庫。 (完) 該文章在 2014/7/10 14:13:09 編輯過 |
關鍵字查詢
相關文章




|


 400 186 1886
400 186 1886