【SQLServer】如何設(shè)計日增幾十萬數(shù)據(jù)量的業(yè)務(wù)分庫分表方案
當(dāng)前位置:點晴教程→知識管理交流
→『 技術(shù)文檔交流 』
隨著公司的業(yè)務(wù)發(fā)展不斷的壯大,像一些核心的業(yè)務(wù)(如訂單)數(shù)據(jù)量會越來越大,此時就需要考慮分庫分表方案來應(yīng)對業(yè)務(wù)的發(fā)展。今天就來聊聊分庫分表的一些設(shè)計方案。 1、冷熱數(shù)據(jù)分離方案 在我們業(yè)務(wù)中有些數(shù)據(jù)只是最近一段時間使用比較頻繁,過著這段時間就基本上不用了,如龍蝦之前負(fù)責(zé)的物流系統(tǒng)中的物流軌跡數(shù)據(jù),一條物流單號對應(yīng)著若干條物流軌跡數(shù)據(jù),如下所示的物流軌跡:
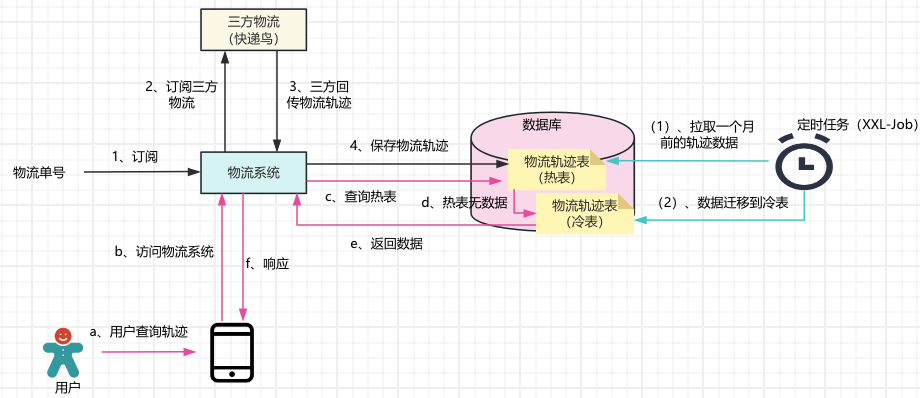
一個物流單號(如YT20241234569)對應(yīng)的軌跡有6條數(shù)據(jù)數(shù)據(jù)了,假設(shè)一天的訂單量有2萬單,此時至少有12萬條物流軌跡產(chǎn)生, 日復(fù)一日的數(shù)據(jù)量積累,那么物流軌跡表的數(shù)據(jù)也是非常的龐大的。 從業(yè)務(wù)角度分析,按照用戶的習(xí)慣來講,某個訂單待收貨與交易成功之間的這段時間中我們是比較關(guān)心物流的軌跡的,一旦收到貨之后基本很少再去看這單的物流軌跡信息,所以針對這種數(shù)據(jù)量大(物流軌跡數(shù)據(jù))、只在某段時間內(nèi)頻繁關(guān)心的數(shù)據(jù),我們可以使用冷熱數(shù)據(jù)隔離的方案來解決數(shù)據(jù)量大的問題。下圖使用物流軌跡數(shù)據(jù)冷熱分離方案為案例分析:
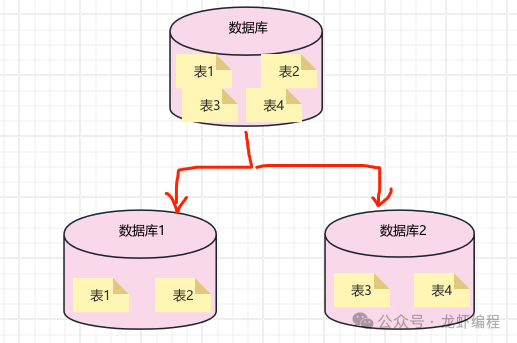
(1)物流單號訂閱物流系統(tǒng),物流系統(tǒng)將物流單號訂閱三方快遞,一旦訂閱成功之后,三方快遞收到物流軌跡變動就會推送給物流系統(tǒng),然后物流系統(tǒng)將數(shù)據(jù)存放到熱表中; (2)用戶查詢的時候優(yōu)先從熱表先查詢數(shù)據(jù),如果熱表有物流軌跡的數(shù)據(jù)就直接返回數(shù)據(jù)給用戶;如果熱表中不存在物流數(shù)據(jù),那么再去冷表中查詢數(shù)據(jù),將冷表的查詢結(jié)果給用戶; (3)每天夜里(如凌晨兩點)采用定時任務(wù)將一個月之前的數(shù)據(jù)都遷移到冷表中,這樣可以保持熱表中都是最近的數(shù)據(jù)。 至此就完成了一套使用通過冷熱分離的方案實現(xiàn)對日增幾十萬條業(yè)務(wù)數(shù)據(jù)的處理。 2、分庫分表方案 公司現(xiàn)有的業(yè)務(wù)體量非常大的,在讀寫分離、主從架構(gòu)都無法滿足現(xiàn)有的業(yè)務(wù)的時候,我們就可以考慮分庫分表,為什么不優(yōu)先考慮分庫分表方案呢?因為業(yè)務(wù)數(shù)據(jù)越分散,開發(fā)和維護(hù)成本就越高,并且系統(tǒng)的不穩(wěn)定性又多一些威脅因素。 分庫分表是應(yīng)對業(yè)務(wù)數(shù)據(jù)量大、高并發(fā)的重要手段之一,我們要搞清楚何時分庫,何時分表,何時既分庫也分表呢? (a)分庫的場景:在高并發(fā)下,數(shù)據(jù)庫的連接不夠用的時候,此時可以通過增加數(shù)據(jù)庫的實例來增加數(shù)據(jù)庫的連接數(shù)。如下所示的分庫方式:
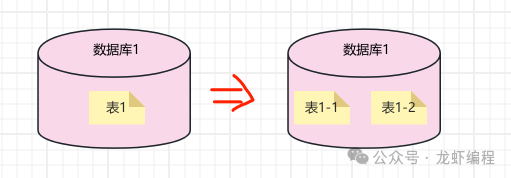
(b)分表的場景:如果單表的數(shù)據(jù)量很龐大,此時數(shù)據(jù)庫的連接是夠用的,但是存儲和查詢的性能已經(jīng)成為業(yè)務(wù)瓶頸,那么就考慮分表。如下圖所示的分片:
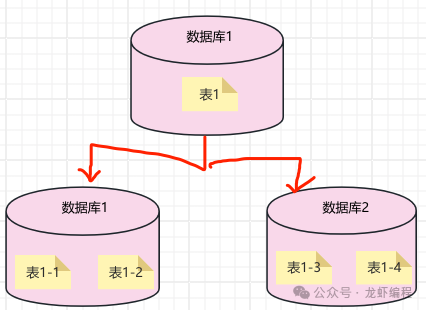
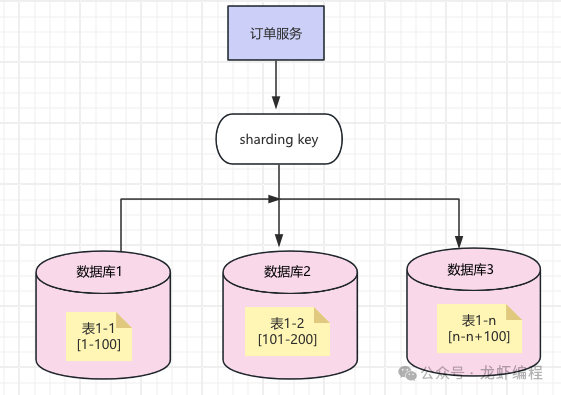
(c)既分庫也分表的場景:數(shù)據(jù)庫的連接不夠,并且表數(shù)據(jù)量很龐大此時一般需要考慮既要分庫也要分表。但是具體分多少庫分多少表實際的業(yè)務(wù)預(yù)估數(shù)據(jù)量來做決定,如下圖所示的既分庫也分表的圖:
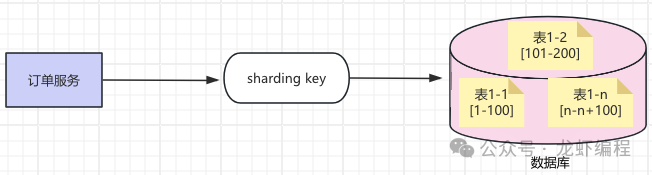
在確定了需要分庫分表后就需要考慮將數(shù)據(jù)分到哪個庫或者哪張表中,下面介紹4種主流的切分: (1)Range法 此算法是按照某個字段(如訂單id、用戶id)的數(shù)據(jù)區(qū)間來進(jìn)行切分的,可以將數(shù)據(jù)切分到同一個數(shù)據(jù)庫的不同表中,如下所示:
也可以將數(shù)據(jù)切分到不同庫的不同表中,如下所示:
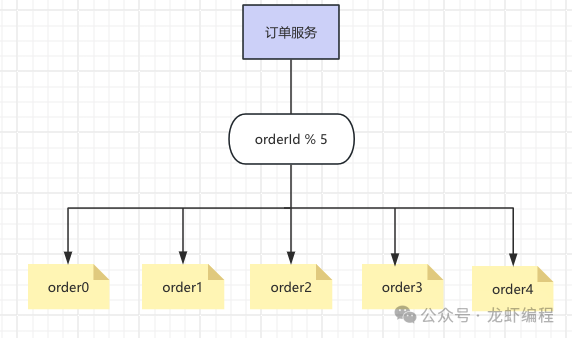
Range算法對于需要擴(kuò)容來說是非常的友好的,因為只需要添加一張數(shù)據(jù)表,通過算法就可以自動實現(xiàn)擴(kuò)容機(jī)制。同時Range算法也存在寫偏移和熱點數(shù)據(jù)問題。 (2)hash分片算法 該方案是通過對分表鍵key進(jìn)行某種運算(如取模運算),然后通過運算結(jié)果來決定路由的庫和表,如下圖所示:
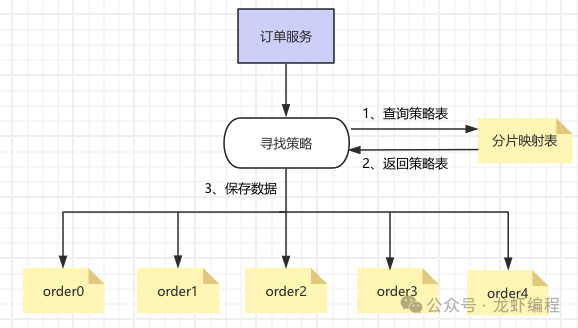
hash分片方案可以使得數(shù)據(jù)分片比較均勻,大大降低數(shù)據(jù)傾斜和熱點數(shù)據(jù)的問題; hash分片方案的缺點也很明顯,如后期擴(kuò)容存在一定的難度,需要遷移數(shù)據(jù);數(shù)據(jù)被切分到不同的庫和表中,存在查詢和分頁等問題; (3)查表映射法 此方案的實現(xiàn)原理是將決定某個sharding key落在哪個分片上靠人為的預(yù)先制定的策略(策略記錄在數(shù)據(jù)表中)來分配,如下所示的分配流程:
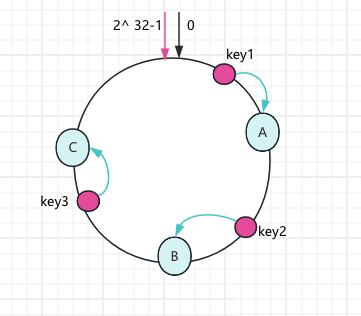
查表映射法可以靈活設(shè)置路由規(guī)則,但是要求映射表本身的數(shù)據(jù)不能太多,否則映射表反而成為性能瓶頸了。 查表映射法相對其他兩種分片算法來說,它需要二次查詢、實現(xiàn)上也更加的復(fù)雜一些。 (4)一致性hash 一致性hash可以按照普通的hash算法對key哈希到一個圓環(huán)空間上,形成一個順時針的首位閉合的環(huán)形,如下圖所示:
此時key1順時針放在節(jié)點A上,同理key放在B節(jié)點上,如果A、B、C節(jié)點假設(shè)分布不均勻,我們可以使用虛擬節(jié)點的方案來處理,之前龍蝦也介紹過一致性hash,有興趣的朋友可以在看下: 3、分庫分表帶來的問題 (1)分布式id 單庫單表的時代,我們可以直接使用表自增主鍵保證全局唯一,分庫分表后,需要自己維護(hù)全局唯一的ID。生成全局唯一id的方案如下整理: (2)分布式事務(wù) 分庫分表之后可能就需要引入分布式事務(wù)的問題,解決方案如下整理: (3)分頁查詢問題 單庫單表的時候我們可以使用數(shù)據(jù)的limit來進(jìn)行分頁查詢,但是分庫分表后就出現(xiàn)分頁查詢的問題了,常見的處理方案如下: (a)使用Elasticsearch; (b)特定的條件先分頁查詢;按照某個字段先分頁查詢數(shù)據(jù),查詢好之后再去查詢組裝其他的數(shù)據(jù)。 該文章在 2024/7/22 9:30:56 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
")