使用Tesseract進行圖片文字識別
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
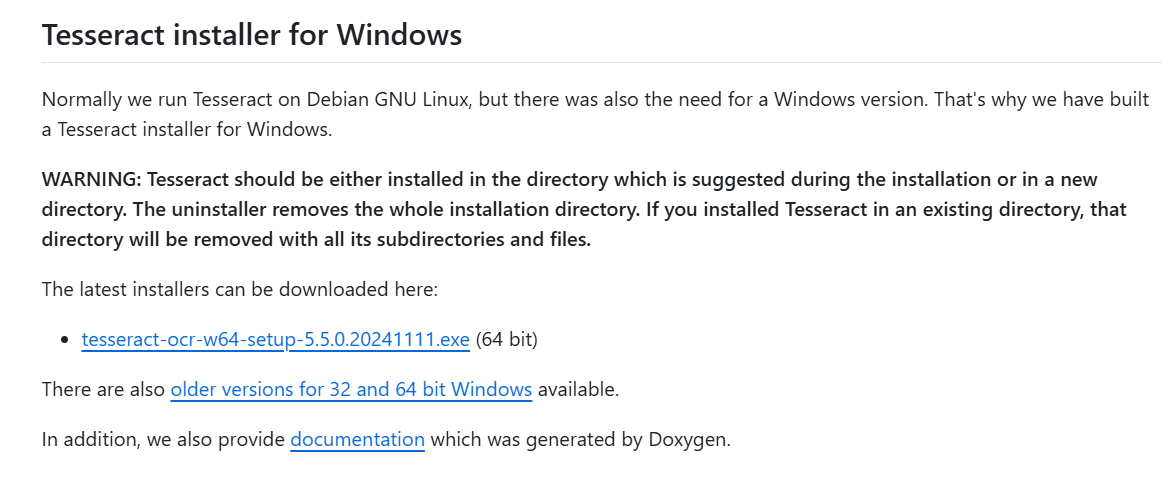
Tesseract介紹Tesseract 是一個開源的光學字符識別(OCR)引擎,最初由 HP 在 1985 年至 1995 年間開發,后來被 Google 收購并開源。Tesseract 支持多種語言的文本識別,能夠識別圖片中的文字,并將其轉換為可編輯和可搜索的數據格式。它適用于多種應用場景,包括文檔掃描、圖像處理、數字存檔等。 Tesseract 的最新版本顯著提高了識別準確率,支持的文件格式包括 TIFF、JPEG、PNG 等常見圖片格式。此外,Tesseract 還提供了一個命令行工具,允許用戶通過簡單的命令行輸入來執行 OCR 任務。對于開發者而言,Tesseract 提供了多種編程語言的 API 接口,如 C++、Python、Java 等,使得集成 OCR 功能到各種應用程序中變得更為容易。 除了基本的 OCR 功能外,Tesseract 還支持語言模型和訓練工具,允許用戶根據特定需求訓練自定義模型,以提高某些特定類型或格式文本的識別準確率。這些特性使得 Tesseract 成為了一個強大而靈活的 OCR 工具,廣泛應用于個人和企業的文本數字化處理中。 GitHub地址:https://github.com/tesseract-ocr/tesseract 官方文檔地址:https://tesseract-ocr.github.io ? 下載安裝Tesseract下載Tesseract Home · UB-Mannheim/tesseract Wiki
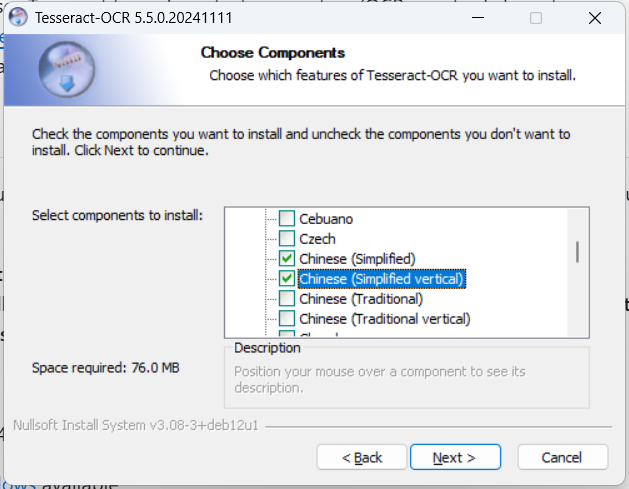
安裝的時候,記得選上中文語言包:
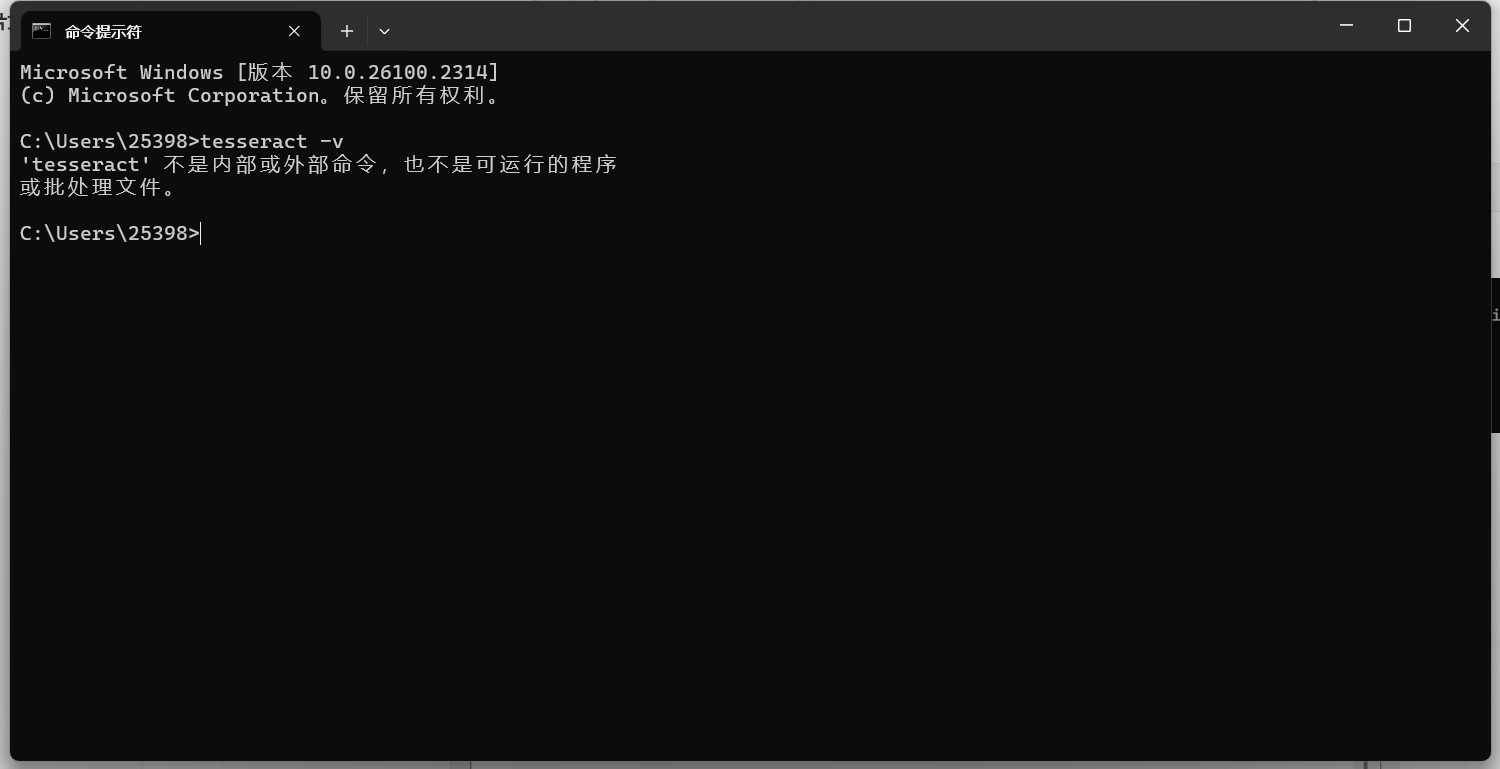
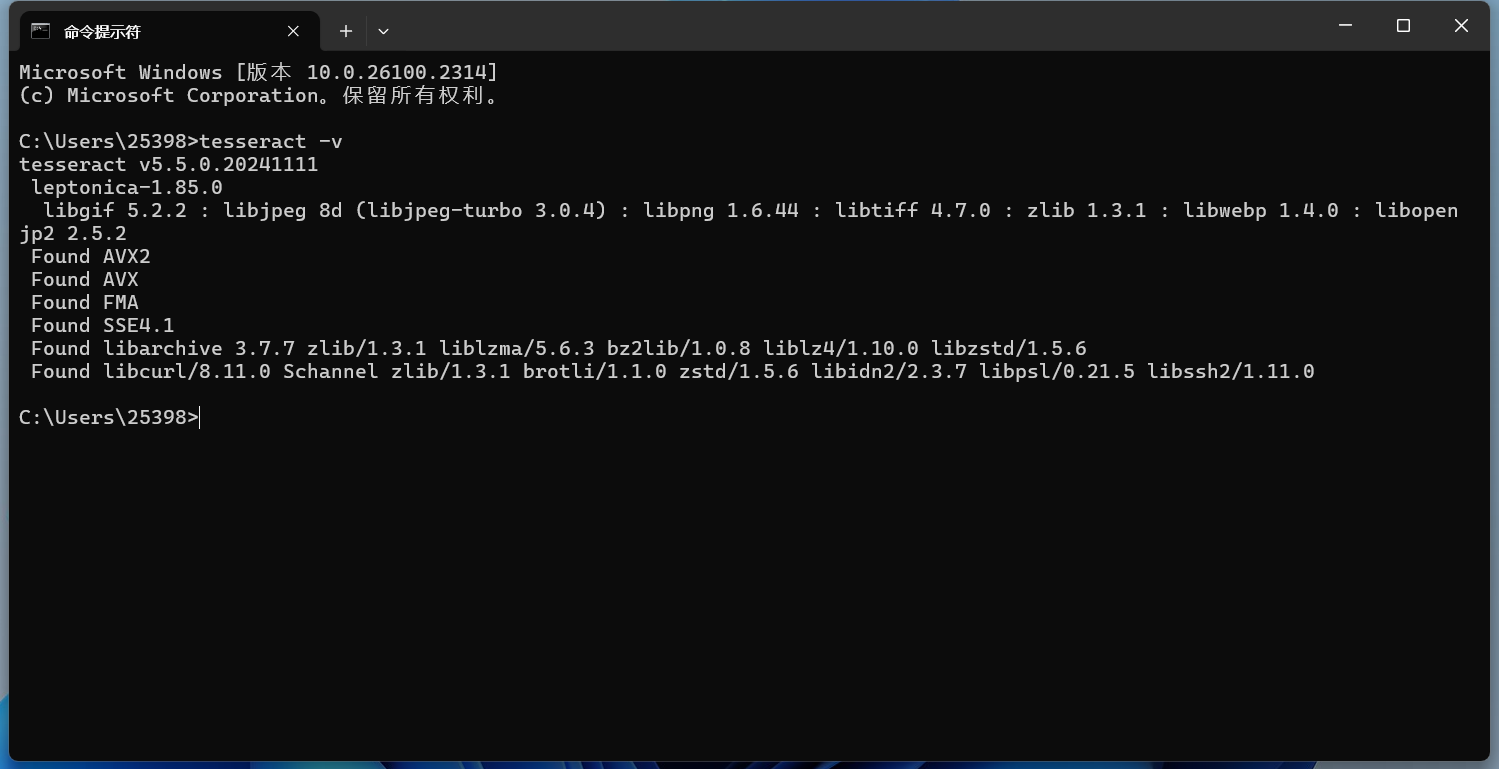
輸入 查看Tesseract是否安裝成功
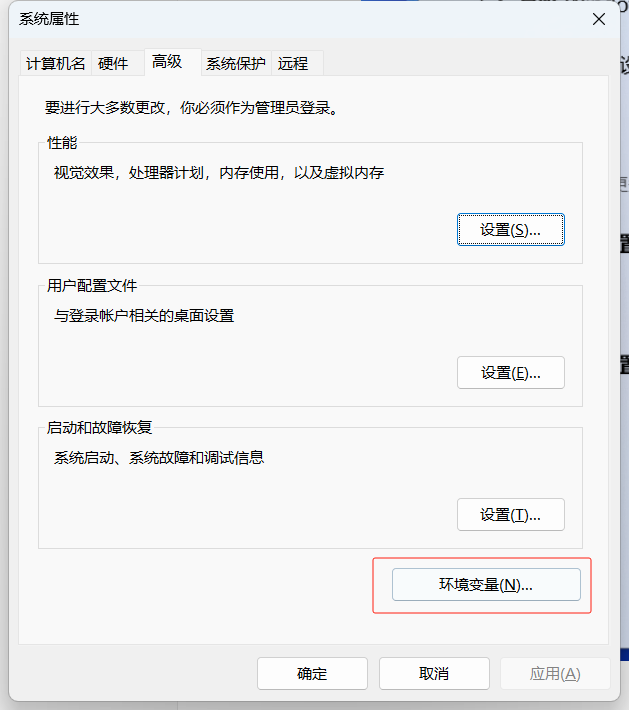
設置環境變量:
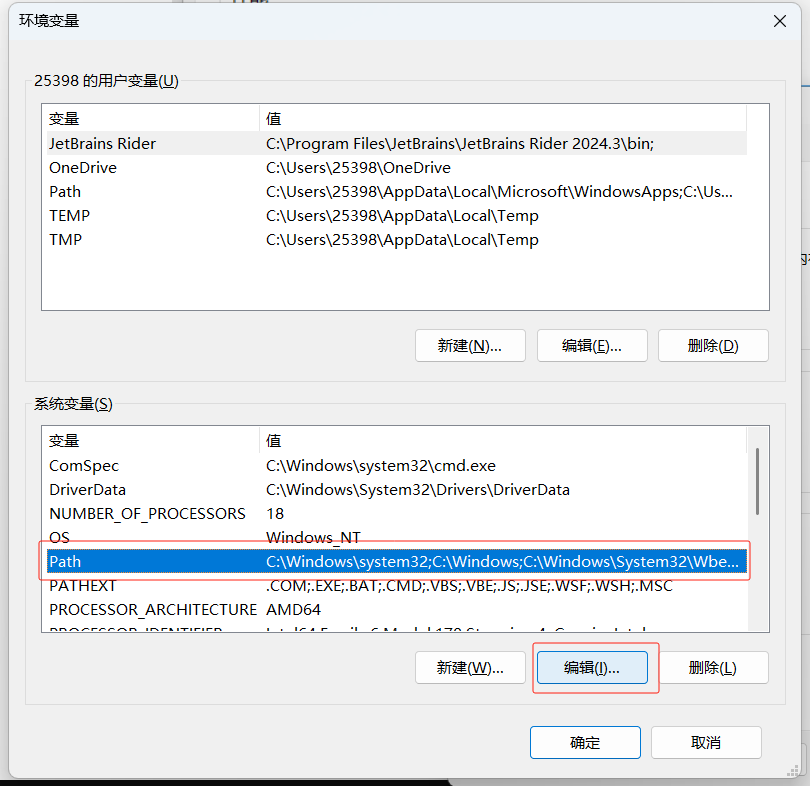
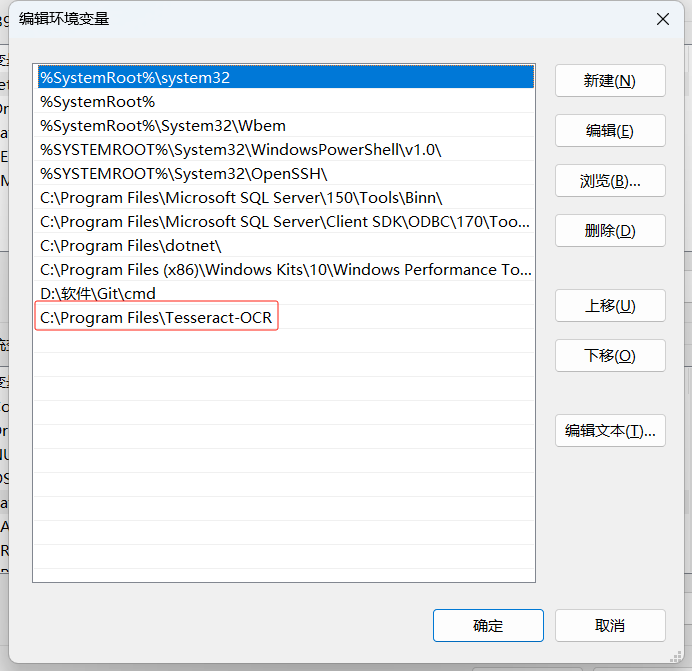
輸入Tesseract的安裝地址:
注意安裝路徑最好不要包含中文,由于C盤空間還比較充足,我就裝在默認位置了。 再次驗證安裝是否完成:
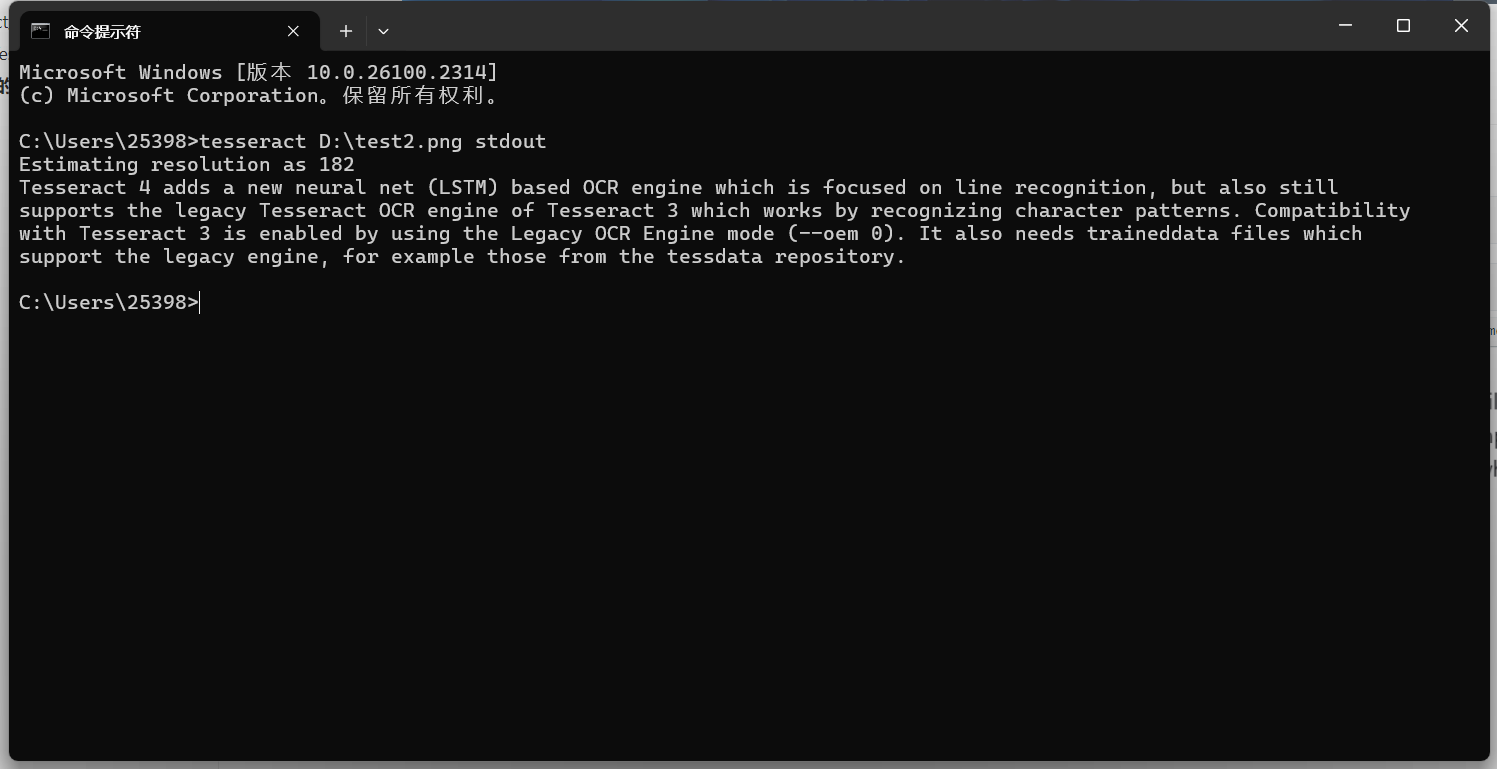
安裝成功完成。 Tesseract的基本命令行使用基本文本識別最簡單的命令是將圖片中的文本識別并輸出到標準輸出(屏幕): 默認識別的是英文的,先拿一個英文的圖片試試:
圖片文字識別的效果
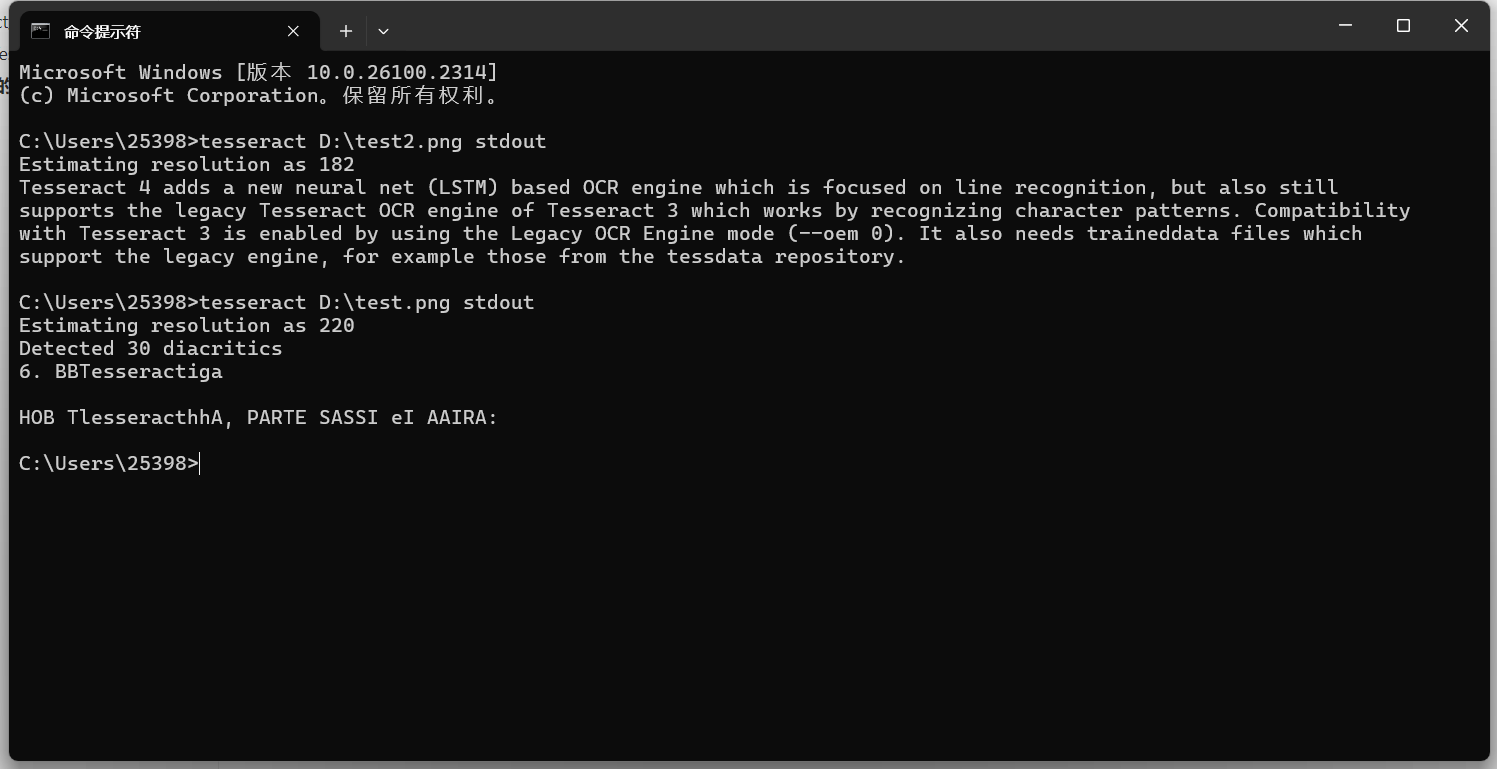
效果還是很ok的。 再試試一個中文的圖片:
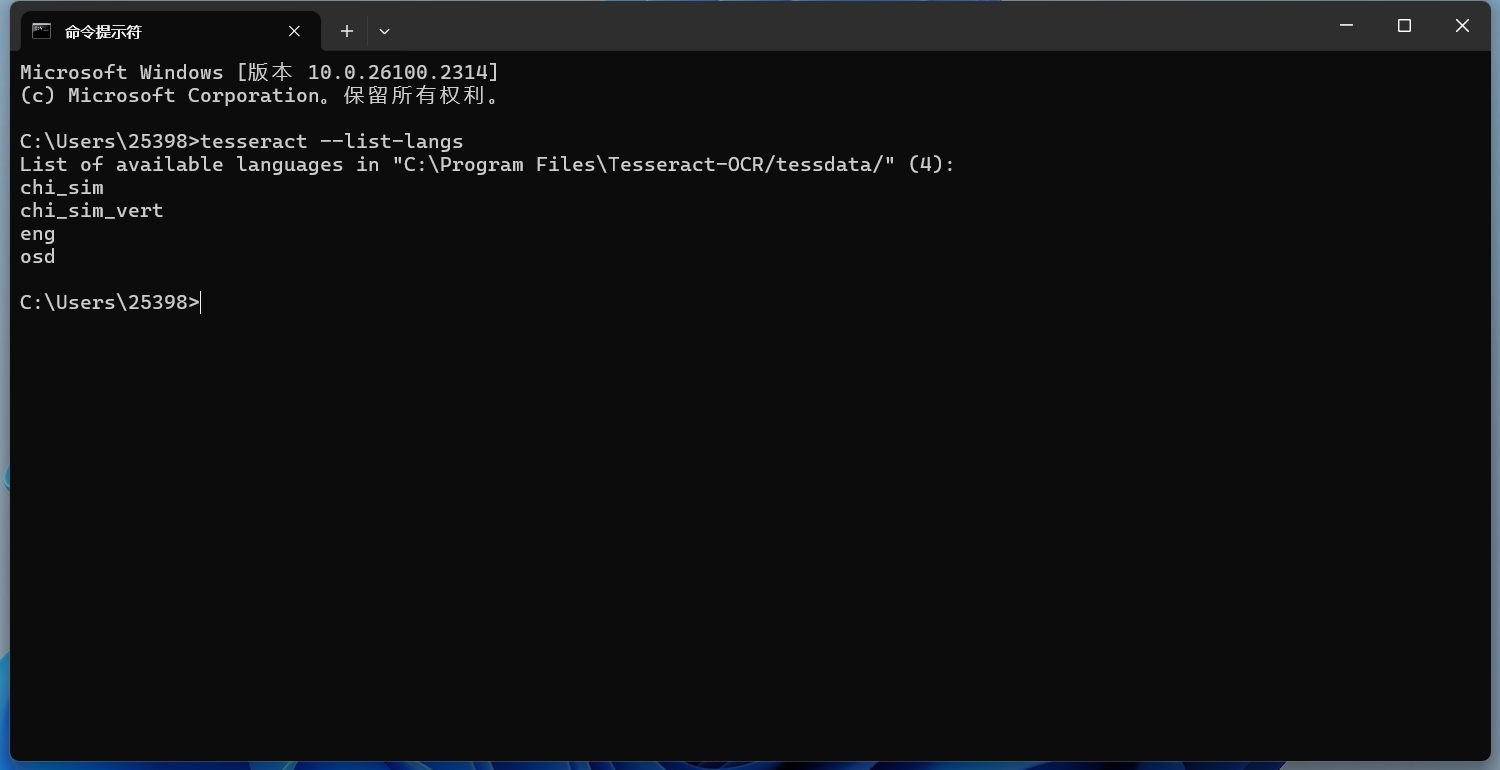
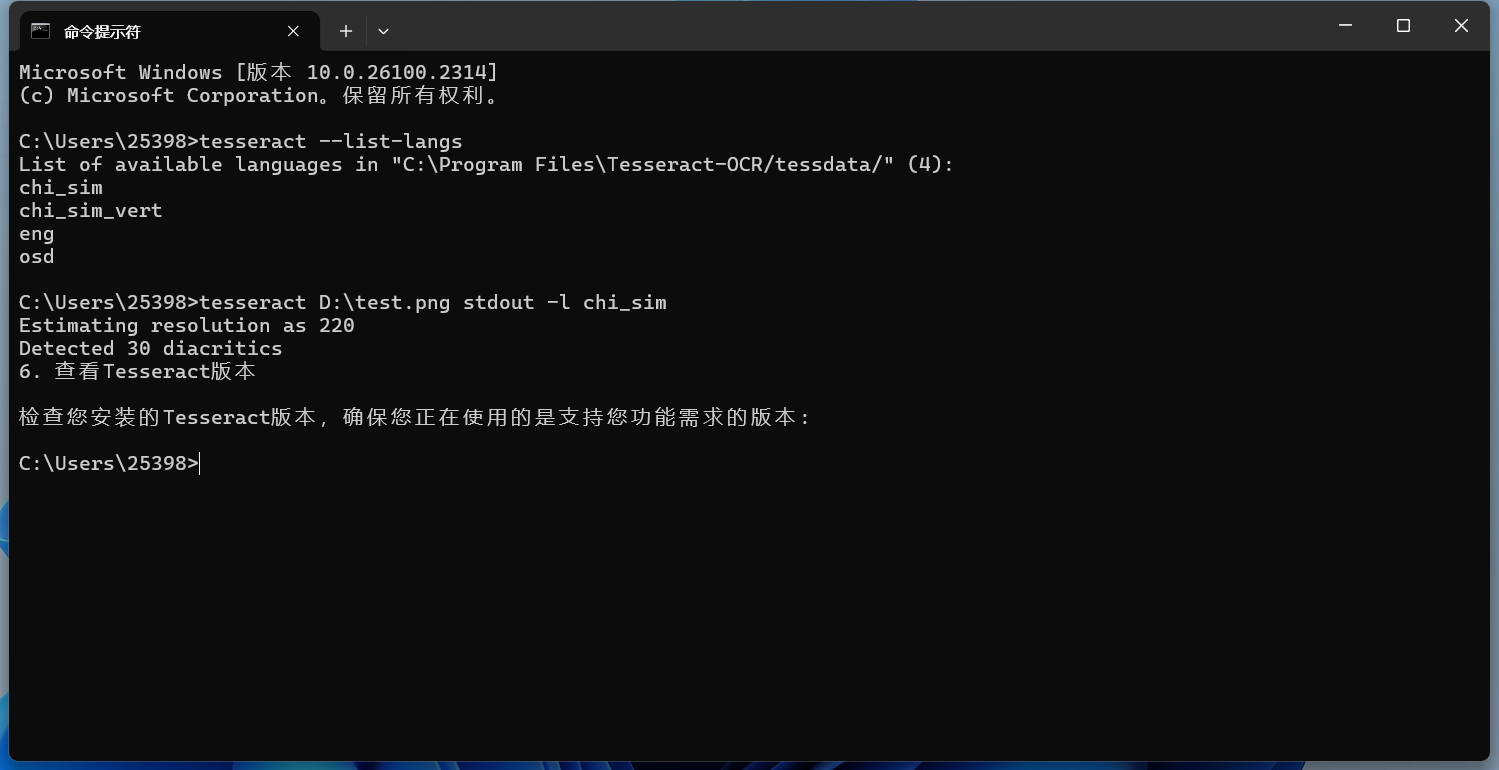
默認是無法識別中文的,這時候需要指定語言才行。 指定一種語言識別如果圖片中的文字不是英文,你需要指定相應的語言。Tesseract 支持多種語言,可以通過以下命令查看支持的語言:
會出現你已經下載了語言包的語言。 指定語言的命令如下(例如,識別中文): 這里的
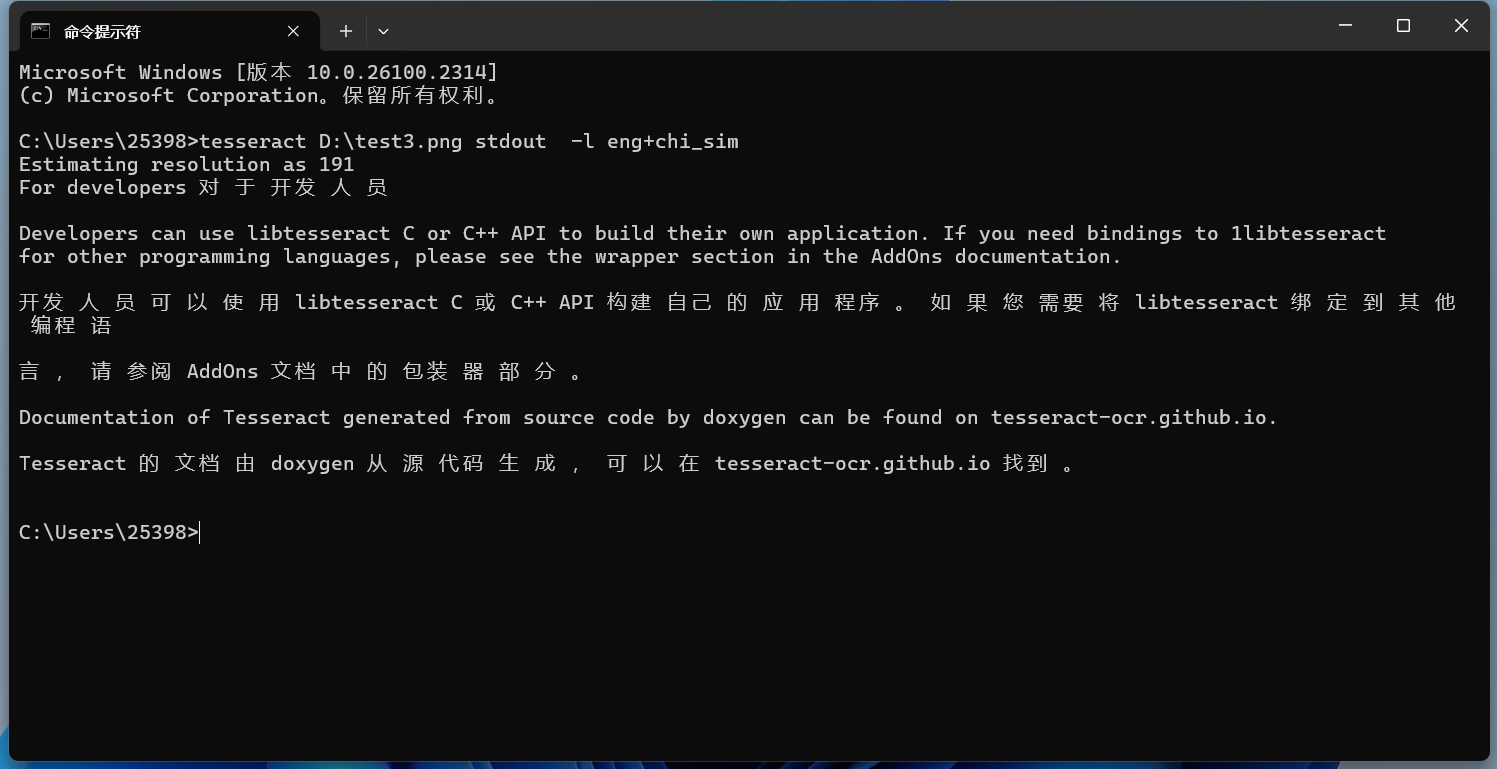
效果也很不錯。 指定多種語言識別有時候我們需要同時識別多種語言,以下面這張圖片為例:
在命令行中添加-l LANG[+LANG]可以使用多種語言進行識別:
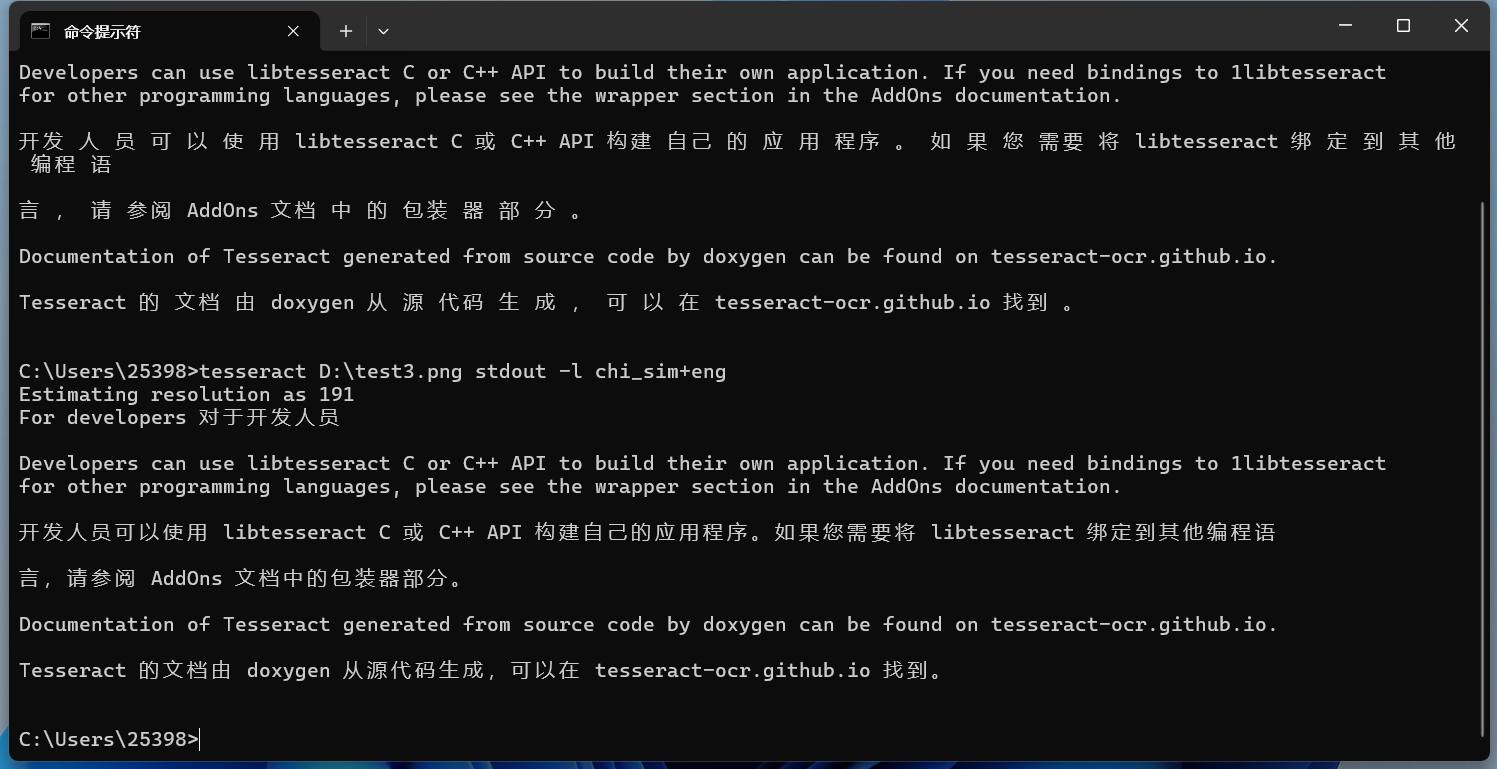
效果也還行。但是會發現識別的中文很多地方都有空格。 將中文改為主要識別語言:
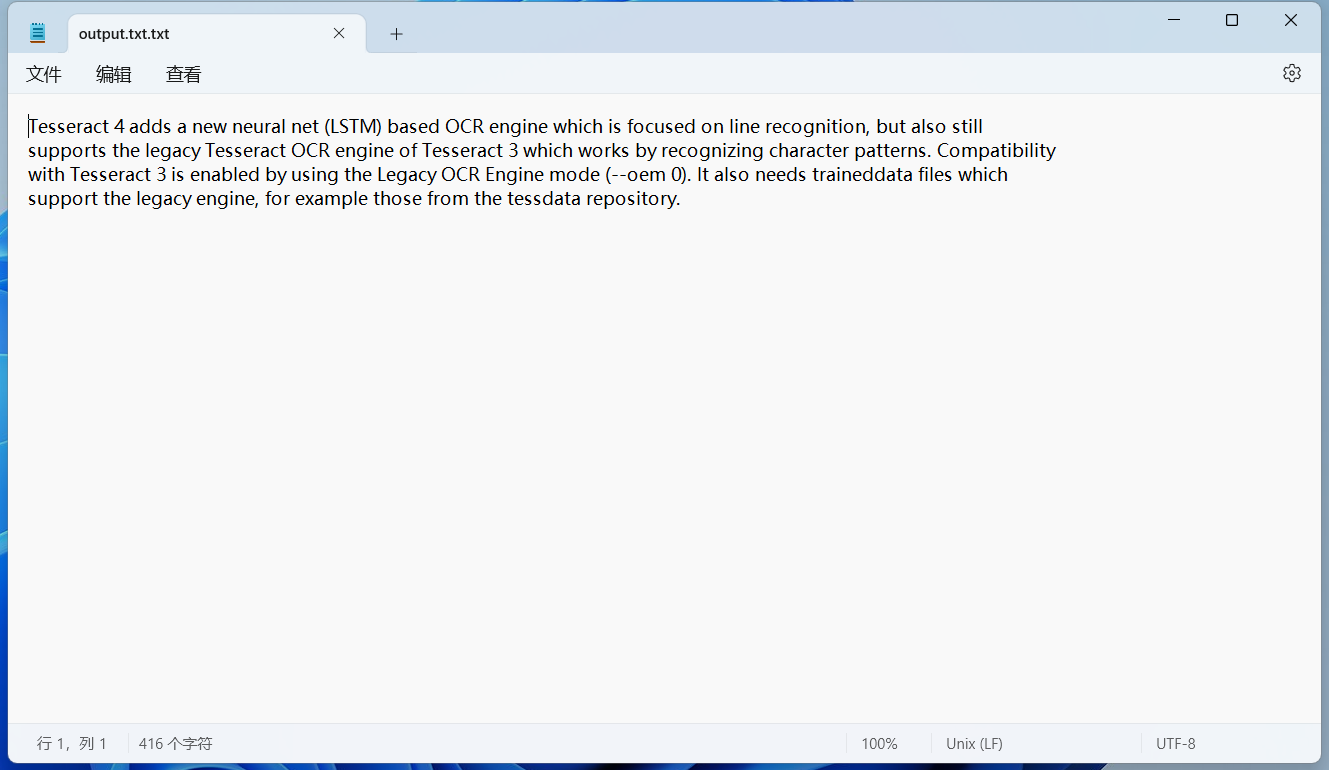
可以發現識別的空格少了很多。 保存識別文本到文件也可以把識別的內容保存在一個txt文件中,命令如下所示:
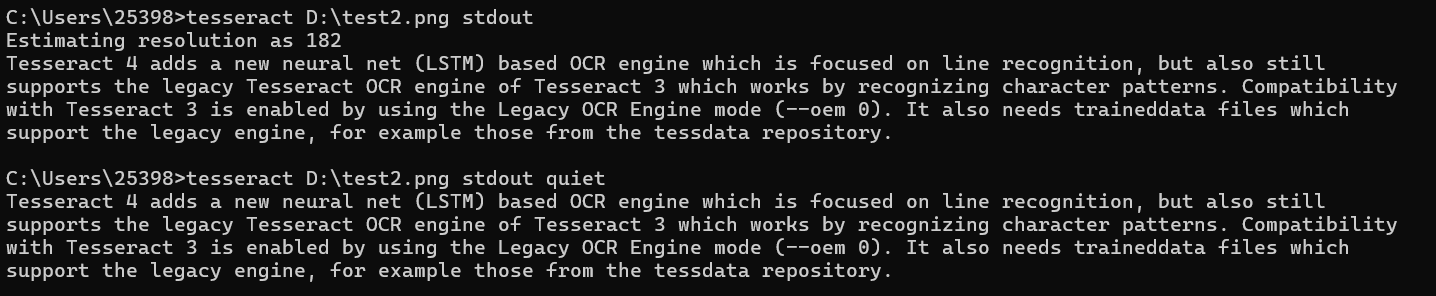
使用quiet模式抑制消息不使用quiet模式與使用quiet模式的對比:
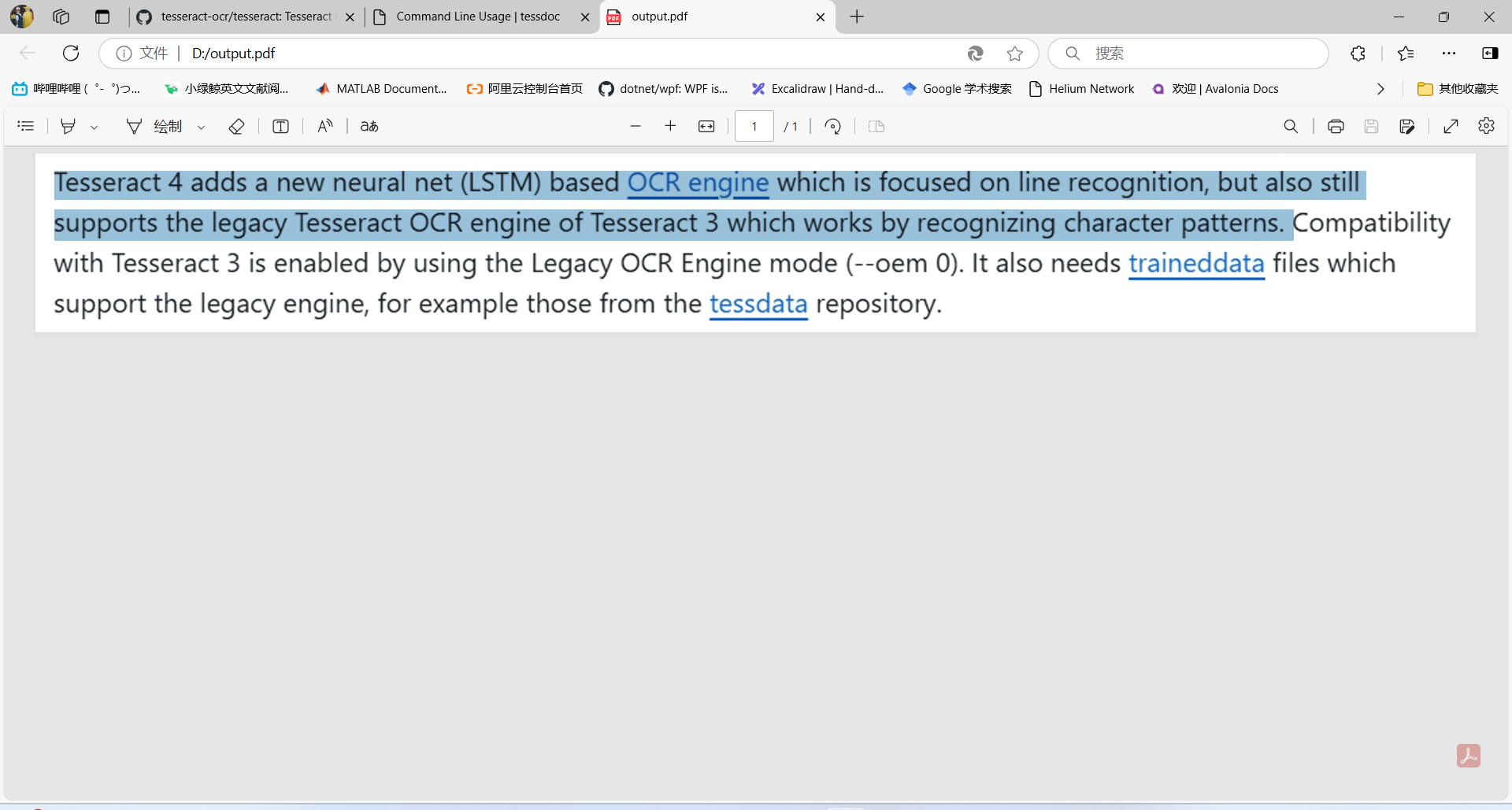
少了表示 Tesseract 正在嘗試估算輸入圖像的分辨率的信息 可搜索的pdf輸出這將創建一個包含圖像和單獨可搜索文本層的PDF,其中包含識別出的文本: 實現效果:
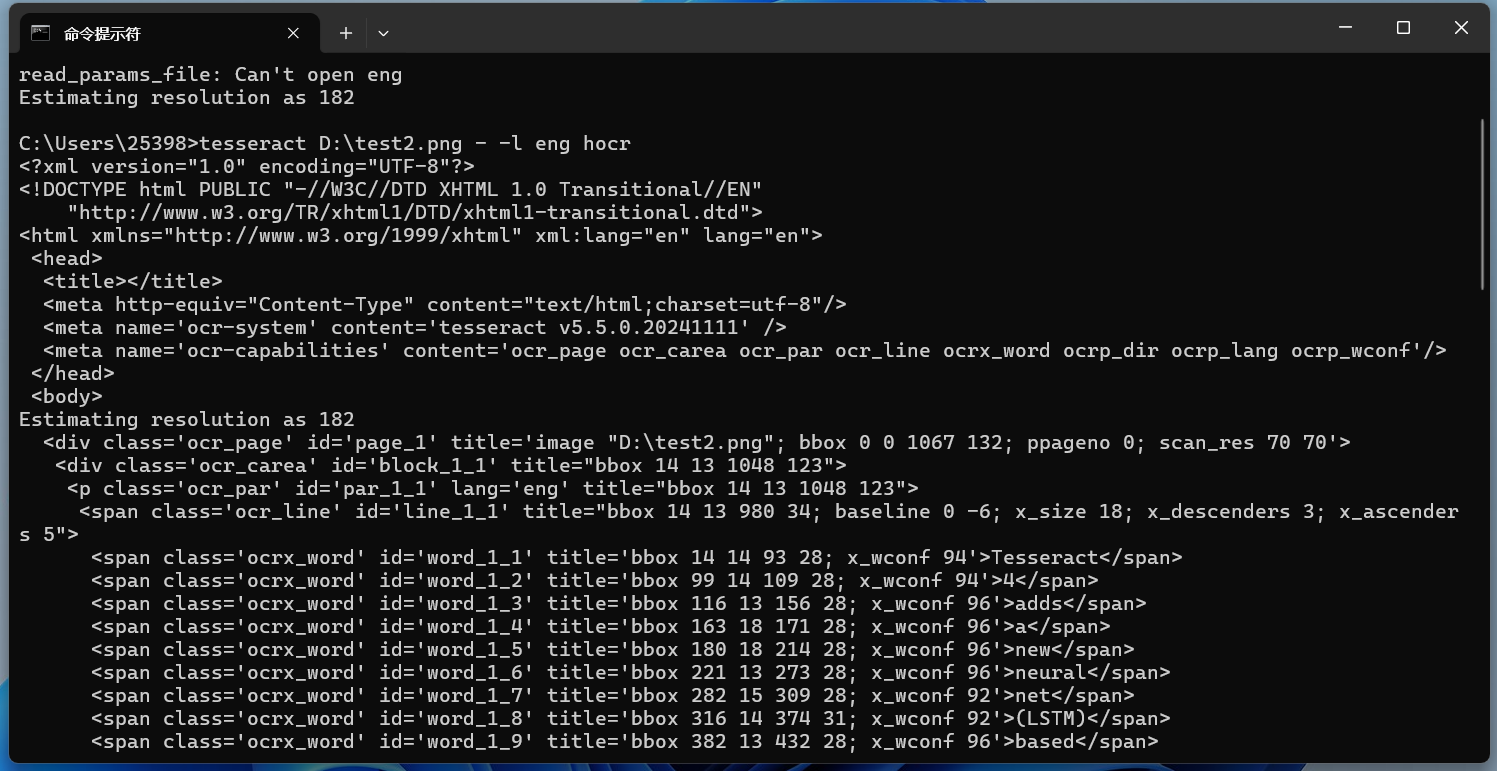
HOCR輸出在命令末尾添加hocr以使用‘hocr’配置文件,獲取HOCR輸出: 識別效果:
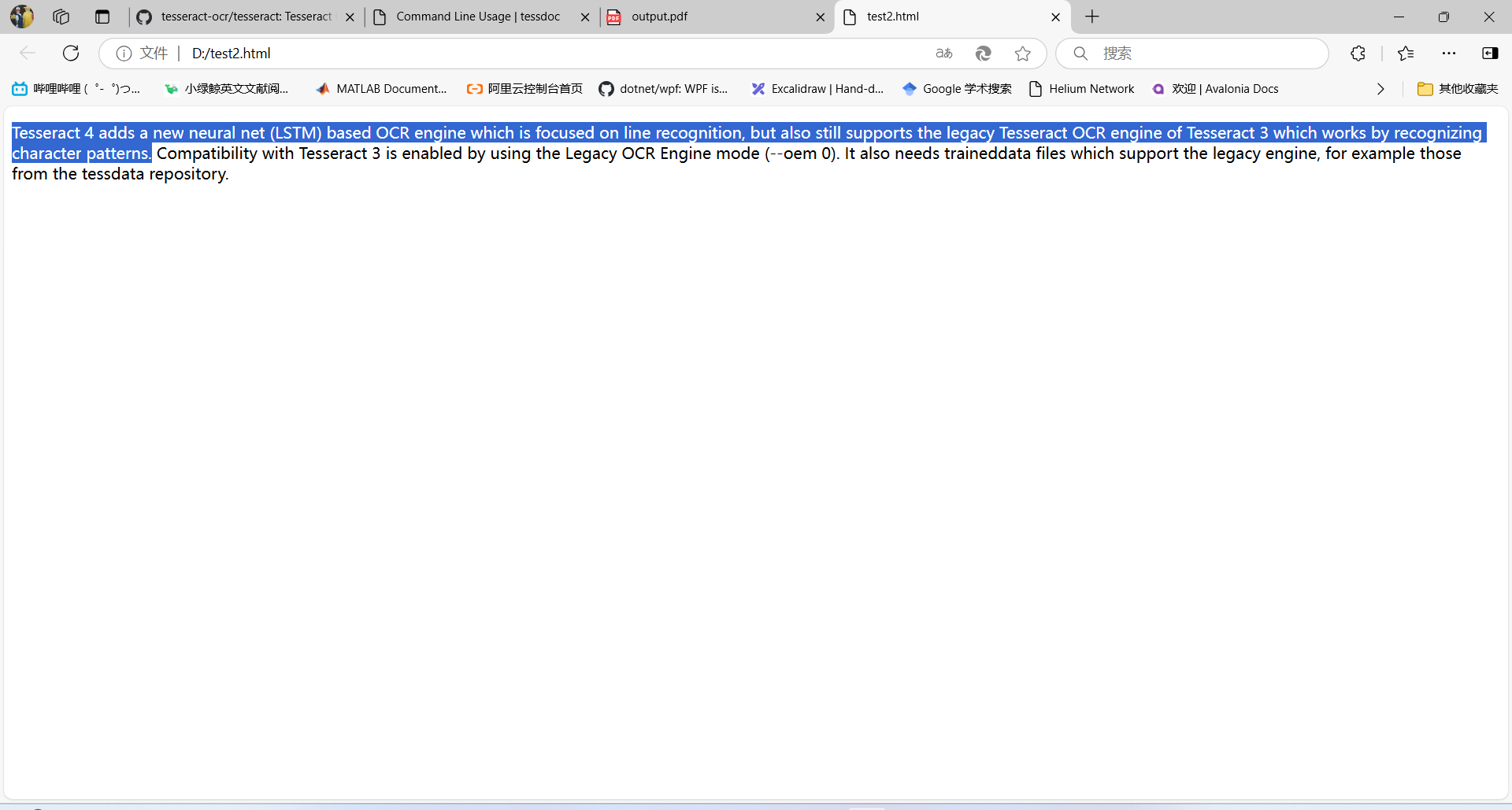
這樣不夠直觀,保存在一個html文件中,然后再打開看看: 把生成的文件后綴改為.html,用瀏覽器打開,效果如下所示:
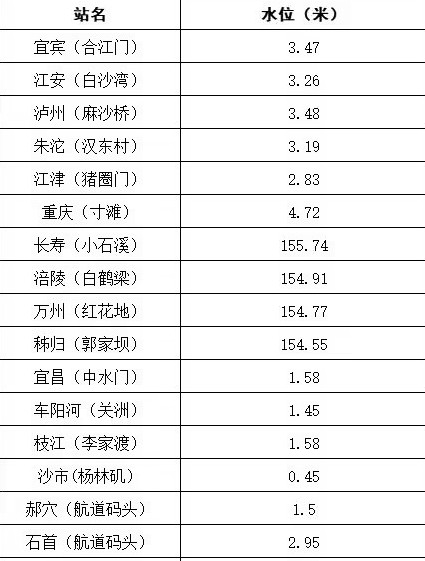
TSV輸出在命令末尾添加“tsv”配置文件以獲取TSV輸出: 以這張圖片為例:
實現效果如下所示:
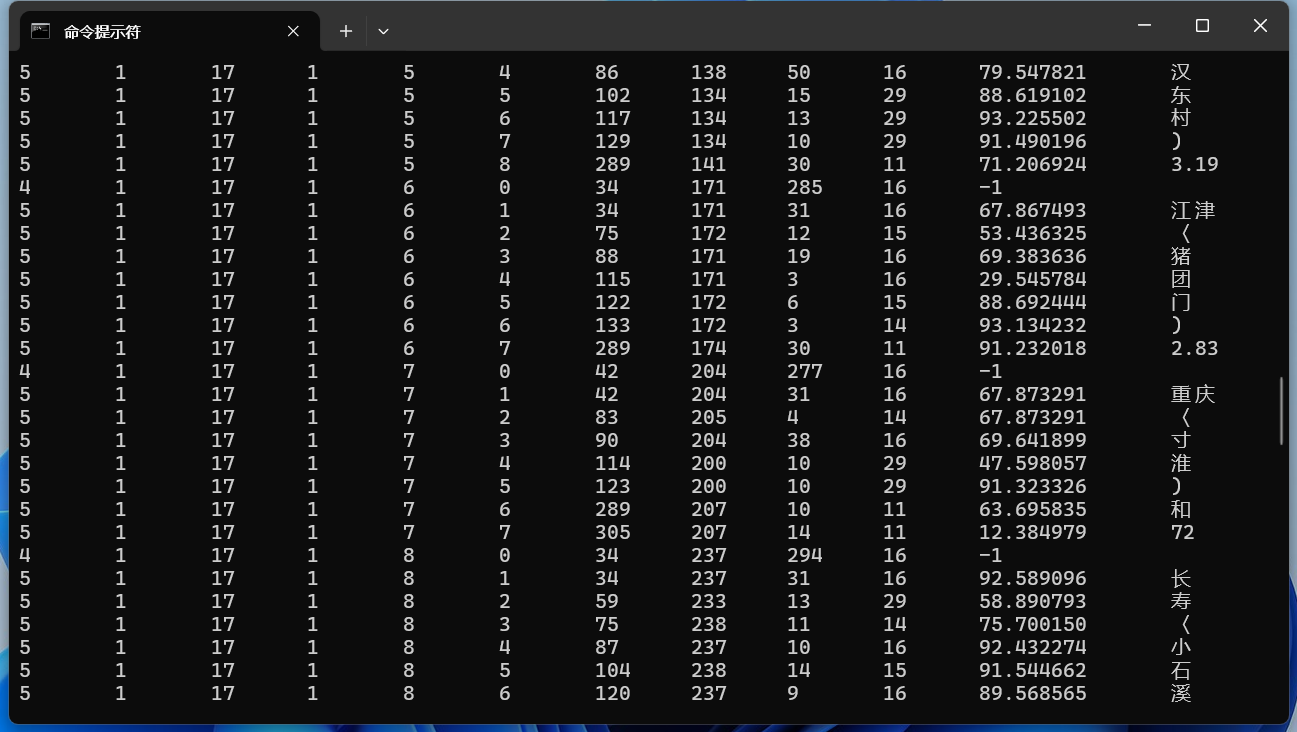
使用不同的頁面分割模式-psm 3 - 全自動頁面分割,但無方向和腳本檢測。(默認) 以這張圖片為例:
實現的效果:
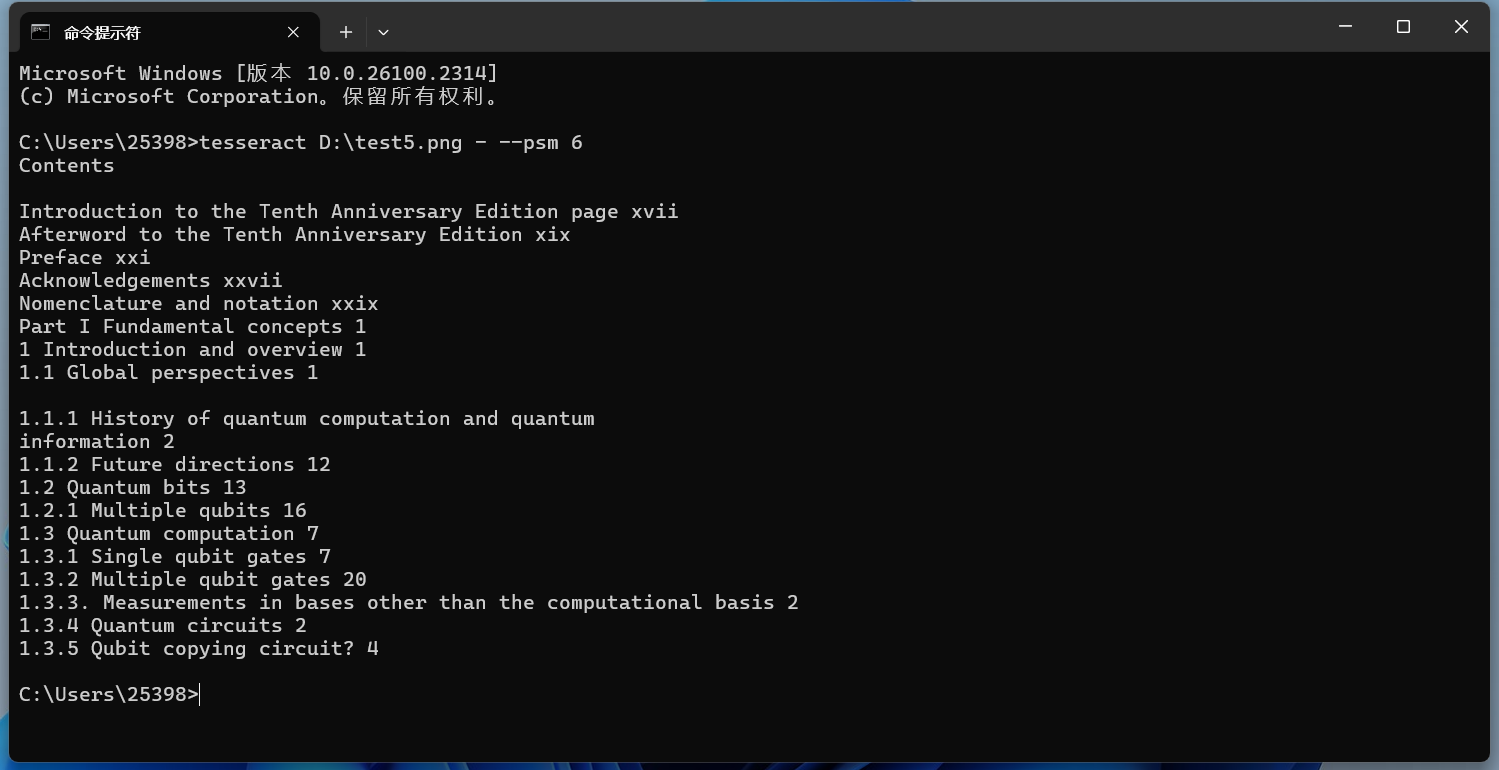
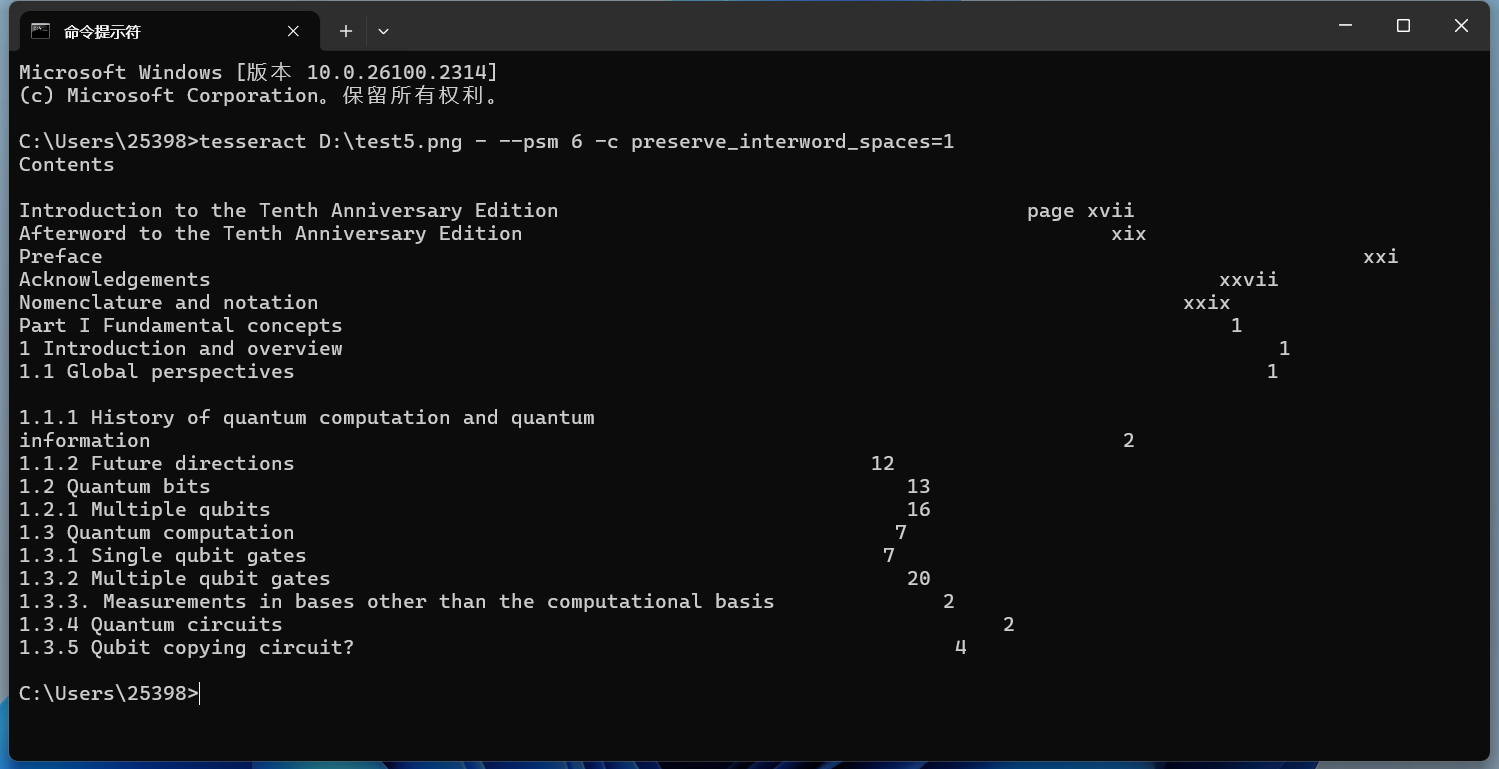
-psm 6 - 假定文本為一個整體均勻的塊。 以這張圖片為例:
實現效果如下所示:
使用 -c preserve_interword_spaces=1 來保留空格 實現效果如下所示:
使用pdftotext保持文本輸出的布局 實現的效果:
總結現在圖片文字識別已經有多種方式可以實現,也可以通過云服務商的文字識別服務,缺點就是需要網絡,數量多了需要收費,優點就是識別準確率比較高。使用Tesseract與PaddleOCR這種方式的好處就是離線可用,速度也挺快的。 轉自https://www.cnblogs.com/mingupupu/p/18590261 該文章在 2024/12/9 9:42:01 編輯過 |
關鍵字查詢
相關文章




|


 400 186 1886
400 186 1886